Downloaded 1,217 times










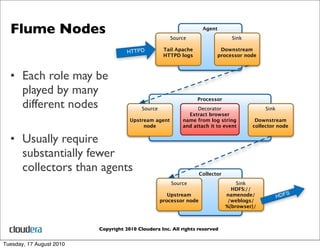








Henry Robinson works at Cloudera on distributed data collection tools like Flume and ZooKeeper. Cloudera provides support for Hadoop and open source projects like Flume. Flume is a scalable and configurable system for collecting large amounts of log and event data into Hadoop from diverse sources. It allows defining flexible data flows that can reliably move data between collection agents and storage systems.























































































