Downloaded 120 times





































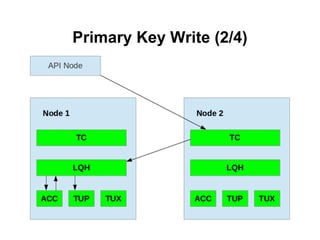
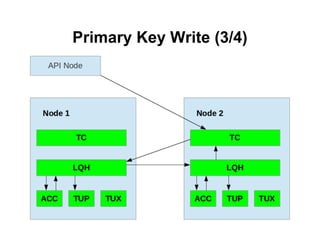
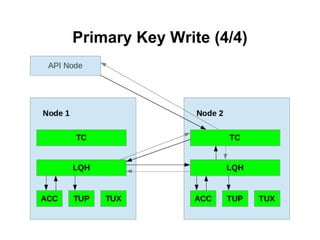
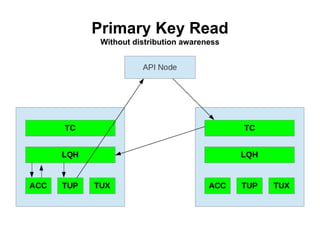




















![Using SQL statement:
CREATE LOGFILE GROUP logfile_group
ADD UNDOFILE 'undo_file'
[INITIAL_SIZE [=] initial_size]
[UNDO_BUFFER_SIZE [=] undo_buffer_size]
ENGINE [=] engine_name
Create Undo Log Group](https://image.slidesharecdn.com/ndbclustertutorial-perconalive2013-130513162107-phpapp01/85/Ramp-Tutorial-for-MYSQL-Cluster-Scaling-with-Continuous-Availability-79-320.jpg)

![ALTER LOGFILE GROUP logfile_group
ADD UNDOFILE 'undo_file'
[INITIAL_SIZE [=] initial_size]
ENGINE [=] engine_name
Alter Undo Log Group](https://image.slidesharecdn.com/ndbclustertutorial-perconalive2013-130513162107-phpapp01/85/Ramp-Tutorial-for-MYSQL-Cluster-Scaling-with-Continuous-Availability-81-320.jpg)

![In [NDBD] definition:
InitialLogFileGroup = [name=name;]
[undo_buffer_size=size;] file-specification-list
Example:
InitialLogFileGroup = name=lg1;
undo_buffer_size=8M; undo1.log:128M;undo2.log:128M
Create Undo Log Group](https://image.slidesharecdn.com/ndbclustertutorial-perconalive2013-130513162107-phpapp01/85/Ramp-Tutorial-for-MYSQL-Cluster-Scaling-with-Continuous-Availability-83-320.jpg)
![Using SQL statement:
CREATE TABLESPACE tablespace_name
ADD DATAFILE 'file_name'
USE LOGFILE GROUP logfile_group
[INITIAL_SIZE [=] initial_size]
ENGINE [=] engine_name
Create Tablespace](https://image.slidesharecdn.com/ndbclustertutorial-perconalive2013-130513162107-phpapp01/85/Ramp-Tutorial-for-MYSQL-Cluster-Scaling-with-Continuous-Availability-84-320.jpg)

![Using SQL statement:
ALTER TABLESPACE tablespace_name
{ADD|DROP} DATAFILE 'file_name'
[INITIAL_SIZE [=] size]
ENGINE [=] engine_name
Alter Tablespace](https://image.slidesharecdn.com/ndbclustertutorial-perconalive2013-130513162107-phpapp01/85/Ramp-Tutorial-for-MYSQL-Cluster-Scaling-with-Continuous-Availability-86-320.jpg)

![In [NDBD] definition:
InitialTablespace = [name=name;] [extent_size=size;]
file-specification-list
Example:
InitialTablespace = name=ts1;
datafile1.data:64M; datafile2.data:128M
Note: no need to specify the Undo Log Group
Create Tablespace](https://image.slidesharecdn.com/ndbclustertutorial-perconalive2013-130513162107-phpapp01/85/Ramp-Tutorial-for-MYSQL-Cluster-Scaling-with-Continuous-Availability-88-320.jpg)






















![Backup with mysqldump ( cont. )
Usage:
mysqldump [options] db_name [tbl_name ...]
mysqldump [options] --databases db_name ...
mysqldump [options] --all-databases
shell> mysqldump world > world.sql
Question: What about --single-transaction ?](https://image.slidesharecdn.com/ndbclustertutorial-perconalive2013-130513162107-phpapp01/85/Ramp-Tutorial-for-MYSQL-Cluster-Scaling-with-Continuous-Availability-111-320.jpg)




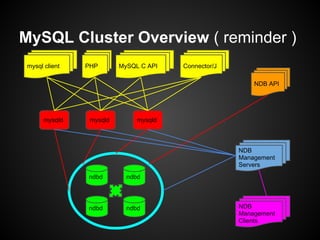
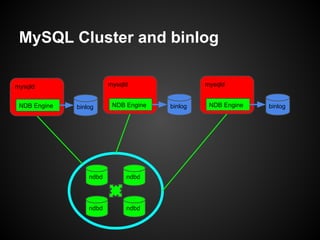

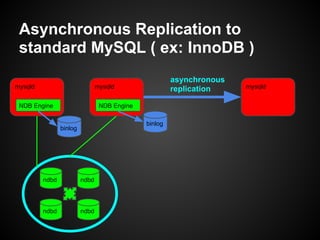
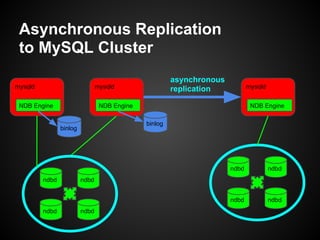



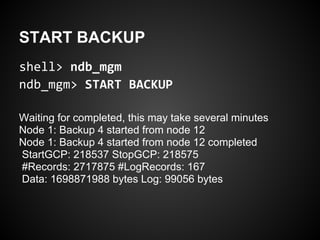









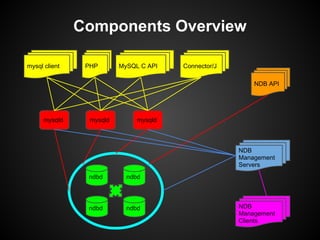
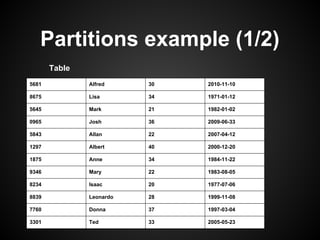
This document provides an overview and tutorial on MySQL Cluster (NDB), which is a high availability, clustering storage engine for MySQL. It discusses key MySQL Cluster components like management nodes, data nodes, API nodes, and how data is partitioned and replicated across nodes. It also covers transaction handling, checkpointing, failure handling, and configuration of disk data. The tutorial is aimed at explaining basic concepts and components of MySQL Cluster to attendees.
































































































