Downloaded 22 times
















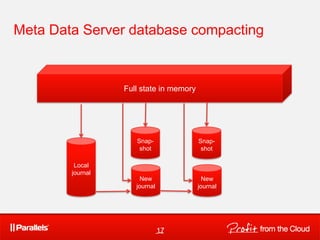
















1. The document discusses a distributed, scalable, and highly reliable data storage system for virtual machines and other uses called HighLoad++. 2. It proposes using a simplified design that focuses on core capabilities like data replication and recovery to achieve both low costs and high performance. 3. The design splits data into chunks that are replicated across multiple servers and includes metadata servers to track the location and versions of chunks to enable eventual consistency despite failures.

























![[B4]deview 2012-hdfs](https://cdn.slidesharecdn.com/ss_thumbnails/b4deview-2012-hdfs-120919013559-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)


















































