Downloaded 61 times





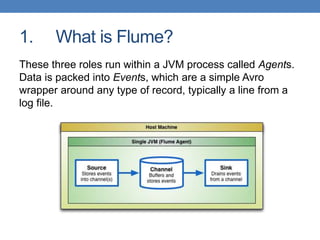
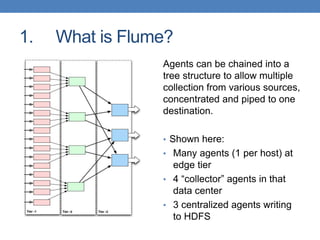



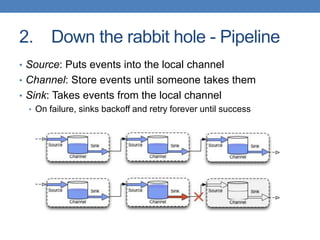



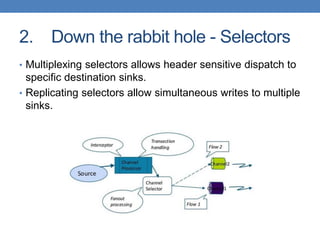




Apache Flume is a fault-tolerant, scalable data collection and aggregation framework that operates in distributed topologies, characterized by its simple pipeline structure consisting of sources, channels, and sinks. It supports various sources such as HTTP and Kafka, and allows for configurations to manipulate data through interceptors. Flume is useful for log aggregation, continuous writing to HDFS, and automated data ingestion, though it is not designed for complex stream processing.












































































