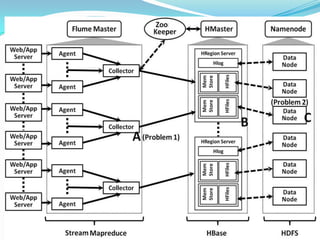
- The document discusses using Flume and HBase for real-time analytics of streaming big data with service level agreements (SLAs).
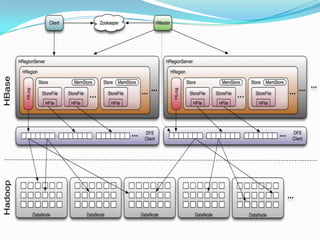
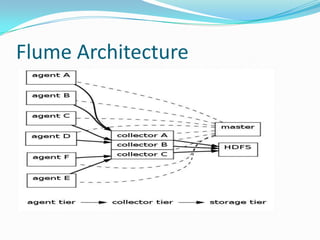
- Flume is used to ingest streaming data into HBase for storage and querying. HBase's column families allow storing different types of data with different time to live settings.
- Maintaining SLAs for bucketing millions of product impressions within seconds across many nodes is challenging due to the complexity of the systems involved.
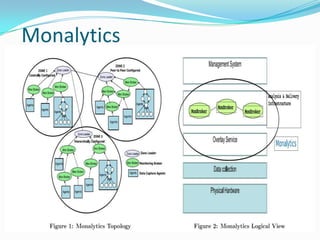
- Monalytics can help monitor end-to-end performance and identify issues in meeting SLAs, like garbage collection pauses, across the distributed Flume and HBase deployment.










![HBase TTLDESCRIPTION ENABLED {NAME => 'test', FAMILIES => [{NAME => 'host', BLOOMFILTER => 'NONE', REPLICATION_SCOPE => '0', COMPRESSION => 'NONE', VERSIONS => '3', TTL => '2147483647', BLOCKSIZE => '65536', IN_MEMORY => 'false', BLOCKCACHE => 'true'}, {NAME => ' info', BLOOMFILTER => 'NONE', REPLICATION_SCOPE => '0', COMPRESSION => 'NONE', VERSIONS => '3', TTL => '2147483647', BLOCKSIZE => '65536', IN_MEMORY => 'fal se', BLOCKCACHE => 'true'}, {NAME => 'log', BLOOMFILTER => 'NONE', REPLICATION _SCOPE => '0', VERSIONS => '3', COMPRESSION => 'NONE', TTL => '2147483647', BL OCKSIZE => '65536', IN_MEMORY => 'false', BLOCKCACHE => 'true'}, {NAME => 'pro duct', BLOOMFILTER => 'NONE', REPLICATION_SCOPE => '0', COMPRESSION => 'NONE', VERSIONS => '3', TTL => '10', BLOCKSIZE => '65536', IN_MEMORY => 'false', BLOCKCACHE => 'true'}]}](https://image.slidesharecdn.com/streamingmap-reduce-110504110057-phpapp02/85/Streaming-map-reduce-11-320.jpg)




![Flume – HBase connectorThis is challenging since we need to interface single dimensional key-value pairs into multi-dimensional key-value pairMany possible approaches:1. "usage: hbase(\"table\", \"rowkey\", " + "\"cf1\"," + " \"c1\", \"val1\"[,\"cf2\", \"c2\", \"val2\", ....]{, " + KW_BUFFER_SIZE + "=int, " + KW_USE_WAL + "=true|false})";2. usage: attr2hbase(\"table\" [,\"sysFamily\"[, \"writeBody\"[,\"attrPrefix\"[,\"writeBufferSize\"[,\"writeToWal\"]]]]])";https://issues.cloudera.org/browse/FLUME-6](https://image.slidesharecdn.com/streamingmap-reduce-110504110057-phpapp02/85/Streaming-map-reduce-18-320.jpg)