Download to read offline

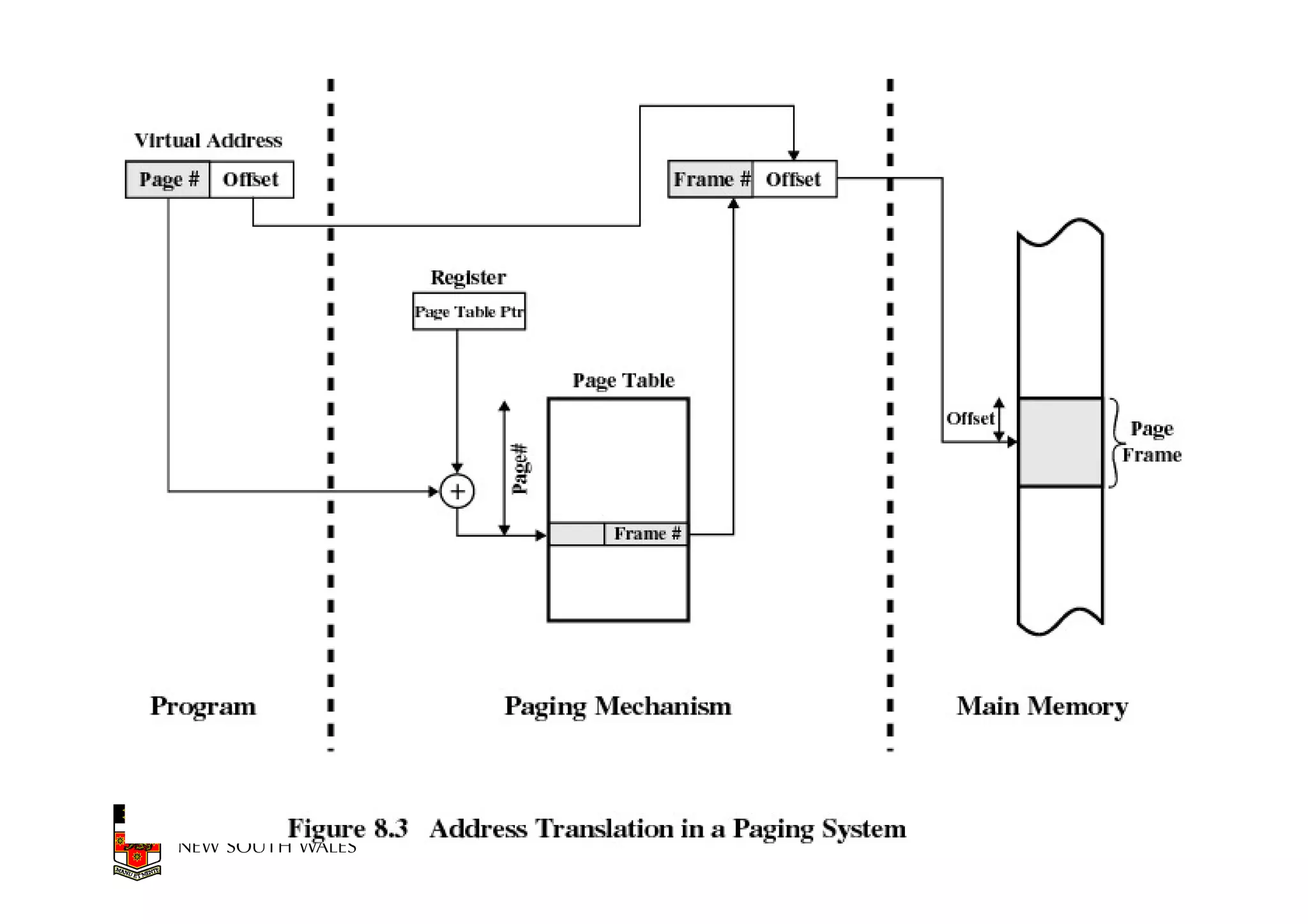
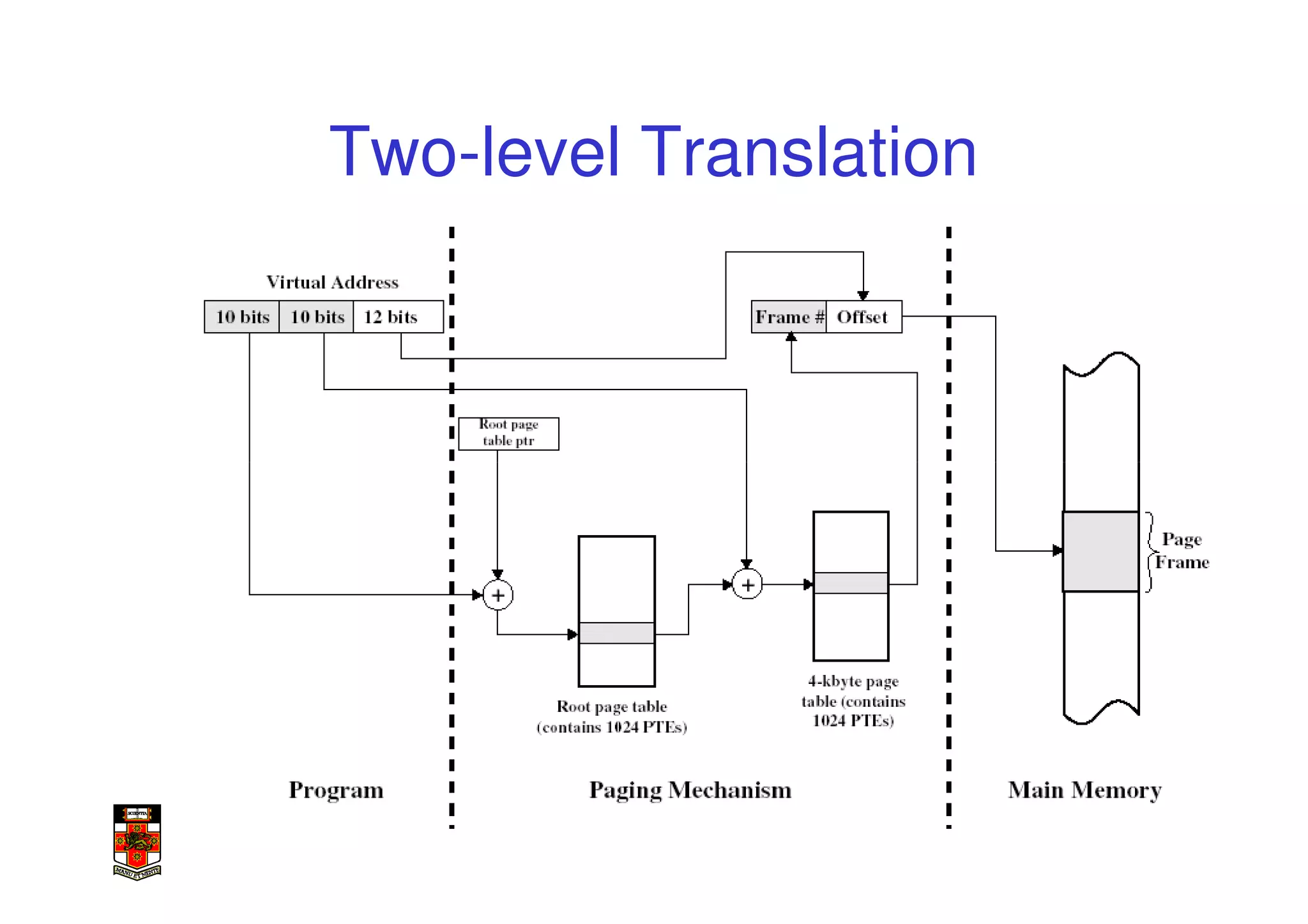

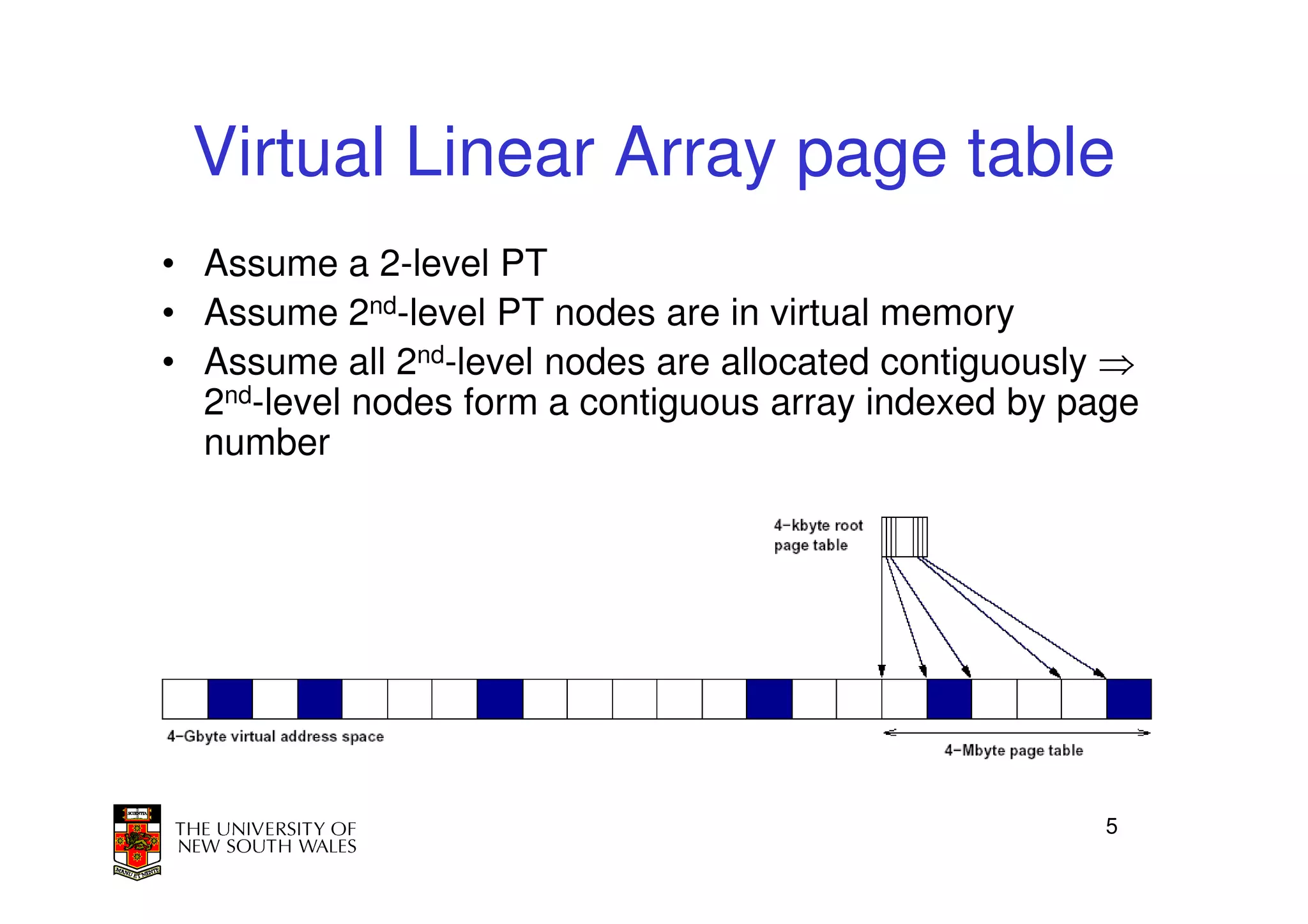
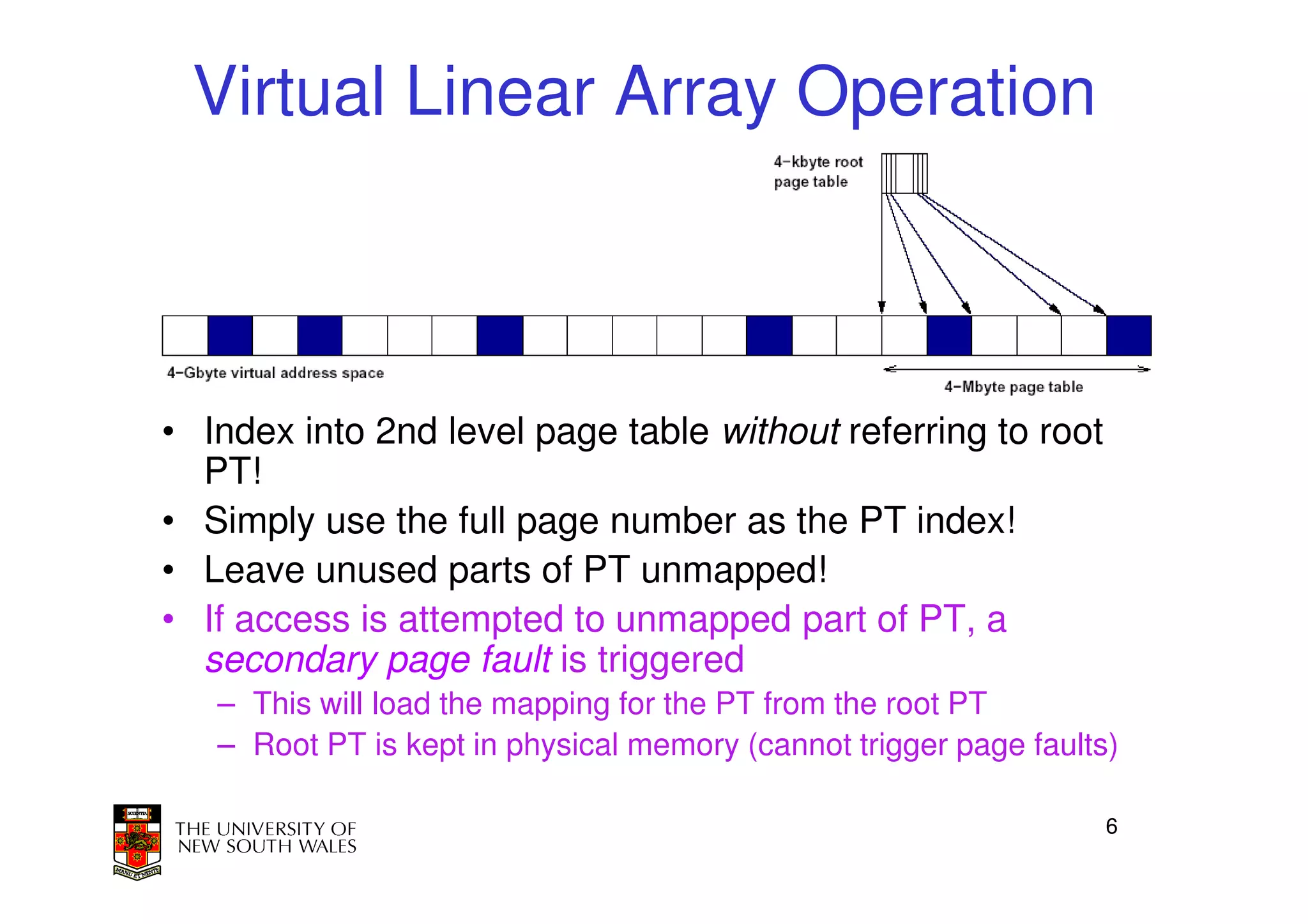
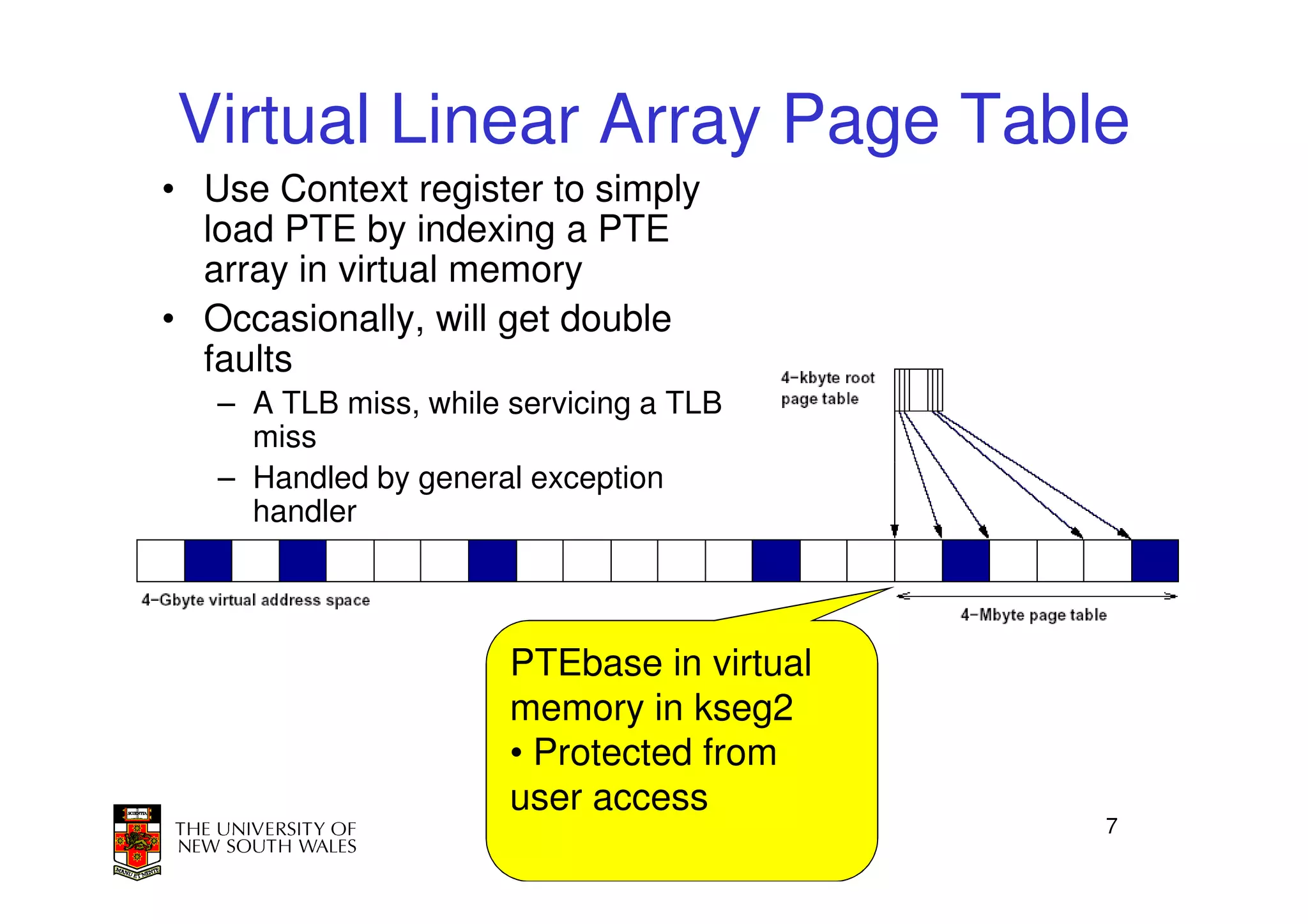

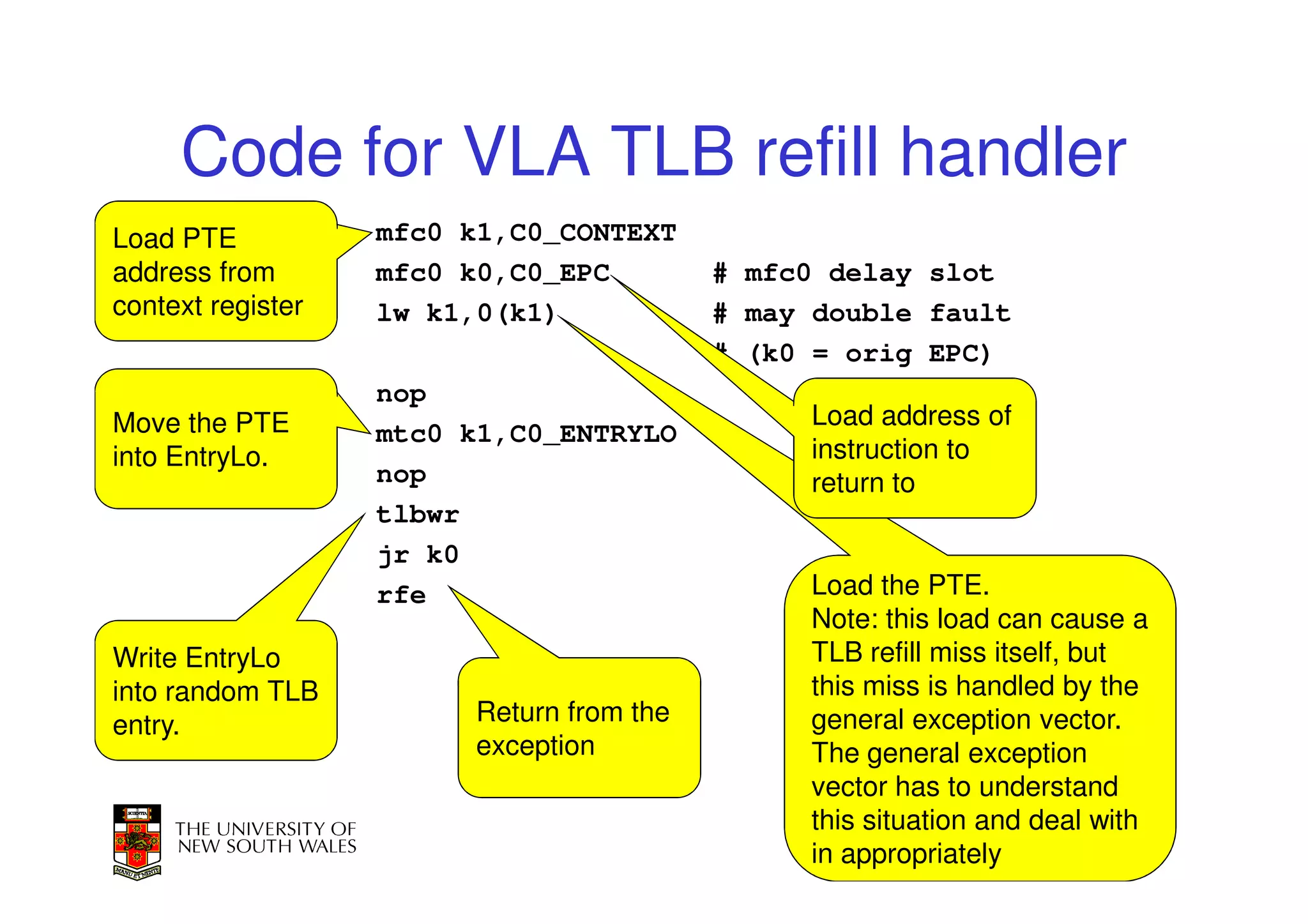



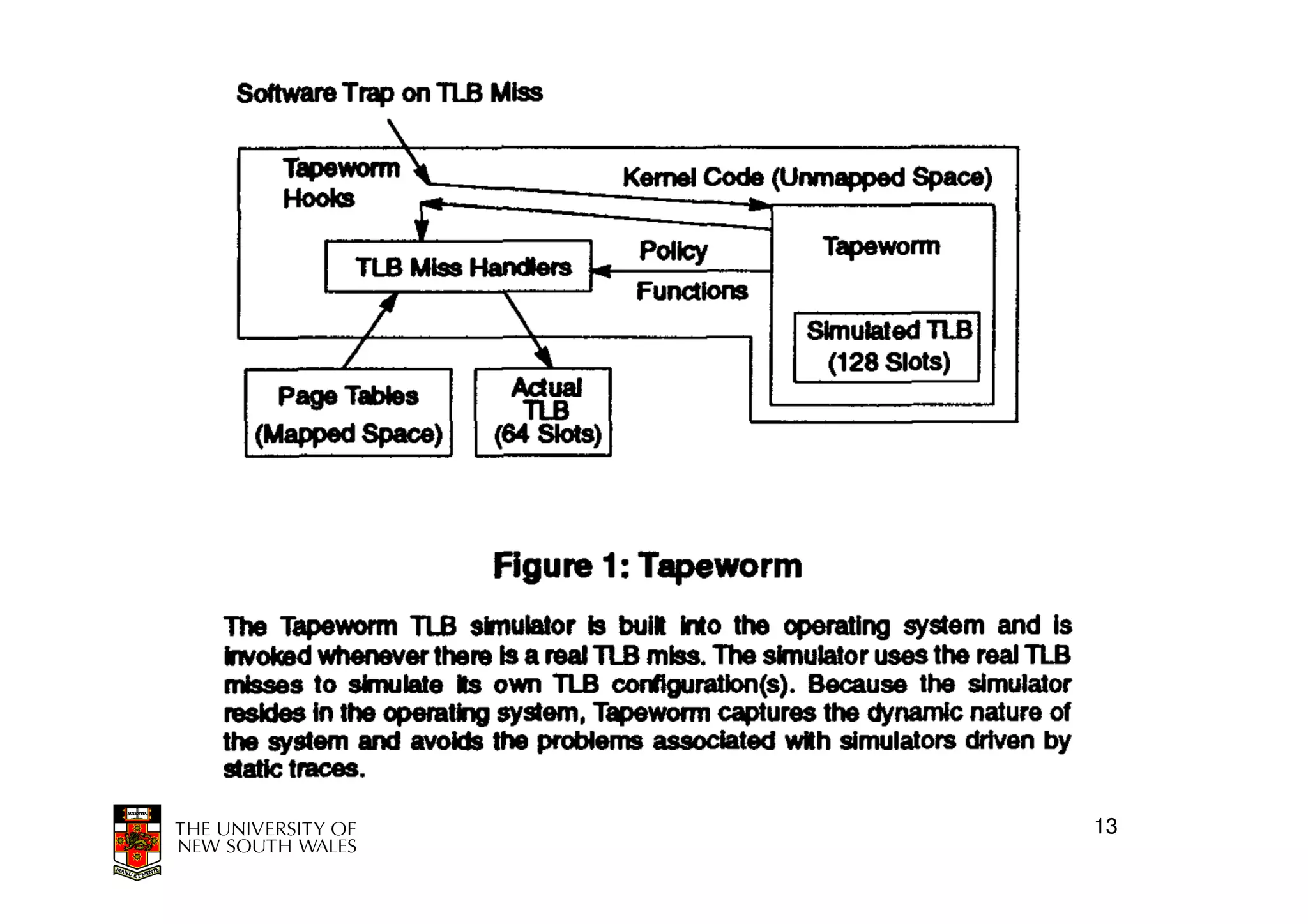
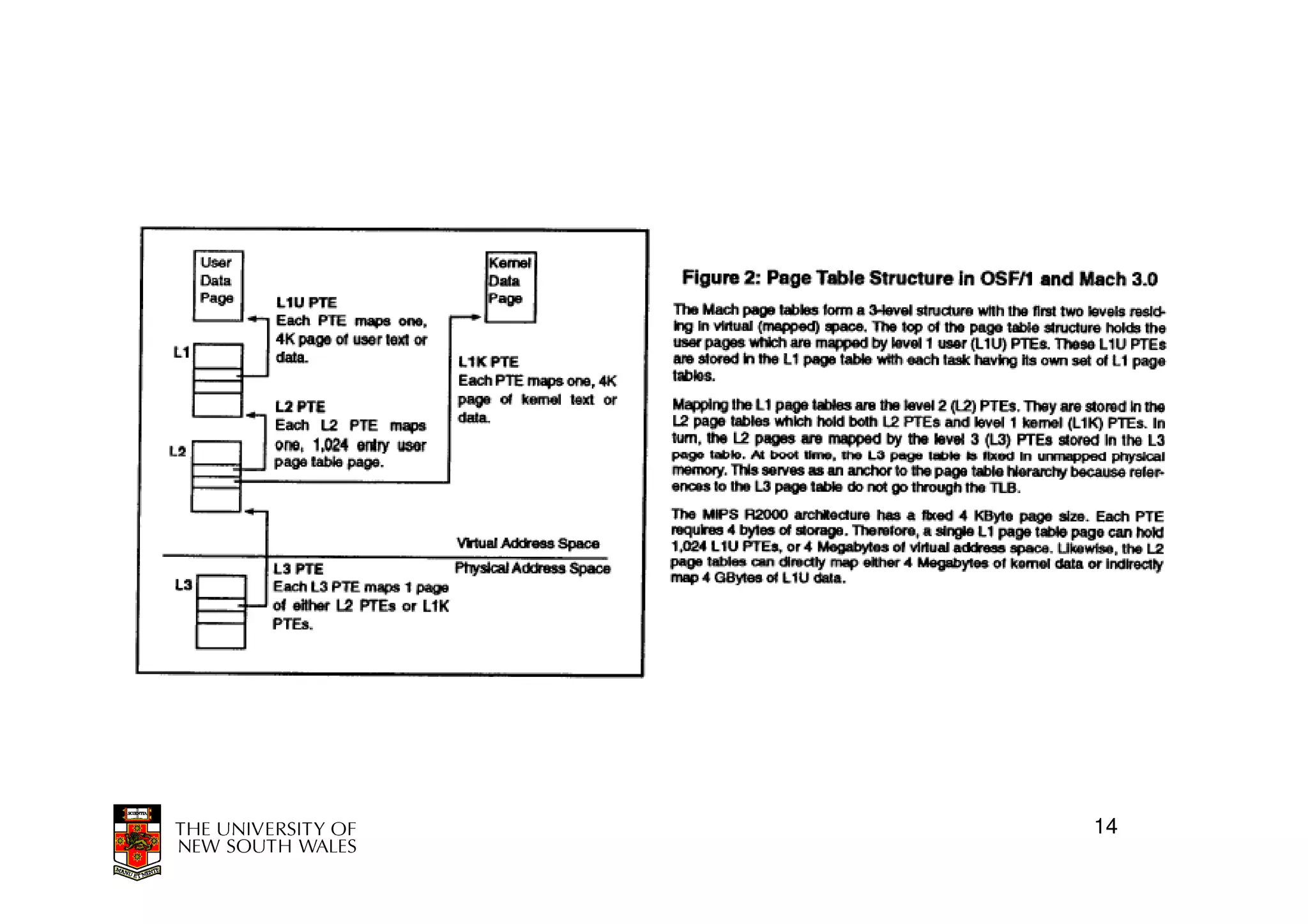
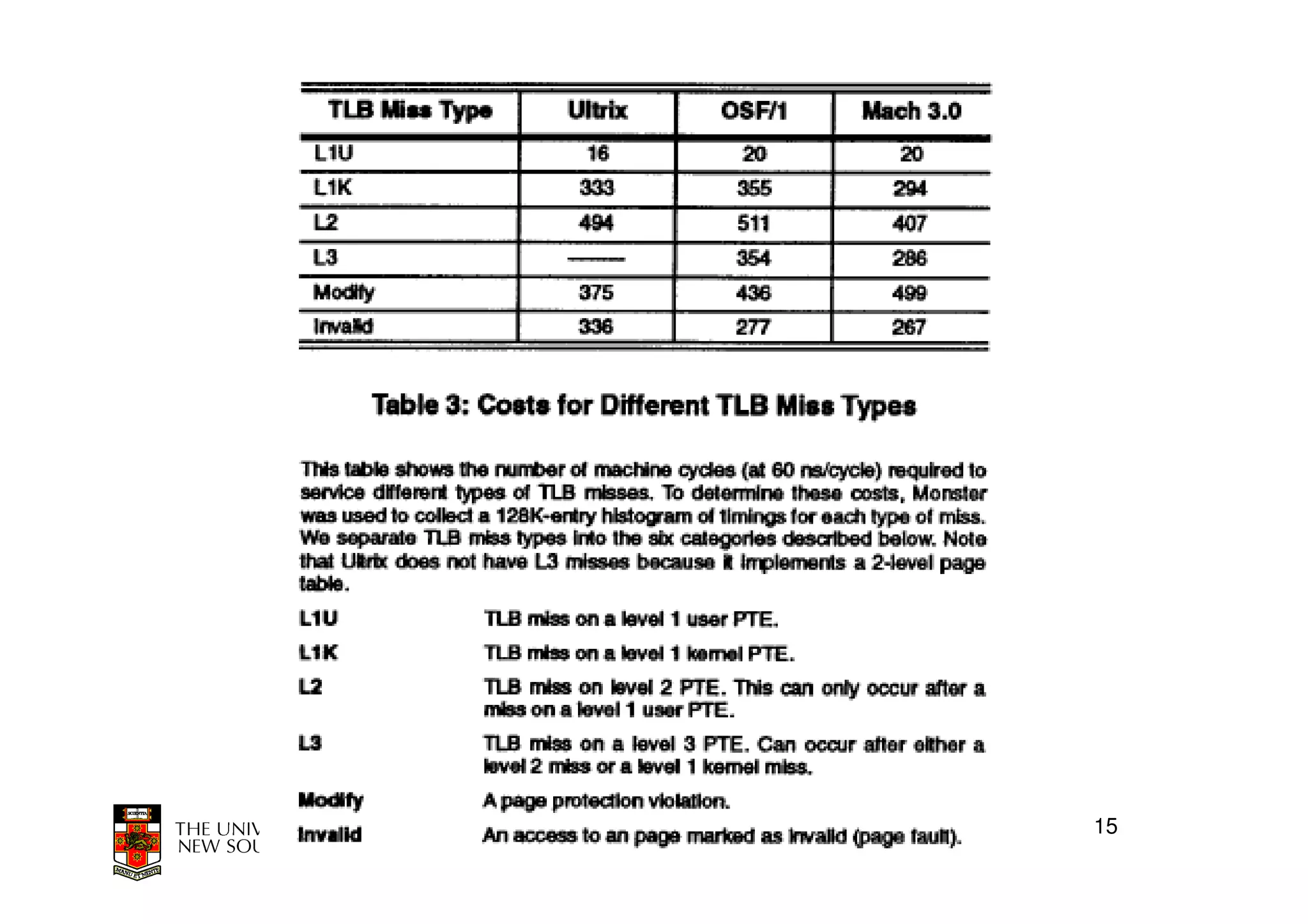

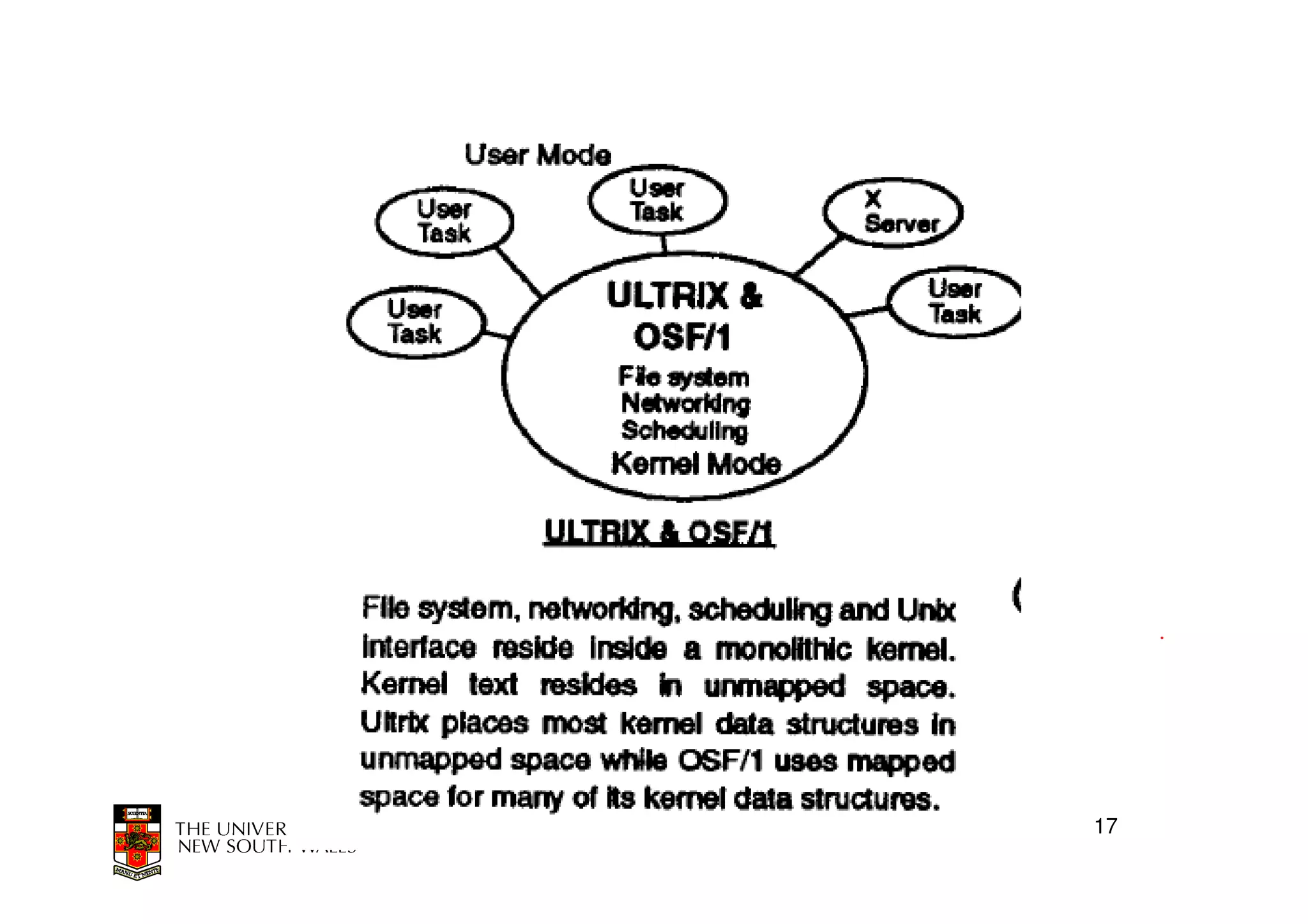
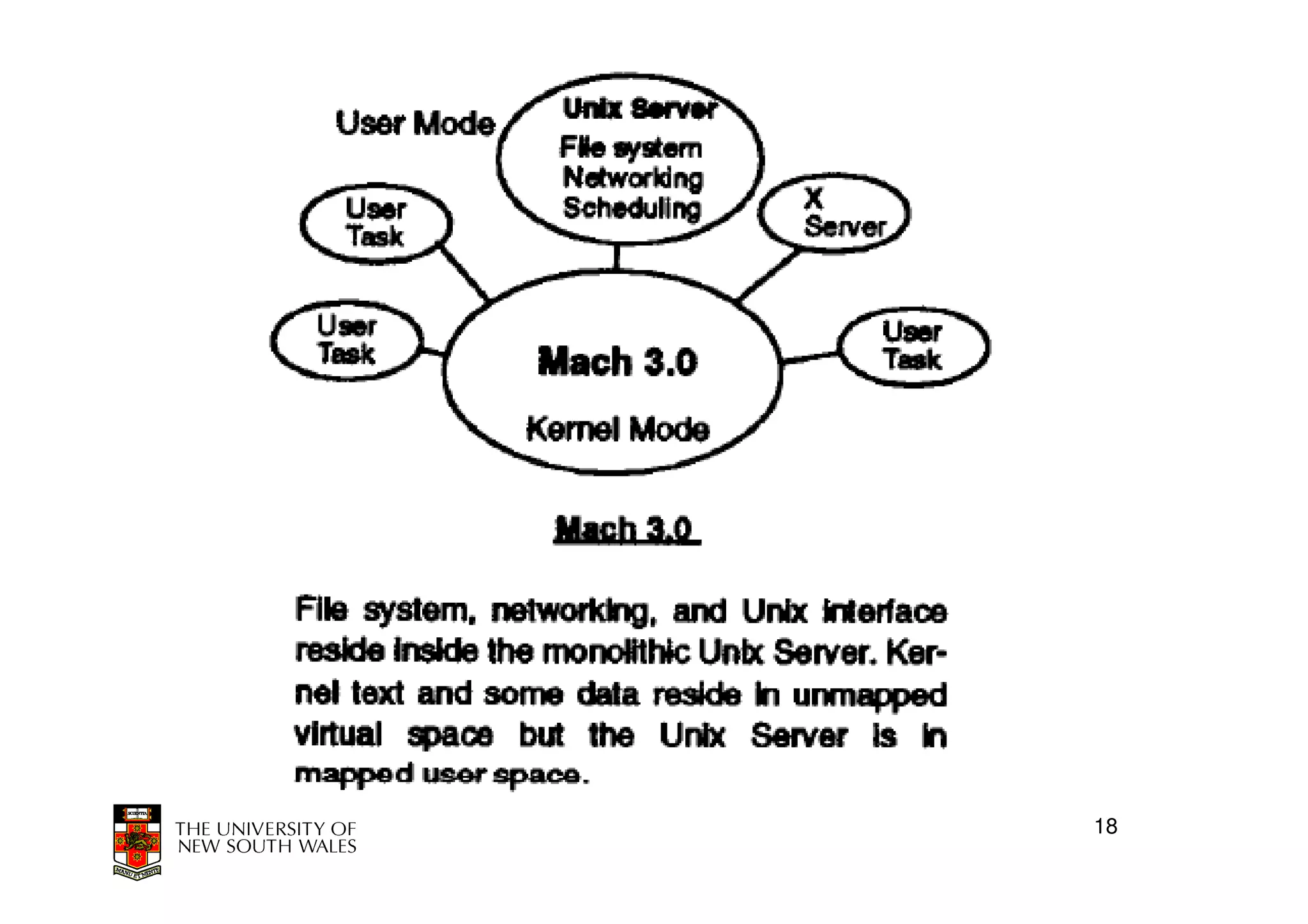
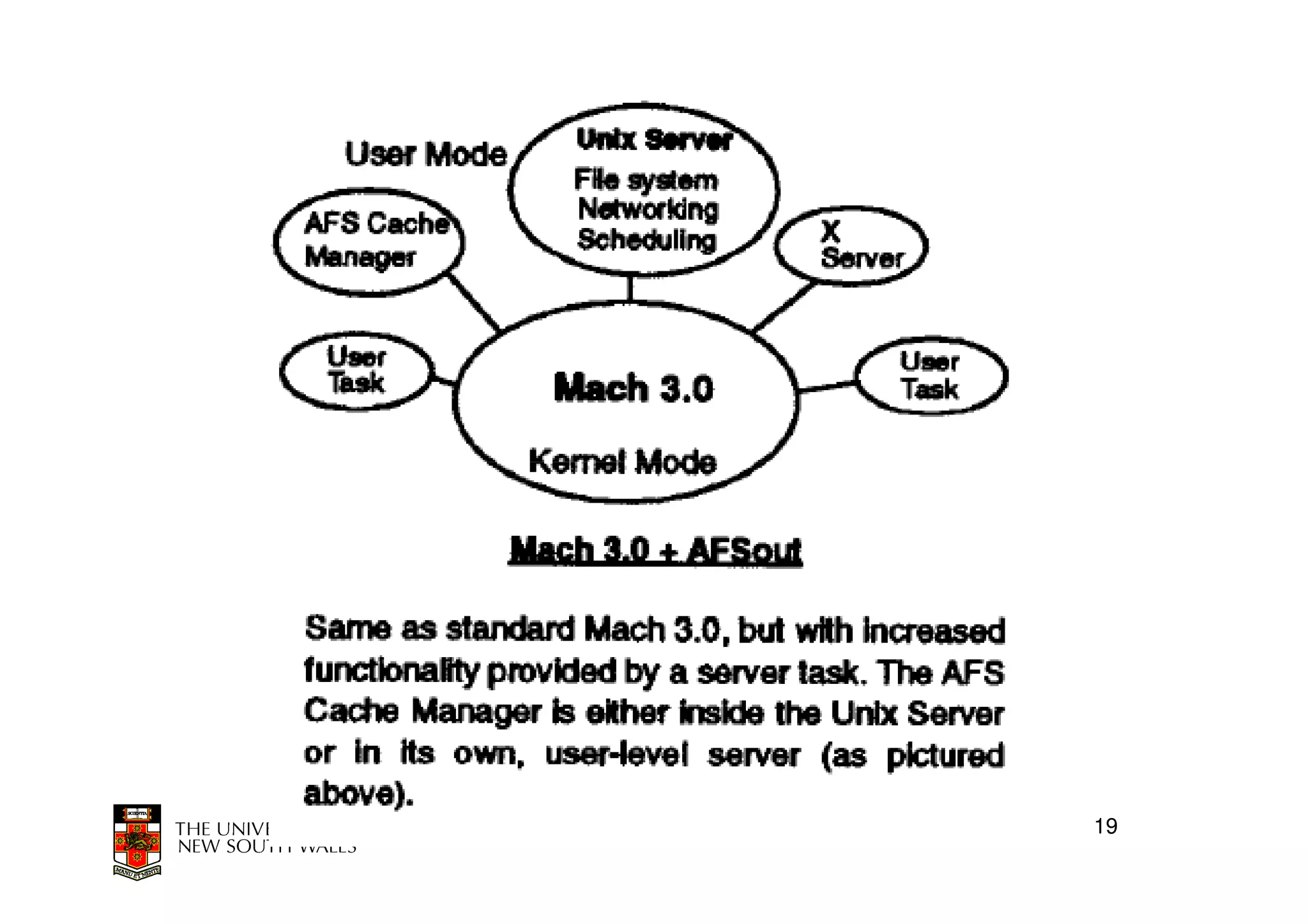
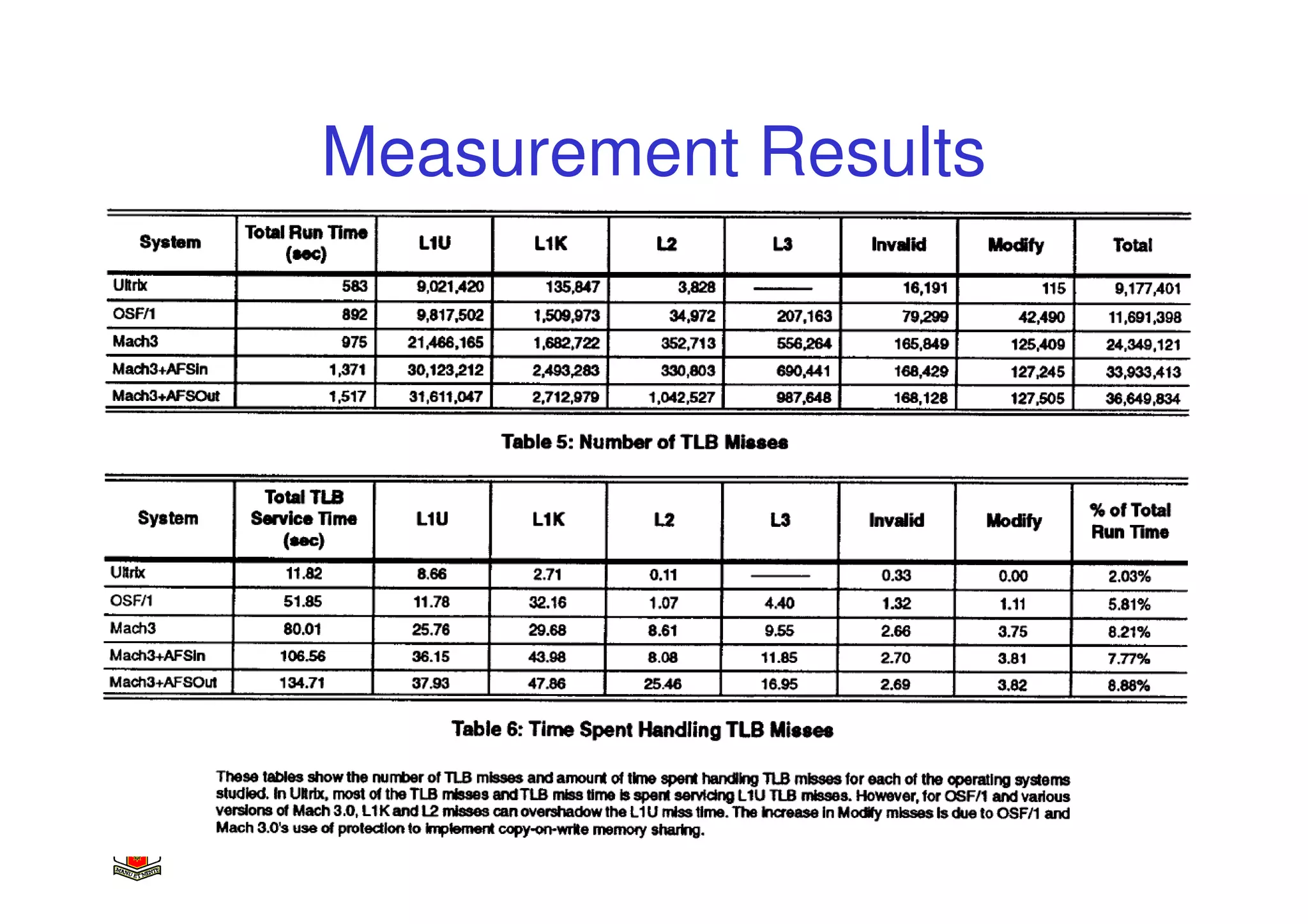
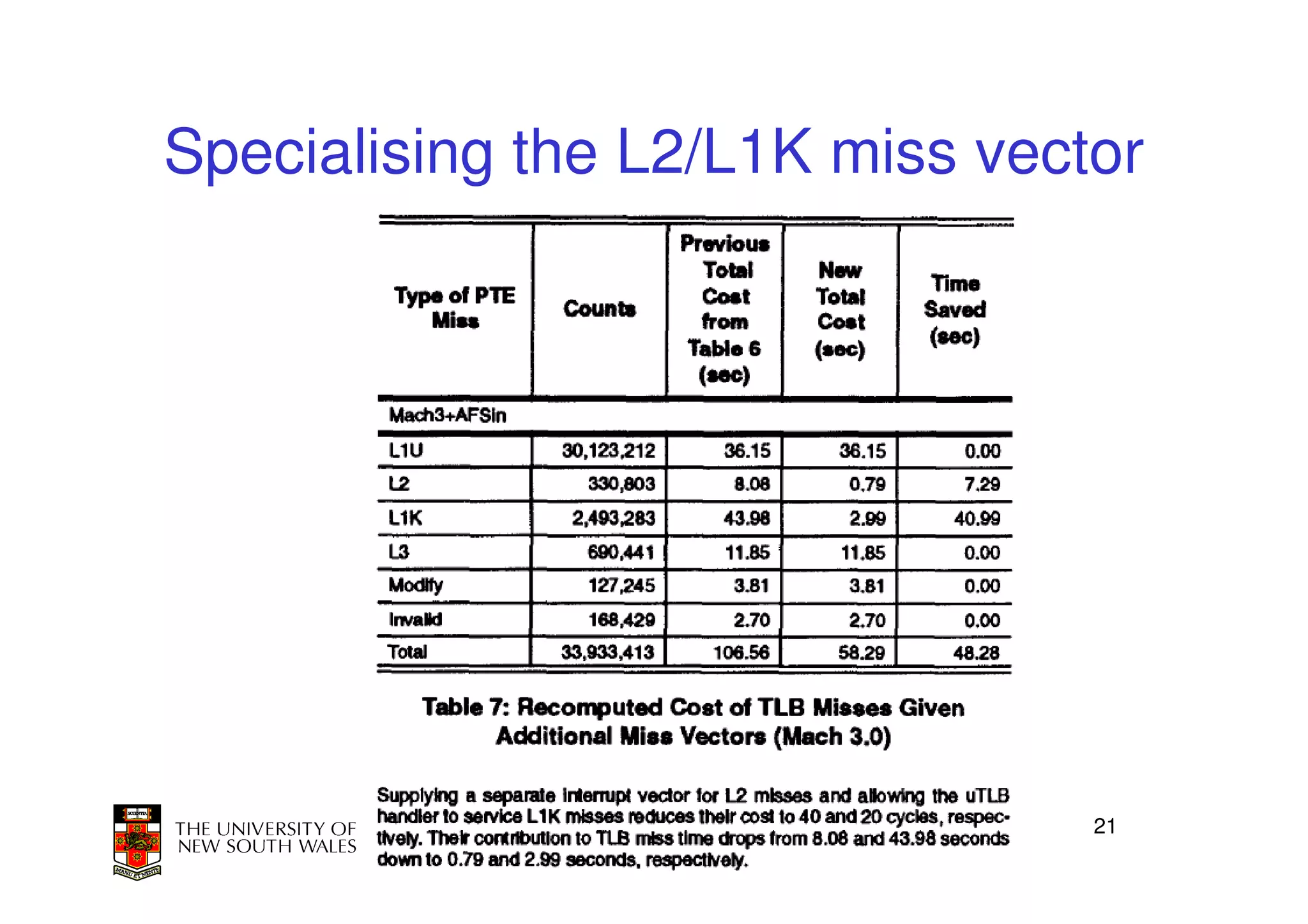


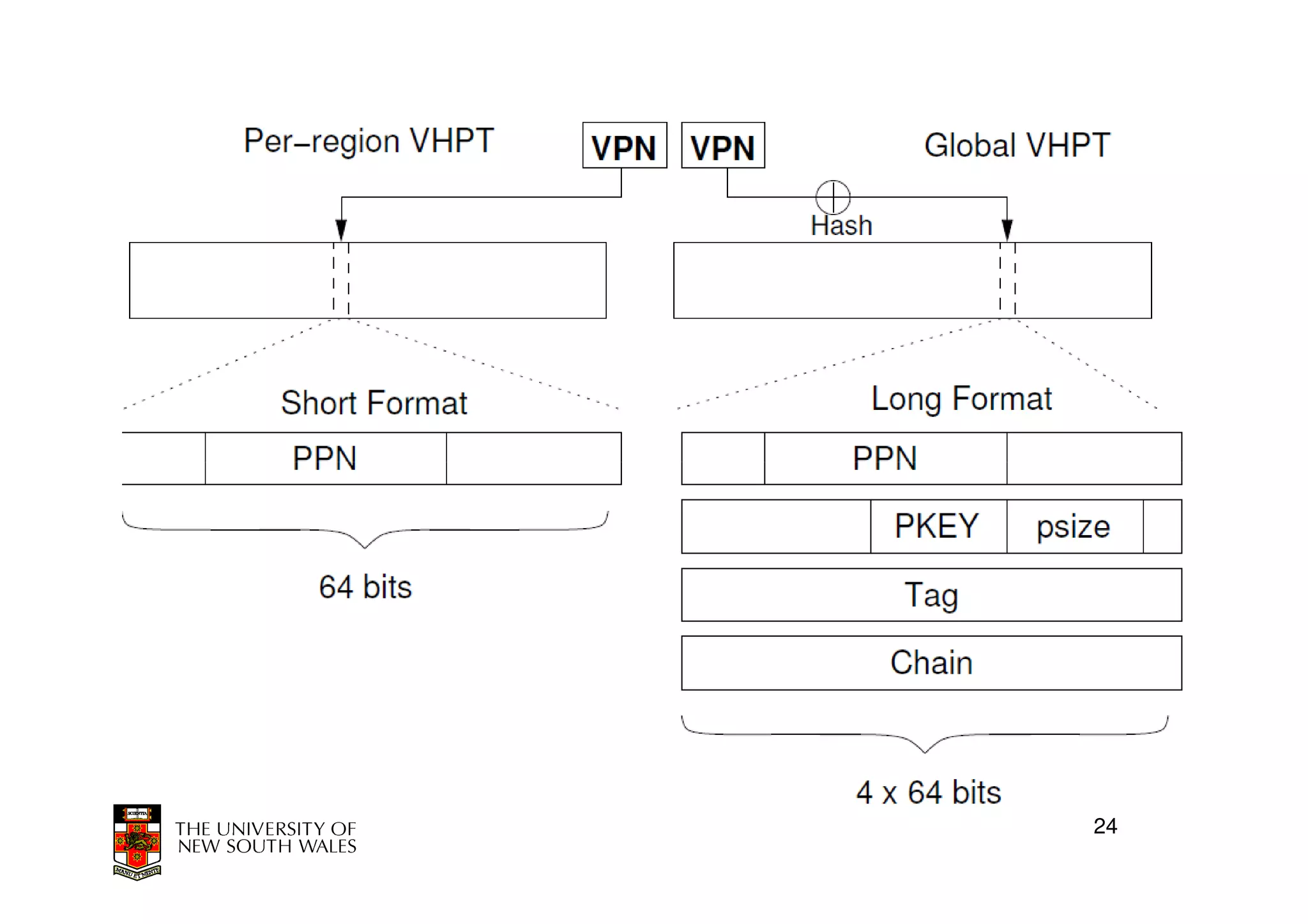



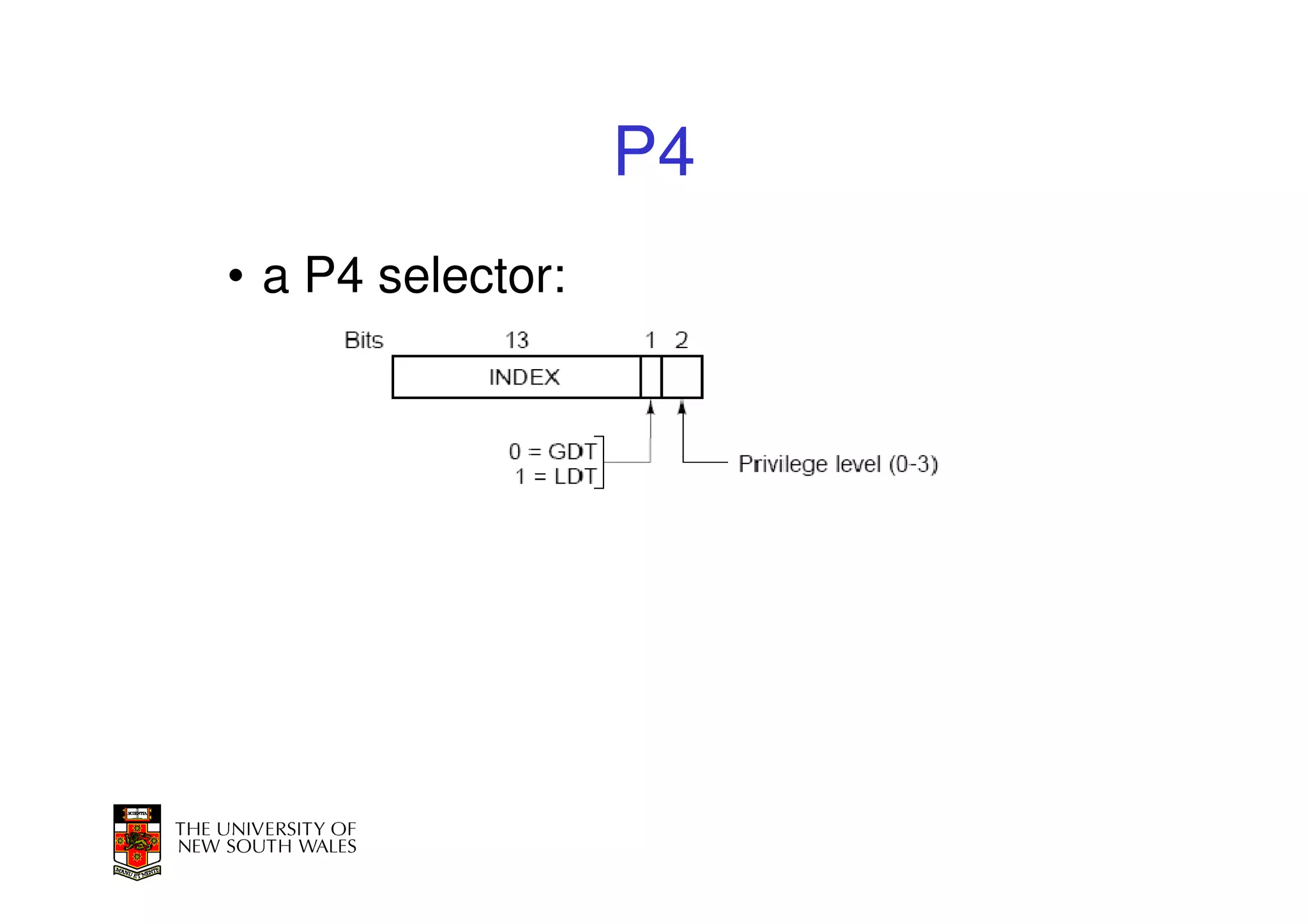
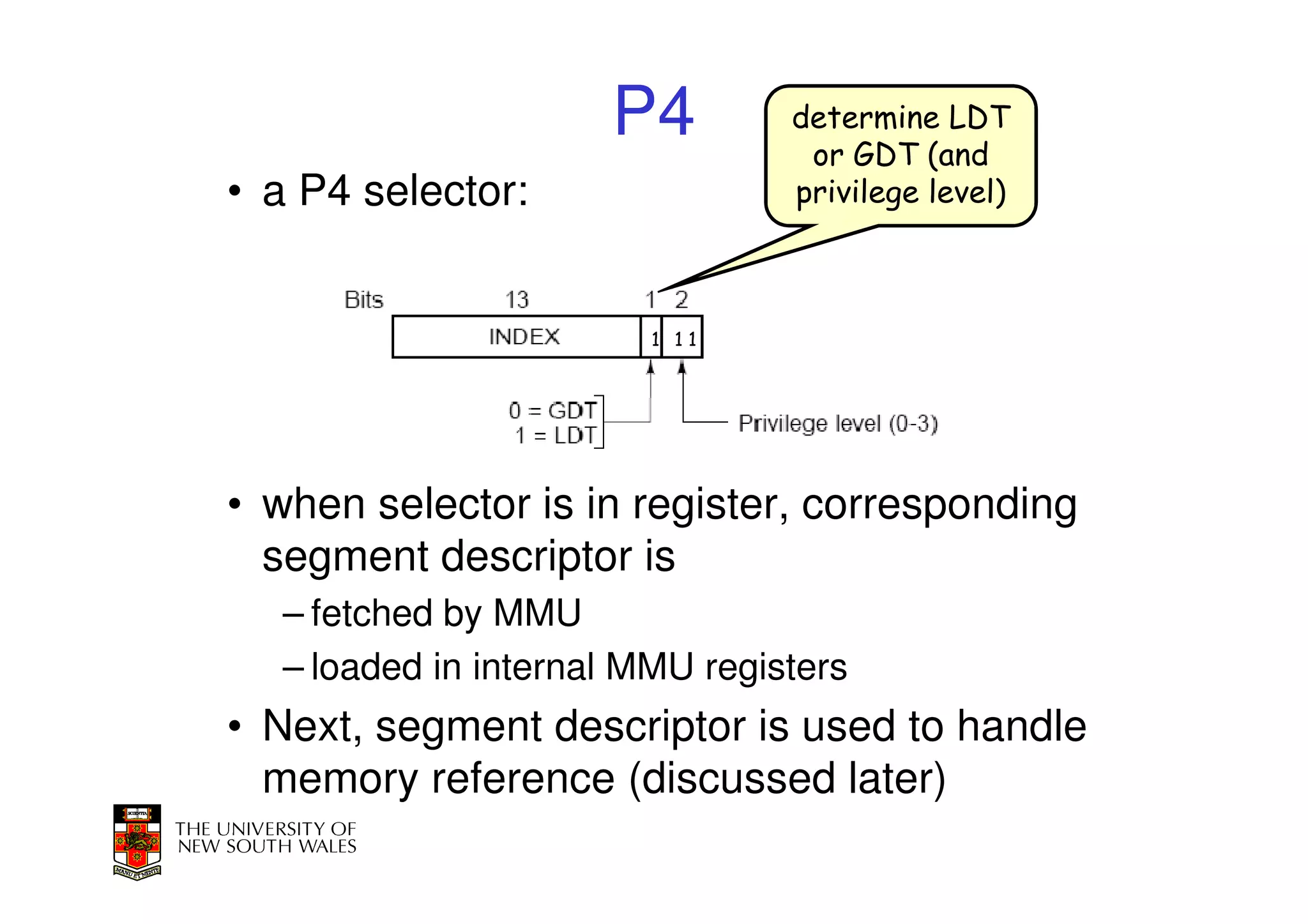
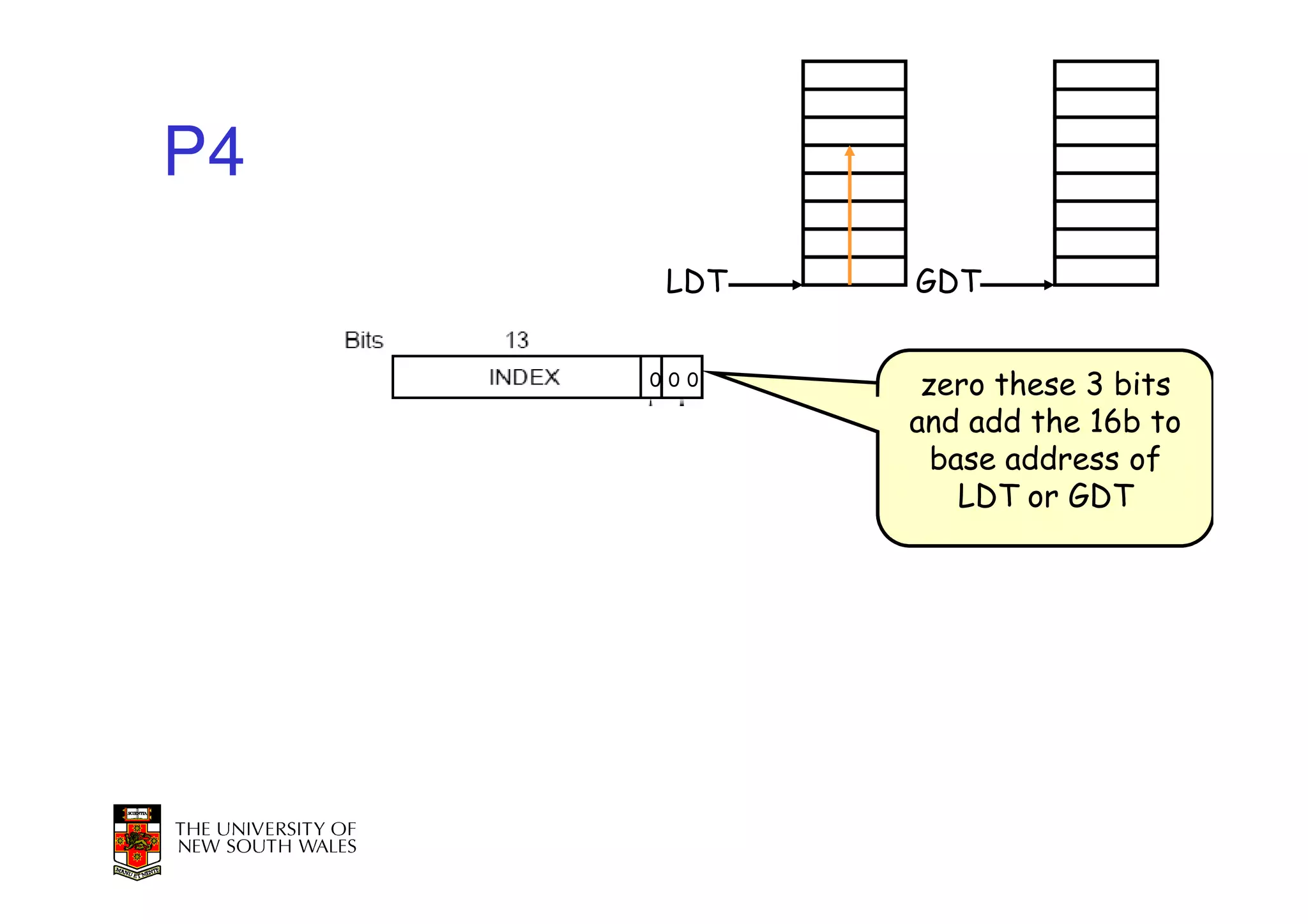
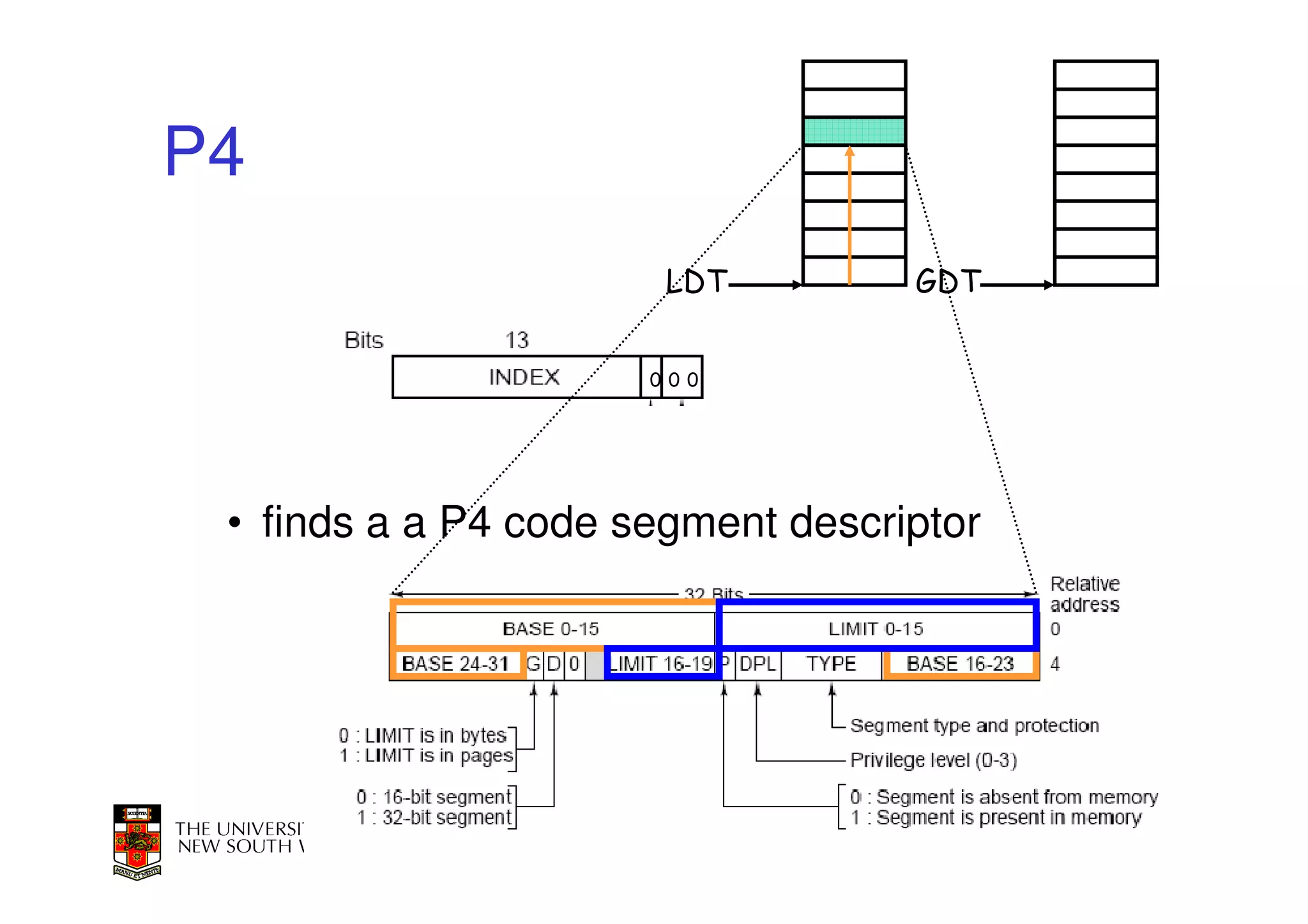
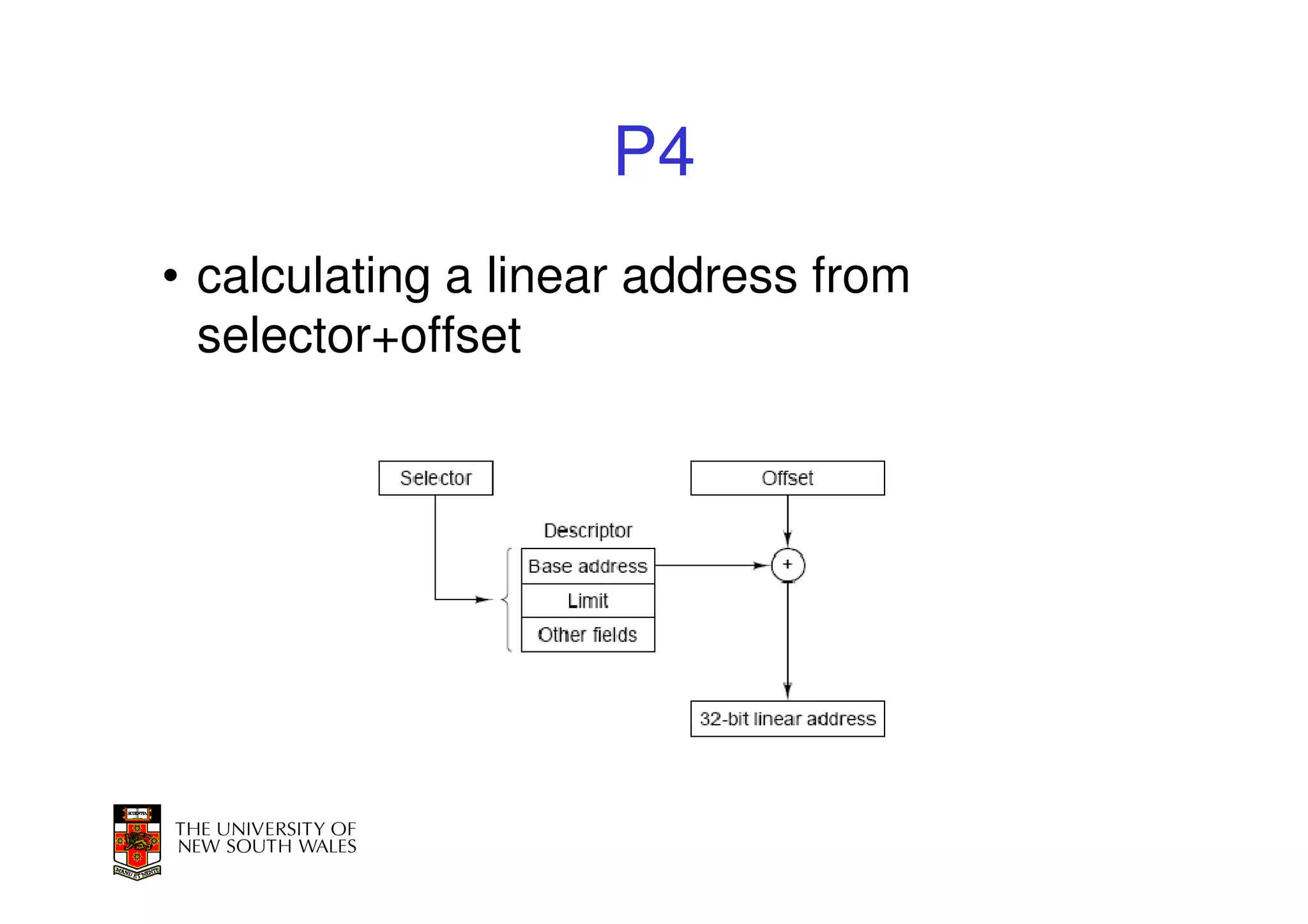




This document discusses software-managed translation lookaside buffers (TLBs) and page tables. It begins by describing a virtual linear array approach to page tables that allows indexing directly into the second-level page table without referring to the root page table. It then provides code for a TLB refill handler using this approach. The document discusses trends that increase TLB miss rates and evaluates tradeoffs of software-managed TLBs. It also briefly covers Itanium, P4, and x86 page table structures and segmentation.






























































![[Paper reading] Interleaving with Coroutines: A Practical Approach for Robust...](https://cdn.slidesharecdn.com/ss_thumbnails/paperreadinginterleavingwithcoroutinesapracticalapproachforrobustindexjoin-211011055753-thumbnail.jpg?width=640&height=640&fit=bounds)












































