



![Topology: Connecting agents together
[Client]+ Agent [ Agent]* Destination
5](https://image.slidesharecdn.com/flumehug-130222080250-phpapp02/85/Feb-2013-HUG-Large-Scale-Data-Ingest-Using-Apache-Flume-5-320.jpg)
















![HTTP Source, cont’d.
• Default handler supports events that look like this:
[{
"headers" : {
"timestamp" : "434324343",
"host" : ”host1.example.com"
},
"body" : ”arbitrary data in body string"
},
{
"headers" : {
"namenode" : ”nn01.example.com",
"datanode" : ”dn102.example.com"
},
"body" : ”some other arbitrary data in body string"
}]
24](https://image.slidesharecdn.com/flumehug-130222080250-phpapp02/85/Feb-2013-HUG-Large-Scale-Data-Ingest-Using-Apache-Flume-24-320.jpg)




























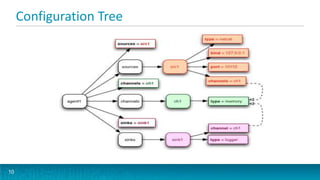
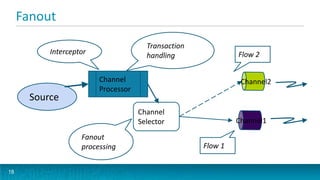
This document provides an overview of large scale data ingestion using Apache Flume. It discusses why event streaming with Flume is useful, including its scalability, event routing capabilities, and declarative configuration. It also covers Flume concepts like sources, channels, sinks, and how they connect agents together reliably in a topology. The document dives into specific source, channel, and sink types including examples and configuration details. It also discusses interceptors, channel selectors, sink processors, and ways to integrate Flume into applications using client SDKs and embedded agents.





















































![Complex Er[jl]ang Processing with StreamBase](https://cdn.slidesharecdn.com/ss_thumbnails/complexerjlangprocessing-pptx-110611095407-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)





















































