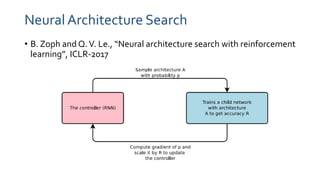
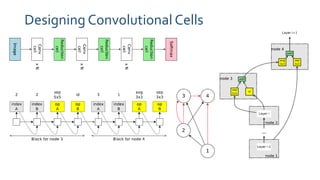
The document discusses a paper on efficient neural architecture search through parameter sharing, highlighting the advantages of using shared weights to enhance computational efficiency significantly. The proposed method, ENAS, uses a directed acyclic graph to optimize the search space, resulting in training times drastically shorter than traditional methods. Experimental results show notable performance compared to baseline methods, reinforcing the model's practicality in real-world applications.






























![[한국어] Neural Architecture Search with Reinforcement Learning](https://cdn.slidesharecdn.com/ss_thumbnails/nas-170612232020-thumbnail.jpg?width=640&height=640&fit=bounds)



















































































