Downloaded 21 times







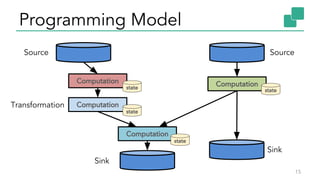
![API and Execution
16
Source
DataStream<String> lines = env.addSource(new FlinkKafkaConsumer010(…));
DataStream<Event> events = lines.map(line -> parse(line));
DataStream<Statistic> stats = events
.keyBy("id")
.timeWindow(Time.seconds(5))
.aggregate(new MyAggregationFunction());
stats.addSink(new BucketingSink(path));
map()
[1]
keyBy()/
window()/
apply()
[1]
Transformation
Transformation
Sink
Streaming
DataflowkeyBy()/
window()/
apply()
[2]
map()
[1]
map()
[2]
Source
[1]
Source
[2]
Sink
[1]](https://image.slidesharecdn.com/piotrnowojski-180323120007/85/Apache-Flink-Better-Faster-Uncut-Piotr-Nowojski-data-Artisans-16-320.jpg)
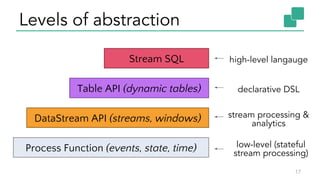


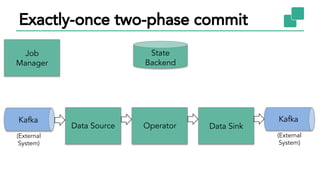
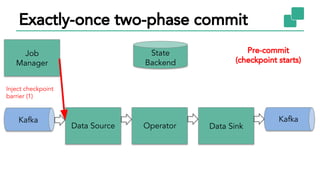
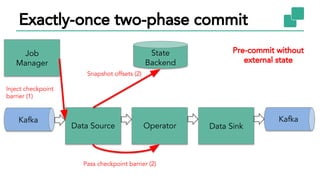
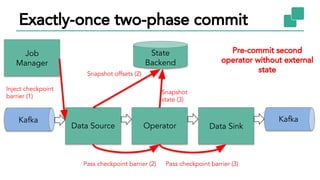
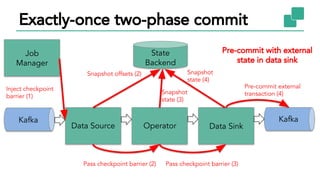
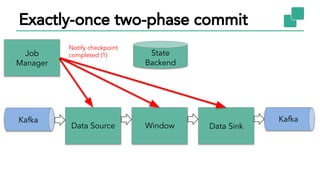
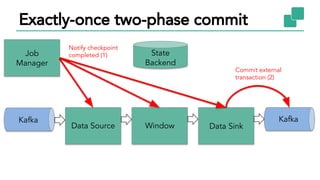



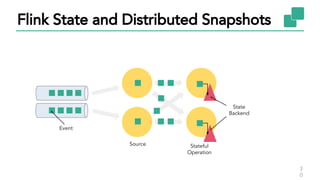
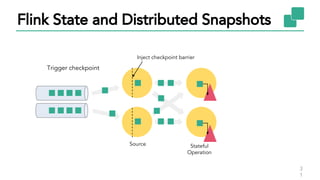
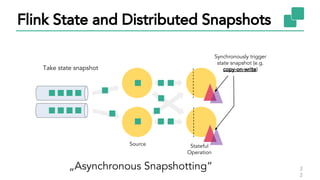
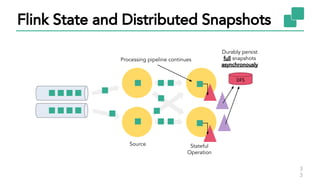


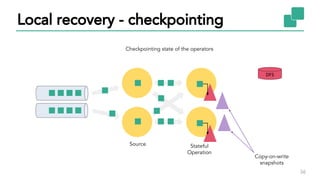
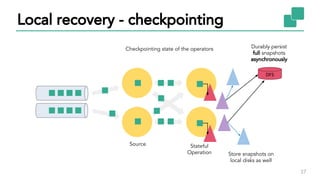
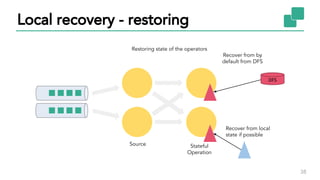









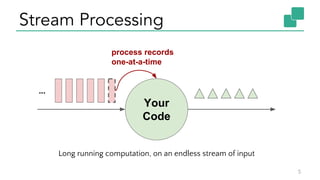
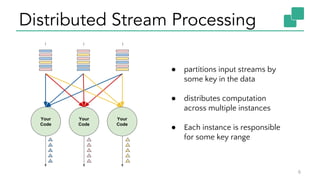
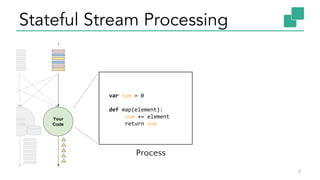
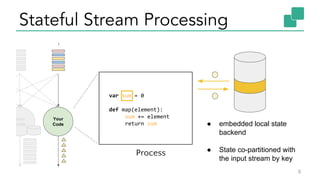
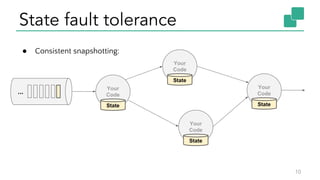
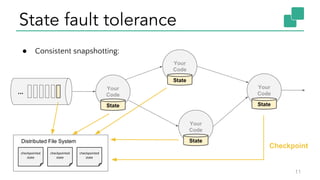
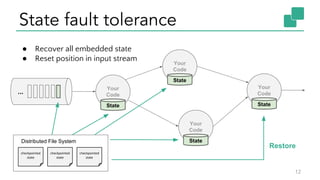
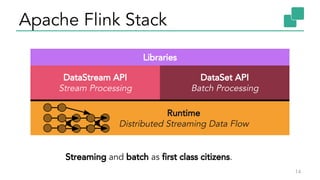
The document discusses Apache Flink, a stateful stream processing framework, highlighting its capabilities for handling continuous data streams and fault tolerance. It covers the architecture, including the DataStream API and the ability to consistently snapshot state for fault tolerance. Recent updates since version 1.4 include improved support for exactly-once semantics and enhancements for managing large states efficiently.























































































