The document summarizes a study on training Vision Transformers (ViTs) by exploring different combinations of data augmentation, regularization techniques, model sizes, and training dataset sizes. Some key findings include: 1) Models trained with extensive data augmentation on ImageNet-1k performed comparably to those trained on the larger ImageNet-21k dataset without augmentation. 2) Transfer learning from pre-trained models was more efficient and achieved better results than training models from scratch, even with extensive compute. 3) Models pre-trained on more data showed better transfer ability, indicating more data yields more generic representations.
PR-231: A Simple Framework for Contrastive Learning of Visual RepresentationsJinwon Lee
TensorFlow Korea 논문읽기모임 PR12 231번째 논문 review 입니다
이번 논문은 Google Brain에서 나온 A Simple Framework for Contrastive Learning of Visual Representations입니다. Geoffrey Hinton님이 마지막 저자이시기도 해서 최근에 더 주목을 받고 있는 논문입니다.
이 논문은 최근에 굉장히 핫한 topic인 contrastive learning을 이용한 self-supervised learning쪽 논문으로 supervised learning으로 학습한 ResNet50와 동일한 성능을 얻을 수 있는 unsupervised pre-trainig 방법을 제안하였습니다. Data augmentation, Non-linear projection head, large batch size, longer training, NTXent loss 등을 활용하여 훌륭한 representation learning이 가능함을 보여주었고, semi-supervised learning이나 transfer learning에서도 매우 뛰어난 결과를 보여주었습니다. 자세한 내용은 영상을 참고해주세요
논문링크: https://arxiv.org/abs/2002.05709
영상링크: https://youtu.be/FWhM3juUM6s
Vision Transformer(ViT) / An Image is Worth 16*16 Words: Transformers for Ima...changedaeoh
computer vision 분야에서 dominant 한 Convolutional Layer를 일절 사용하지 않고, NLP에서 제안된 순수 Transformer의 architecture를 그대로 가져와 Attention과 일반 Feed Forward NN만을 이용하여 SOTA수준의 Image Classification Model을 구축한다.
TAVE research seminar 21.03.30 발표자료
발표자: 오창대
PR-284: End-to-End Object Detection with Transformers(DETR)Jinwon Lee
TensorFlow Korea 논문읽기모임 PR12 284번째 논문 review입니다.
이번 논문은 Facebook에서 나온 DETR(DEtection with TRansformer) 입니다.
arxiv-sanity에 top recent/last year에서 가장 상위에 자리하고 있는 논문이기도 합니다(http://www.arxiv-sanity.com/top?timefilter=year&vfilter=all)
최근에 ICLR 2021에 submit된 ViT로 인해서 이제 Transformer가 CNN을 대체하는 것 아닌가 하는 얘기들이 많이 나오고 있는데요, 올 해 ECCV에 발표된 논문이고 feature extraction 부분은 CNN을 사용하긴 했지만 transformer를 활용하여 효과적으로 Object Detection을 수행하는 방법을 제안한 중요한 논문이라고 생각합니다. 이 논문에서는 detection 문제에서 anchor box나 NMS(Non Maximum Supression)와 같은 heuristic 하고 미분 불가능한 방법들이 많이 사용되고, 이로 인해서 유독 object detection 문제는 딥러닝의 철학인 end-to-end 방식으로 해결되지 못하고 있음을 지적하고 있습니다. 그 해결책으로 bounding box를 예측하는 문제를 set prediction problem(중복을 허용하지 않고, 순서에 무관함)으로 보고 transformer를 활용한 end-to-end 방식의 알고리즘을 제안하였습니다. anchor box도 필요없고 NMS도 필요없는 DETR 알고리즘의 자세한 내용이 알고싶으시면 영상을 참고해주세요!
영상링크: https://youtu.be/lXpBcW_I54U
논문링크: https://arxiv.org/abs/2005.12872
PR-297: Training data-efficient image transformers & distillation through att...Jinwon Lee
안녕하세요 TensorFlow Korea 논문 읽기 모임 PR-12의 297번째 리뷰입니다
어느덧 PR-12 시즌 3의 끝까지 논문 3편밖에 남지 않았네요.
시즌 3가 끝나면 바로 시즌 4의 새 멤버 모집이 시작될 예정입니다. 많은 관심과 지원 부탁드립니다~~
(멤버 모집 공지는 Facebook TensorFlow Korea 그룹에 올라올 예정입니다)
오늘 제가 리뷰한 논문은 Facebook의 Training data-efficient image transformers & distillation through attention 입니다.
Google에서 나왔던 ViT논문 이후에 convolution을 전혀 사용하지 않고 오직 attention만을 이용한 computer vision algorithm에 어느때보다 관심이 높아지고 있는데요
이 논문에서 제안한 DeiT 모델은 ViT와 같은 architecture를 사용하면서 ViT가 ImageNet data만으로는 성능이 잘 안나왔던 것에 비해서
Training 방법 개선과 새로운 Knowledge Distillation 방법을 사용하여 mageNet data 만으로 EfficientNet보다 뛰어난 성능을 보여주는 결과를 얻었습니다.
정말 CNN은 이제 서서히 사라지게 되는 것일까요? Attention이 computer vision도 정복하게 될 것인지....
개인적으로는 당분간은 attention 기반의 CV 논문이 쏟아질 거라고 확신하고, 또 여기에서 놀라운 일들이 일어날 수 있을 거라고 생각하고 있습니다
CNN은 10년간 많은 연구를 통해서 발전해왔지만, transformer는 이제 CV에 적용된 지 얼마 안된 시점이라서 더 기대가 크구요,
attention이 inductive bias가 가장 적은 형태의 모델이기 때문에 더 놀라운 이들을 만들 수 있을거라고 생각합니다
얼마 전에 나온 open AI의 DALL-E도 그 대표적인 예라고 할 수 있을 것 같습니다. Transformer의 또하나의 transformation이 궁금하신 분들은 아래 영상을 참고해주세요
영상링크: https://youtu.be/DjEvzeiWBTo
논문링크: https://arxiv.org/abs/2012.12877
Transformer Architectures in Vision
[2018 ICML] Image Transformer
[2019 CVPR] Video Action Transformer Network
[2020 ECCV] End-to-End Object Detection with Transformers
[2021 ICLR] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
PR-231: A Simple Framework for Contrastive Learning of Visual RepresentationsJinwon Lee
TensorFlow Korea 논문읽기모임 PR12 231번째 논문 review 입니다
이번 논문은 Google Brain에서 나온 A Simple Framework for Contrastive Learning of Visual Representations입니다. Geoffrey Hinton님이 마지막 저자이시기도 해서 최근에 더 주목을 받고 있는 논문입니다.
이 논문은 최근에 굉장히 핫한 topic인 contrastive learning을 이용한 self-supervised learning쪽 논문으로 supervised learning으로 학습한 ResNet50와 동일한 성능을 얻을 수 있는 unsupervised pre-trainig 방법을 제안하였습니다. Data augmentation, Non-linear projection head, large batch size, longer training, NTXent loss 등을 활용하여 훌륭한 representation learning이 가능함을 보여주었고, semi-supervised learning이나 transfer learning에서도 매우 뛰어난 결과를 보여주었습니다. 자세한 내용은 영상을 참고해주세요
논문링크: https://arxiv.org/abs/2002.05709
영상링크: https://youtu.be/FWhM3juUM6s
Vision Transformer(ViT) / An Image is Worth 16*16 Words: Transformers for Ima...changedaeoh
computer vision 분야에서 dominant 한 Convolutional Layer를 일절 사용하지 않고, NLP에서 제안된 순수 Transformer의 architecture를 그대로 가져와 Attention과 일반 Feed Forward NN만을 이용하여 SOTA수준의 Image Classification Model을 구축한다.
TAVE research seminar 21.03.30 발표자료
발표자: 오창대
PR-284: End-to-End Object Detection with Transformers(DETR)Jinwon Lee
TensorFlow Korea 논문읽기모임 PR12 284번째 논문 review입니다.
이번 논문은 Facebook에서 나온 DETR(DEtection with TRansformer) 입니다.
arxiv-sanity에 top recent/last year에서 가장 상위에 자리하고 있는 논문이기도 합니다(http://www.arxiv-sanity.com/top?timefilter=year&vfilter=all)
최근에 ICLR 2021에 submit된 ViT로 인해서 이제 Transformer가 CNN을 대체하는 것 아닌가 하는 얘기들이 많이 나오고 있는데요, 올 해 ECCV에 발표된 논문이고 feature extraction 부분은 CNN을 사용하긴 했지만 transformer를 활용하여 효과적으로 Object Detection을 수행하는 방법을 제안한 중요한 논문이라고 생각합니다. 이 논문에서는 detection 문제에서 anchor box나 NMS(Non Maximum Supression)와 같은 heuristic 하고 미분 불가능한 방법들이 많이 사용되고, 이로 인해서 유독 object detection 문제는 딥러닝의 철학인 end-to-end 방식으로 해결되지 못하고 있음을 지적하고 있습니다. 그 해결책으로 bounding box를 예측하는 문제를 set prediction problem(중복을 허용하지 않고, 순서에 무관함)으로 보고 transformer를 활용한 end-to-end 방식의 알고리즘을 제안하였습니다. anchor box도 필요없고 NMS도 필요없는 DETR 알고리즘의 자세한 내용이 알고싶으시면 영상을 참고해주세요!
영상링크: https://youtu.be/lXpBcW_I54U
논문링크: https://arxiv.org/abs/2005.12872
PR-297: Training data-efficient image transformers & distillation through att...Jinwon Lee
안녕하세요 TensorFlow Korea 논문 읽기 모임 PR-12의 297번째 리뷰입니다
어느덧 PR-12 시즌 3의 끝까지 논문 3편밖에 남지 않았네요.
시즌 3가 끝나면 바로 시즌 4의 새 멤버 모집이 시작될 예정입니다. 많은 관심과 지원 부탁드립니다~~
(멤버 모집 공지는 Facebook TensorFlow Korea 그룹에 올라올 예정입니다)
오늘 제가 리뷰한 논문은 Facebook의 Training data-efficient image transformers & distillation through attention 입니다.
Google에서 나왔던 ViT논문 이후에 convolution을 전혀 사용하지 않고 오직 attention만을 이용한 computer vision algorithm에 어느때보다 관심이 높아지고 있는데요
이 논문에서 제안한 DeiT 모델은 ViT와 같은 architecture를 사용하면서 ViT가 ImageNet data만으로는 성능이 잘 안나왔던 것에 비해서
Training 방법 개선과 새로운 Knowledge Distillation 방법을 사용하여 mageNet data 만으로 EfficientNet보다 뛰어난 성능을 보여주는 결과를 얻었습니다.
정말 CNN은 이제 서서히 사라지게 되는 것일까요? Attention이 computer vision도 정복하게 될 것인지....
개인적으로는 당분간은 attention 기반의 CV 논문이 쏟아질 거라고 확신하고, 또 여기에서 놀라운 일들이 일어날 수 있을 거라고 생각하고 있습니다
CNN은 10년간 많은 연구를 통해서 발전해왔지만, transformer는 이제 CV에 적용된 지 얼마 안된 시점이라서 더 기대가 크구요,
attention이 inductive bias가 가장 적은 형태의 모델이기 때문에 더 놀라운 이들을 만들 수 있을거라고 생각합니다
얼마 전에 나온 open AI의 DALL-E도 그 대표적인 예라고 할 수 있을 것 같습니다. Transformer의 또하나의 transformation이 궁금하신 분들은 아래 영상을 참고해주세요
영상링크: https://youtu.be/DjEvzeiWBTo
논문링크: https://arxiv.org/abs/2012.12877
Transformer Architectures in Vision
[2018 ICML] Image Transformer
[2019 CVPR] Video Action Transformer Network
[2020 ECCV] End-to-End Object Detection with Transformers
[2021 ICLR] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
PR-317: MLP-Mixer: An all-MLP Architecture for VisionJinwon Lee
Computer Vision 분야에서 CNN은 과연 살아남을 수 있을까요?
안녕하세요 TensorFlow Korea 논문 읽기 모임 PR-12의 317번째 논문 리뷰입니다.
이번에는 Google Research, Brain Team의 MLP-Mixer: An all-MLP Architecture for Vision을 리뷰해보았습니다.
Attention의 공격도 버거운데 이번에는 MLP(Multi-Layer Perceptron)의 공격입니다.
MLP만을 사용해서 Image Classification을 하는데 성능도 좋고 속도도 빠르고....
구조를 간단히 소개해드리면 ViT(Vision Transformer)의 self-attention 부분을 MLP로 변경하였습니다.
MLP block 2개를 사용하여 하나는 patch(token)들 간의 연산을 하는데 사용하고, 하나는 patch 내부 연산을 하는데 사용합니다.
사실 MLP를 사용하긴 했지만 논문에도 언급되어 있듯이, 이 부분을 일종의 convolution이라고 볼 수 있는데요...
그래도 transformer 기반의 network이 가질 수밖에 없는 quadratic complexity를 linear로 낮춰주고
convolution의 inductive bias 거의 없이 아주아주 simple한 구조를 활용하여 이렇게 좋은 성능을 보여준 점이 멋집니다.
반면에 역시나 data를 많이 써야 한다거나, MLP의 한계인 fixed length의 input만 받을 수 있다는 점은 단점이라고 생각하는데요,
이 연구를 시작으로 MLP도 다시한번 조명받는 계기가 되면 좋을 것 같네요
비슷한 시점에 나온 비슷한 연구들도 마지막에 간략하게 소개하였습니다.
재미있게 봐주세요. 감사합니다!
논문링크: https://arxiv.org/abs/2105.01601
영상링크: https://youtu.be/KQmZlxdnnuY
ResNet (short for Residual Network) is a deep neural network architecture that has achieved significant advancements in image recognition tasks. It was introduced by Kaiming He et al. in 2015.
The key innovation of ResNet is the use of residual connections, or skip connections, that enable the network to learn residual mappings instead of directly learning the desired underlying mappings. This addresses the problem of vanishing gradients that commonly occurs in very deep neural networks.
In a ResNet, the input data flows through a series of residual blocks. Each residual block consists of several convolutional layers followed by batch normalization and rectified linear unit (ReLU) activations. The original input to a residual block is passed through the block and added to the output of the block, creating a shortcut connection. This addition operation allows the network to learn residual mappings by computing the difference between the input and the output.
By using residual connections, the gradients can propagate more effectively through the network, enabling the training of deeper models. This enables the construction of extremely deep ResNet architectures with hundreds of layers, such as ResNet-101 or ResNet-152, while still maintaining good performance.
ResNet has become a widely adopted architecture in various computer vision tasks, including image classification, object detection, and image segmentation. Its ability to train very deep networks effectively has made it a fundamental building block in the field of deep learning.
PR-169: EfficientNet: Rethinking Model Scaling for Convolutional Neural NetworksJinwon Lee
TensorFlow-KR 논문읽기모임 PR12 169번째 논문 review입니다.
이번에 살펴본 논문은 Google에서 발표한 EfficientNet입니다. efficient neural network은 보통 mobile과 같은 제한된 computing power를 가진 edge device를 위한 작은 network 위주로 연구되어왔는데, 이 논문은 성능을 높이기 위해서 일반적으로 network를 점점 더 키워나가는 경우가 많은데, 이 때 어떻게 하면 더 효율적인 방법으로 network을 키울 수 있을지에 대해서 연구한 논문입니다. 자세한 내용은 영상을 참고해주세요
논문링크: https://arxiv.org/abs/1905.11946
영상링크: https://youtu.be/Vhz0quyvR7I
Variational Autoencoders For Image GenerationJason Anderson
Meetup: https://www.meetup.com/Cognitive-Computing-Enthusiasts/events/260580395/
Video: https://www.youtube.com/watch?v=fnULFOyNZn8
Blog: http://www.compthree.com/blog/autoencoder/
Code: https://github.com/compthree/variational-autoencoder
An autoencoder is a machine learning algorithm that represents unlabeled high-dimensional data as points in a low-dimensional space. A variational autoencoder (VAE) is an autoencoder that represents unlabeled high-dimensional data as low-dimensional probability distributions. In addition to data compression, the randomness of the VAE algorithm gives it a second powerful feature: the ability to generate new data similar to its training data. For example, a VAE trained on images of faces can generate a compelling image of a new "fake" face. It can also map new features onto input data, such as glasses or a mustache onto the image of a face that initially lacks these features. In this talk, we will survey VAE model designs that use deep learning, and we will implement a basic VAE in TensorFlow. We will also demonstrate the encoding and generative capabilities of VAEs and discuss their industry applications.
Swin Transformer가 최근 오브젝트디텍션 그리고 Semantic segmentation분야에서의 성능이 가장 좋은 모델 중 하나로
주목 받고 있습니다.
Swin Transformer nlp분야에서 많이 쓰이는 트랜스포머를 비전 분야에 적용한 모델로 Hierarchical feature maps과
Window-based Self-attention의 특징적입니다 Swin Transformer는 작년 구글에서 제안된 방법인
비전 트랜스포머의 한계점을 개선한 모델이라고 보시면 됩니다
트랜스포머의 한계란.. ㄷㄷ 이네요
이미지 처리팀의 김선옥님이 자세한 리뷰 도와주셨습니다!!
오늘도 많은 관심 미리 감사드립니다!!
https://youtu.be/L3sH9tjkvKI
Presentation for the Berlin Computer Vision Group, December 2020 on deep learning methods for image segmentation: Instance segmentation, semantic segmentation, and panoptic segmentation.
ConvNeXt: A ConvNet for the 2020s explainedSushant Gautam
Explained here: https://youtu.be/aBvDPL1jFnI
In Nepali
A ConvNet for the 2020s (Zhuang Liu et al.)
ComvNeXt paper
Deep Learning for Visual Intelligence
Sushant Gautam
MSCIISE
Department of Electronics and Computer Engineering
Institute of Engineering, Thapathali Campus
13 March 2022
To all the authors (obviously!!)
1. Jinwon Lee's slides at https://www.slideshare.net/JinwonLee9/pr366-a-convnet-for-2020s?qid=274bc524-23ae-4c13-b03b-0d2416976ad5&v=&b=&from_search=1
2. Letitia from AI Coffee Break: https://www.youtube.com/watch?v=SndHALawoag
I even edited some of her hard visual works and put them as a slide. :(
出典:Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko
Facebook AI
公開URL : https://arxiv.org/abs/2005.12872
概要:Detection Transformer(DETRという)という新しいフレームワークによって,non-maximum-supressionやアンカー生成のような人手で設計する必要なく、End-to-Endで画像からぶった検出を行う手法を提案しています。物体検出を直接集合予測問題として解くためのtransformerアーキテクチャとハンガリアン法を用いて二部マッチングを行い正解と予測の組み合わせを探索しています。Attentionを物体検出に応用しただけでなく、競合手法であるFaster R-CNNと同等の精度を達成しています。
Intro to selective search for object proposals, rcnn family and retinanet state of the art model deep dives for object detection along with MAP concept for evaluating model and how does anchor boxes make the model learn where to draw bounding boxes
Slides by Víctor Garcia about:
Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, Alexei A. Efros, "Image-to-Image Translation Using Conditional Adversarial Networks".
In arxiv, 2016.
https://phillipi.github.io/pix2pix/
We investigate conditional adversarial networks as a general-purpose solution to image-to-image translation problems. These networks not only learn the mapping from input image to output image, but also learn a loss function to train this mapping. This makes it possible to apply the same generic approach to problems that traditionally would require very different loss formulations. We demonstrate that this approach is effective at synthesizing photos from label maps, reconstructing objects from edge maps, and colorizing images, among other tasks. As a community, we no longer hand-engineer our mapping functions, and this work suggests we can achieve reasonable results without hand-engineering our loss functions either.
We investigate conditional adversarial networks as a general-purpose solution to image-to-image translation problems. These networks not only learn the mapping from input image to output image, but also learn a loss function to train this mapping. This makes it possible to apply the same generic approach to problems that traditionally would require very different loss formulations. We demonstrate that this approach is effective at synthesizing photos from label maps, reconstructing objects from edge maps, and colorizing images, among other tasks. As a community, we no longer hand-engineer our mapping functions, and this work suggests we can achieve reasonable results without hand-engineering our loss functions either.
How useful is self-supervised pretraining for Visual tasks?Seunghyun Hwang
Review : How useful is self-supervised pretraining for Visual tasks?
- by Seunghyun Hwang (Yonsei University, Severance Hospital, Center for Clinical Data Science)
PR-317: MLP-Mixer: An all-MLP Architecture for VisionJinwon Lee
Computer Vision 분야에서 CNN은 과연 살아남을 수 있을까요?
안녕하세요 TensorFlow Korea 논문 읽기 모임 PR-12의 317번째 논문 리뷰입니다.
이번에는 Google Research, Brain Team의 MLP-Mixer: An all-MLP Architecture for Vision을 리뷰해보았습니다.
Attention의 공격도 버거운데 이번에는 MLP(Multi-Layer Perceptron)의 공격입니다.
MLP만을 사용해서 Image Classification을 하는데 성능도 좋고 속도도 빠르고....
구조를 간단히 소개해드리면 ViT(Vision Transformer)의 self-attention 부분을 MLP로 변경하였습니다.
MLP block 2개를 사용하여 하나는 patch(token)들 간의 연산을 하는데 사용하고, 하나는 patch 내부 연산을 하는데 사용합니다.
사실 MLP를 사용하긴 했지만 논문에도 언급되어 있듯이, 이 부분을 일종의 convolution이라고 볼 수 있는데요...
그래도 transformer 기반의 network이 가질 수밖에 없는 quadratic complexity를 linear로 낮춰주고
convolution의 inductive bias 거의 없이 아주아주 simple한 구조를 활용하여 이렇게 좋은 성능을 보여준 점이 멋집니다.
반면에 역시나 data를 많이 써야 한다거나, MLP의 한계인 fixed length의 input만 받을 수 있다는 점은 단점이라고 생각하는데요,
이 연구를 시작으로 MLP도 다시한번 조명받는 계기가 되면 좋을 것 같네요
비슷한 시점에 나온 비슷한 연구들도 마지막에 간략하게 소개하였습니다.
재미있게 봐주세요. 감사합니다!
논문링크: https://arxiv.org/abs/2105.01601
영상링크: https://youtu.be/KQmZlxdnnuY
ResNet (short for Residual Network) is a deep neural network architecture that has achieved significant advancements in image recognition tasks. It was introduced by Kaiming He et al. in 2015.
The key innovation of ResNet is the use of residual connections, or skip connections, that enable the network to learn residual mappings instead of directly learning the desired underlying mappings. This addresses the problem of vanishing gradients that commonly occurs in very deep neural networks.
In a ResNet, the input data flows through a series of residual blocks. Each residual block consists of several convolutional layers followed by batch normalization and rectified linear unit (ReLU) activations. The original input to a residual block is passed through the block and added to the output of the block, creating a shortcut connection. This addition operation allows the network to learn residual mappings by computing the difference between the input and the output.
By using residual connections, the gradients can propagate more effectively through the network, enabling the training of deeper models. This enables the construction of extremely deep ResNet architectures with hundreds of layers, such as ResNet-101 or ResNet-152, while still maintaining good performance.
ResNet has become a widely adopted architecture in various computer vision tasks, including image classification, object detection, and image segmentation. Its ability to train very deep networks effectively has made it a fundamental building block in the field of deep learning.
PR-169: EfficientNet: Rethinking Model Scaling for Convolutional Neural NetworksJinwon Lee
TensorFlow-KR 논문읽기모임 PR12 169번째 논문 review입니다.
이번에 살펴본 논문은 Google에서 발표한 EfficientNet입니다. efficient neural network은 보통 mobile과 같은 제한된 computing power를 가진 edge device를 위한 작은 network 위주로 연구되어왔는데, 이 논문은 성능을 높이기 위해서 일반적으로 network를 점점 더 키워나가는 경우가 많은데, 이 때 어떻게 하면 더 효율적인 방법으로 network을 키울 수 있을지에 대해서 연구한 논문입니다. 자세한 내용은 영상을 참고해주세요
논문링크: https://arxiv.org/abs/1905.11946
영상링크: https://youtu.be/Vhz0quyvR7I
Variational Autoencoders For Image GenerationJason Anderson
Meetup: https://www.meetup.com/Cognitive-Computing-Enthusiasts/events/260580395/
Video: https://www.youtube.com/watch?v=fnULFOyNZn8
Blog: http://www.compthree.com/blog/autoencoder/
Code: https://github.com/compthree/variational-autoencoder
An autoencoder is a machine learning algorithm that represents unlabeled high-dimensional data as points in a low-dimensional space. A variational autoencoder (VAE) is an autoencoder that represents unlabeled high-dimensional data as low-dimensional probability distributions. In addition to data compression, the randomness of the VAE algorithm gives it a second powerful feature: the ability to generate new data similar to its training data. For example, a VAE trained on images of faces can generate a compelling image of a new "fake" face. It can also map new features onto input data, such as glasses or a mustache onto the image of a face that initially lacks these features. In this talk, we will survey VAE model designs that use deep learning, and we will implement a basic VAE in TensorFlow. We will also demonstrate the encoding and generative capabilities of VAEs and discuss their industry applications.
Swin Transformer가 최근 오브젝트디텍션 그리고 Semantic segmentation분야에서의 성능이 가장 좋은 모델 중 하나로
주목 받고 있습니다.
Swin Transformer nlp분야에서 많이 쓰이는 트랜스포머를 비전 분야에 적용한 모델로 Hierarchical feature maps과
Window-based Self-attention의 특징적입니다 Swin Transformer는 작년 구글에서 제안된 방법인
비전 트랜스포머의 한계점을 개선한 모델이라고 보시면 됩니다
트랜스포머의 한계란.. ㄷㄷ 이네요
이미지 처리팀의 김선옥님이 자세한 리뷰 도와주셨습니다!!
오늘도 많은 관심 미리 감사드립니다!!
https://youtu.be/L3sH9tjkvKI
Presentation for the Berlin Computer Vision Group, December 2020 on deep learning methods for image segmentation: Instance segmentation, semantic segmentation, and panoptic segmentation.
ConvNeXt: A ConvNet for the 2020s explainedSushant Gautam
Explained here: https://youtu.be/aBvDPL1jFnI
In Nepali
A ConvNet for the 2020s (Zhuang Liu et al.)
ComvNeXt paper
Deep Learning for Visual Intelligence
Sushant Gautam
MSCIISE
Department of Electronics and Computer Engineering
Institute of Engineering, Thapathali Campus
13 March 2022
To all the authors (obviously!!)
1. Jinwon Lee's slides at https://www.slideshare.net/JinwonLee9/pr366-a-convnet-for-2020s?qid=274bc524-23ae-4c13-b03b-0d2416976ad5&v=&b=&from_search=1
2. Letitia from AI Coffee Break: https://www.youtube.com/watch?v=SndHALawoag
I even edited some of her hard visual works and put them as a slide. :(
出典:Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko
Facebook AI
公開URL : https://arxiv.org/abs/2005.12872
概要:Detection Transformer(DETRという)という新しいフレームワークによって,non-maximum-supressionやアンカー生成のような人手で設計する必要なく、End-to-Endで画像からぶった検出を行う手法を提案しています。物体検出を直接集合予測問題として解くためのtransformerアーキテクチャとハンガリアン法を用いて二部マッチングを行い正解と予測の組み合わせを探索しています。Attentionを物体検出に応用しただけでなく、競合手法であるFaster R-CNNと同等の精度を達成しています。
Intro to selective search for object proposals, rcnn family and retinanet state of the art model deep dives for object detection along with MAP concept for evaluating model and how does anchor boxes make the model learn where to draw bounding boxes
Slides by Víctor Garcia about:
Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, Alexei A. Efros, "Image-to-Image Translation Using Conditional Adversarial Networks".
In arxiv, 2016.
https://phillipi.github.io/pix2pix/
We investigate conditional adversarial networks as a general-purpose solution to image-to-image translation problems. These networks not only learn the mapping from input image to output image, but also learn a loss function to train this mapping. This makes it possible to apply the same generic approach to problems that traditionally would require very different loss formulations. We demonstrate that this approach is effective at synthesizing photos from label maps, reconstructing objects from edge maps, and colorizing images, among other tasks. As a community, we no longer hand-engineer our mapping functions, and this work suggests we can achieve reasonable results without hand-engineering our loss functions either.
We investigate conditional adversarial networks as a general-purpose solution to image-to-image translation problems. These networks not only learn the mapping from input image to output image, but also learn a loss function to train this mapping. This makes it possible to apply the same generic approach to problems that traditionally would require very different loss formulations. We demonstrate that this approach is effective at synthesizing photos from label maps, reconstructing objects from edge maps, and colorizing images, among other tasks. As a community, we no longer hand-engineer our mapping functions, and this work suggests we can achieve reasonable results without hand-engineering our loss functions either.
How useful is self-supervised pretraining for Visual tasks?Seunghyun Hwang
Review : How useful is self-supervised pretraining for Visual tasks?
- by Seunghyun Hwang (Yonsei University, Severance Hospital, Center for Clinical Data Science)
Paper Explained: RandAugment: Practical automated data augmentation with a re...Devansh16
RandAugment: Practical automated data augmentation with a reduced search space is a paper that proposes a new Data Augmentation technique that outperforms all current techniques while being cheaper.
https://github.com/telecombcn-dl/dlmm-2017-dcu
Deep learning technologies are at the core of the current revolution in artificial intelligence for multimedia data analysis. The convergence of big annotated data and affordable GPU hardware has allowed the training of neural networks for data analysis tasks which had been addressed until now with hand-crafted features. Architectures such as convolutional neural networks, recurrent neural networks and Q-nets for reinforcement learning have shaped a brand new scenario in signal processing. This course will cover the basic principles and applications of deep learning to computer vision problems, such as image classification, object detection or text captioning.
A presentation on the "no new UNet" model, which attempts to automate hyper-parameter selection for medical image segmentation. The paper was accepted to Nature Methods.
Computer Vision abbreviated as CV aims to teach computers to achieve human level vision capabilities. Applications of CV in self driving cars, robotics, healthcare, education and the multitude of apps that allow customers to use the smartphone cameras to convey information has made it one of the most popular fields in Artificial Intelligence. The recent advances in Deep Learning, data storage and computing capabilities has lead to the huge success of CV. There are several tasks in computer vision, such as classification, object detection, image segmentation, optical character recognition, scene reconstruction and many others.
In this presentation I will talk about applying Transfer Learning, Image classification, object detection and the metrics required to measure them on still images. The increase in accuracy over of CV tasks over the past decade is due to Convolutional Neural Networks (CNN), CNN is the base used in architectures such as RESNET or VGGNET. I will go through how to use these pre-trained models for image classification and feature extraction. One of the break throughs in object detection has come with one-shot learning, where the bounding box and the class of the object is predicted simultaneously. This leads to low latency during inference (155 frames per second) and high accuracy. This is the framework behind object detection using YOLO , I will explain how to use yolo for specific use cases.
In this presentation I review various data science techniques and discuss their usefulness to pricing actuaries working in general insurance.
This presentation was originally given at the TIGI webinar in 2020.
https://www.actuaries.org.uk/learn-develop/attend-event/tigi-2020-technical-issues-general-insurance
PR-433: Test-time Training with Masked AutoencodersSunghoon Joo
#PR12 season 5 [PR-433] Test-time training with masked autoencoders
This slide is a review of the paper "Test-time training with masked autoencoders."
Reviewed by Sunghoon Joo
Paper link: https://arxiv.org/abs/2209.07522
Youtube link: https://youtu.be/zOJ68s0F6JY
For the full video of this presentation, please visit: https://www.edge-ai-vision.com/2021/10/dnn-training-data-how-to-know-what-you-need-and-how-to-get-it-a-presentation-from-tech-mahindra/
Abhishek Sharma, Practice Head for Engineering AI at Tech Mahindra, presents the “DNN Training Data: How to Know What You Need and How to Get It” tutorial at the May 2021 Embedded Vision Summit.
Successful training of deep neural networks requires the right amounts and types of annotated training data. Collecting, curating and labeling this data is typically one of the most time-consuming aspects of developing a deep-learning-based solution.
In this talk, Sharma discusses approaches useful for situations where insufficient data is available, including transfer learning and data augmentation, including the use of generative adversarial networks (GANs). He also discusses techniques that can be helpful when data is plentiful, such as transforms, data path optimization and approximate computing. He illustrates these techniques and challenges via case studies from the healthcare and manufacturing industries.
In this video I’m going to show you how SigOpt can help you amplify your machine learning and AI models by optimally tuning them using our black-box optimization platform.
Video: https://youtu.be/EjGrRxXWg8o
The SigOpt platform provides an ensemble of state-of-the-art Bayesian and Global optimization algorithms via a simple Software-as-a-Service API.
Similar to PR-330: How To Train Your ViT? Data, Augmentation, and Regularization in Vision Transformers (20)
#PR12 #PR366
안녕하세요 논문 읽기 모임 PR-12의 366번째 논문리뷰입니다.
올해가 AlexNet이 나온지 10주년이 되는 해네요.
AlexNet이 2012년에 혜성처럼 등장한 이후, Solve computer vision problem = Use CNN이 공식처럼 사용되던 2010년대가 가고
2020년대 들어서 ViT의 등장을 시작으로 Transformer 기반의 network들이 CNN의 자리를 위협하고 상당부분 이미 뺏어간 상황입니다.
2020년대에 CNN의 가야할 길은 어디일까요?
Inductive bias가 적은 Transformer가 대용량의 데이터로 학습하면 항상 CNN보다 더 낫다는 건 진실일까요?
이 논문에서는 2020년대를 위한 CNN이라는 제목으로 ConvNeXt라는 새로운(?) architecture를 제안합니다.
사실 새로운 건 없고 그동안 있었던 것들과 Transformer에서 적용한 것들을 copy해와서 CNN에 적용해보았는데요,
Transformer보다 성능도 좋고 속도도 빠른 결과가 나왔다고 합니다.
결과에 대해서 약간의 논란이 twitter 상에서 나오고 있는데 이 부분 포함해서 자세한 내용은 영상을 통해서 보실 수 있습니다.
늘 재밌게 봐주시고 좋아요 댓글 구독 해주시는 분들께 감사드립니다 :)
논문링크: https://arxiv.org/abs/2201.03545
영상링크: https://youtu.be/Mw7IhO2uBGc
PR-355: Masked Autoencoders Are Scalable Vision LearnersJinwon Lee
#PR12 #PR355
안녕하세요 논문 읽기 모임 PR-12의 355번째 논문리뷰입니다.
Computer Vision 분야에는 왜 BERT나 GPT 같은 model이 없을까요?
Self-supervised learning을 이용하여 pretraining 한 후, downstream task에서 supervised learning보다 성능이 잘나오는 model을 언제쯤 보게 될까요?
어쩌면 그 model 이 논문에 있을 수도 있습니다.
이 논문에서는 ViT 기반의 Autoencoder를 활용하여 ImageNet-1K training set을 이용하여 self-supervised pretraining으로 SOTA(ImageNet-1K only)를 달성하였습니다.
image를 patch로 만들고 75%의 patch를 masking한 후 25%의 patch만으로 masking된 75%의 pixel 값을 직접 예측하는 형태를 사용하였고,
다른 model들에 비하여 연산량과 memory 사용량이 적어서 big model로의 확장도 용이합니다.
재미있는 아이디어와 다양한 실험결과가 있으니 자세한 내용은 발표 영상을 참고해주세요!
영상링크: https://youtu.be/mtUa3AAxPNQ
논문링크: https://arxiv.org/abs/2111.06377v1
PR-344: A Battle of Network Structures: An Empirical Study of CNN, Transforme...Jinwon Lee
#PR12 #PR344
안녕하세요 TensorFlow Korea 논문 읽기 모임 PR-12의 344번째 논문 리뷰입니다.
오늘은 중국과기대와 MSRA에서 나온 A Battle of Network Structures라는 강렬한 제목을 가진 논문입니다.
부제에서 잘 나와있듯이 이 논문은 computer vision에서 CNN, Transformer, MLP에 대해서 같은 환경에서 비교를 통해 어떤 특징들이 있는지를 알아본 논문입니다.
우선 같은 조건에서 실험하기 위하여 SPACH라는 unified framework을 만들고 그 안에 CNN, Transformer, MLP를 넣어서 실험을 합니다.
셋 모두 조건이 잘 갖춰지면 비슷한 성능을 내지만, MLP는 model size가 커지면 overfitting이 발생하고
CNN은 Transformer에 비해서 적은 data에서도 좋은 성능이 나오는 generalization capability가 좋고,
Transformer는 model capacity가 커서 data가 충분하고 연산량도 큰 환경에서 잘한다는 것이 실험의 한가지 결과입니다.
또하나는 global receptive field를 갖는 transformer나 MLP의 경우에도 local한 연산을 하는 local model을 같이 써줄때에 성능이 좋아진다는 것입니다.
이런 insight들을 통해서 이 논문에서는 CNN과 Transformer를 결합한 형태의 Hybrid model을 제안하여 SOTA 성능을 낼 수 있음을 보여줍니다.
개인적으로 놀랄만한 insight를 발견한 것은 아니었지만 세가지 network의 특징과 장단점에 대해서 정리해볼 수 있는 그런 논문이라고 평하고 싶습니다.
자세한 내용은 영상을 참고해주세요! 감사합니다
영상링크: https://youtu.be/NVLMZZglx14
논문링크: https://arxiv.org/abs/2108.13002
PR-270: PP-YOLO: An Effective and Efficient Implementation of Object DetectorJinwon Lee
TensorFlow Korea 논문읽기모임 PR12 270번째 논문 review입니다.
이번 논문은 Baidu에서 나온 PP-YOLO: An Effective and Efficient Implementation of Object Detector입니다. YOLOv3에 다양한 방법을 적용하여 매우 높은 성능과 함께 매우 빠른 속도 두마리 토끼를 다 잡아버린(?) 그런 논문입니다. 논문에서 사용한 다양한 trick들에 대해서 좀 더 깊이있게 살펴보았습니다. Object detection에 사용된 기법 들 중에 Deformable convolution, Exponential Moving Average, DropBlock, IoU aware prediction, Grid sensitivity elimination, MatrixNMS, CoordConv, 등의 방법에 관심이 있으시거나 알고 싶으신 분들은 영상과 발표자료를 참고하시면 좋을 것 같습니다!
논문링크: https://arxiv.org/abs/2007.12099
영상링크: https://youtu.be/7v34cCE5H4k
PR-258: From ImageNet to Image Classification: Contextualizing Progress on Be...Jinwon Lee
TensorFlow Korea 논문읽기모임 PR12 258번째 논문 review입니다.
이번 논문은 MIT에서 나온 From ImageNet to Image Classification: Contextualizing Progress on Benchmarks입니다.
Deep Learning 하시는 분들이면 ImageNet 모르시는 분들이 없을텐데요, 이 논문은 ImageNet의 labeling 방법의 한계와 문제점에 대해서 얘기하고 top-1 accuracy 기반의 평가 방법에도 문제가 있을 수 있음을 지적하고 있습니다.
ImageNet data의 20% 이상이 multi object를 포함하고 있지만 그 중에 하나만 정답으로 인정되는 문제가 있고, annotation 방법의 한계로 인하여 실제로 사람이 생각하는 것과 다른 class가 정답으로 labeling되어 있는 경우도 많았습니다. 또한 terrier만 20종이 넘는 등 전문가가 아니면 판단하기 어려운 label도 많다는 문제도 있었구요. 이 밖에도 다양한 실험을 통해서 정량적인 분석과 함께 human-in-the-loop을 이용한 평가로 현재 model들의 성능이 어디까지 와있는지, 그리고 앞으로 더 높은 성능을 내기 위해서 data labeling 측면에서 해결해야할 과제는 무엇인지에 대해서 이야기하고 있습니다. 논문이 양이 좀 많긴 하지만 기술적인 내용이 별로 없어서 쉽게 읽으실 수 있는데요, 자세한 내용이 궁금하신 분들은 영상을 참고해주세요!
논문링크: https://arxiv.org/abs/2005.11295
발표영상링크: https://youtu.be/CPMgX5ikL_8
TensorFlow Korea 논문읽기모임 PR12 243째 논문 review입니다
이번 논문은 RegNet으로 알려진 Facebook AI Research의 Designing Network Design Spaces 입니다.
CNN을 디자인할 때, bottleneck layer는 정말 좋을까요? layer 수는 많을 수록 높은 성능을 낼까요? activation map의 width, height를 절반으로 줄일 때(stride 2 혹은 pooling), channel을 2배로 늘려주는데 이게 최선일까요? 혹시 bottleneck layer가 없는 게 더 좋지는 않은지, 최고 성능을 내는 layer 수에 magic number가 있는 건 아닐지, activation이 절반으로 줄어들 때 channel을 2배가 아니라 3배로 늘리는 게 더 좋은건 아닌지?
이 논문에서는 하나의 neural network을 잘 design하는 것이 아니라 Auto ML과 같은 기술로 좋은 neural network을 찾을 수 있는 즉 좋은 neural network들이 살고 있는 좋은 design space를 design하는 방법에 대해서 얘기하고 있습니다. constraint이 거의 없는 design space에서 human-in-the-loop을 통해 좋은 design space로 그 공간을 좁혀나가는 방법을 제안하였는데요, EfficientNet보다 더 좋은 성능을 보여주는 RegNet은 어떤 design space에서 탄생하였는지 그리고 그 과정에서 우리가 당연하게 여기고 있었던 design choice들이 잘못된 부분은 없었는지 아래 동영상에서 확인하실 수 있습니다~
영상링크: https://youtu.be/bnbKQRae_u4
논문링크: https://arxiv.org/abs/2003.13678
PR-217: EfficientDet: Scalable and Efficient Object DetectionJinwon Lee
TensorFlow Korea 논문읽기모임 PR12 217번째 논문 review입니다
이번 논문은 GoogleBrain에서 쓴 EfficientDet입니다. EfficientNet의 후속작으로 accuracy와 efficiency를 둘 다 잡기 위한 object detection 방법을 제안한 논문입니다. 이를 위하여 weighted bidirectional feature pyramid network(BiFPN)과 EfficientNet과 유사한 방법의 detection용 compound scaling 방법을 제안하고 있는데요, 자세한 내용은 영상을 참고해주세요
논문링크: https://arxiv.org/abs/1911.09070
영상링크: https://youtu.be/11jDC8uZL0E
PR-207: YOLOv3: An Incremental ImprovementJinwon Lee
TensorFlow Korea 논문읽기모임 PR12 207번째 논문 review입니다
이번 논문은 YOLO v3입니다.
매우 유명한 논문이라서 크게 부연설명이 필요없을 것 같은데요, Object Detection algorithm들 중에 YOLO는 굉장히 특색있는 one-stage algorithm입니다. 이 논문에서는 YOLO v2(YOLO9000) 이후에 성능 향상을 위하여 어떤 것들을 적용하였는지 하나씩 설명해주고 있습니다. 또한 MS COCO의 metric인 average mAP에 대해서 비판하면서 mAP를 평가하는 방법에 대해서도 얘기를 하고 있는데요, 자세한 내용은 영상을 참고해주세요~
논문링크: https://arxiv.org/abs/1804.02767
영상링크: https://youtu.be/HMgcvgRrDcA
PR-197: One ticket to win them all: generalizing lottery ticket initializatio...Jinwon Lee
TensorFlow Korea 논문읽기모임 PR12 197번째 논문 review입니다
(2기 목표 200편까지 이제 3편이 남았습니다)
이번에 제가 발표한 논문은 FAIR(Facebook AI Research)에서 나온 One ticket to win them all: generalizing lottery ticket initializations across datasets and optimizers 입니다
한 장의 ticket으로 모든 복권에서 1등을 할 수 있다면 얼마나 좋을까요?
일반적인 network pruning 방법은 pruning 하기 이전에 학습된 network weight를 그대로 사용하면서 fine tuning하는 방법을 사용해왔습니다
pruning한 이후에 network에 weight를 random intialization한 후 학습하면 성능이 잘 나오지 않는 문제가 있었는데요
작년 MIT에서 나온 Lottery ticket hypothesis라는 논문에서는 이렇게 pruning된 이후의 network를 어떻게 random intialization하면 높은 성능을 낼 수 있는지
이 intialization 방법을 공개하며 lottery ticket의 winning ticket이라고 이름붙였습니다.
그런데 이 winning ticket이 혹시 다른 dataset이나 다른 optimizer를 사용하는 경우에도 잘 동작할 수 있을까요?
예를 들어 CIFAR10에서 찾은 winning ticket이 ImageNet에서도 winning ticket의 성능을 나타낼 수 있을까요?
이 논문은 이러한 질문에 대한 답을 실험을 통해서 확인하였고, initialization에 대한 여러가지 insight를 담고 있습니다.
자세한 내용은 발표 영상을 참고해주세요~!
영상링크: https://youtu.be/YmTNpF2OOjA
발표자료링크: https://www.slideshare.net/JinwonLee9/pr197-one-ticket-to-win-them-all-generalizing-lottery-ticket-initializations-across-datasets-and-optimizers
논문링크: https://arxiv.org/abs/1906.02773
PR-183: MixNet: Mixed Depthwise Convolutional KernelsJinwon Lee
TensorFlow-KR 논문읽기모임 PR12(12PR) 183번째 논문 review입니다.
이번에 살펴볼 논문은 Google Brain에서 발표한 MixNet입니다. Efficiency를 추구하는 CNN에서 depthwise convolution이 많이 사용되는데, 이 때 depthwise convolution filter의 size를 다양하게 해서 성능도 높이고 efficiency도 높이는 방법을 제안한 논문입니다. 자세한 내용은 영상을 참고해주세요
논문링크 : https://arxiv.org/abs/1907.09595
발표영상 : https://youtu.be/252YxqpHzsg
PR-155: Exploring Randomly Wired Neural Networks for Image RecognitionJinwon Lee
TensorFlow-KR 논문읽기모임 PR12 155번째 논문 review 입니다.
이번에는 Facebook AI Research에서 최근에 나온(4/2) Exploring Randomly Wired Neural Networks for Image Recognition을 review해 보았습니다. random하게 generation된 network이 그동안 사람들이 온갖 노력을 들여서 만든 network 이상의 성능을 나타낸다는 결과로 많은 사람들에게 충격을 준 논문인데요, 자세한 내용은 자료와 영상을 참고해주세요
논문링크: https://arxiv.org/abs/1904.01569
영상링크: https://youtu.be/NrmLteQ5BC4
PR-144: SqueezeNext: Hardware-Aware Neural Network DesignJinwon Lee
Tensorfkow-KR 논문읽기모임 PR12 144번째 논문 review입니다.
이번에는 Efficient CNN의 대표 중 하나인 SqueezeNext를 review해보았습니다. SqueezeNext의 전신인 SqueezeNet도 같이 review하였고, CNN을 평가하는 metric에 대한 논문인 NetScore에서 SqueezeNext가 1등을 하여 NetScore도 같이 review하였습니다.
논문링크:
SqueezeNext - https://arxiv.org/abs/1803.10615
SqueezeNet - https://arxiv.org/abs/1602.07360
NetScore - https://arxiv.org/abs/1806.05512
영상링크: https://youtu.be/WReWeADJ3Pw
PR095: Modularity Matters: Learning Invariant Relational Reasoning TasksJinwon Lee
Tensorflow-KR 논문읽기모임 95번째 발표영상입니다
Modularity Matters라는 제목으로 visual relational reasoning 문제를 풀 수 있는 방법을 제시한 논문입니다. 기존 CNN들이 이런 문제이 취약함을 보여주고 이를 해결하기 위한 방법을 제시합니다. 관심있는 주제이기도 하고 Bengio 교수님 팀에서 쓴 논문이라서 review 해보았습니다
발표영상: https://youtu.be/dAGI3mlOmfw
논문링크: https://arxiv.org/abs/1806.06765
Kubernetes & AI - Beauty and the Beast !?! @KCD Istanbul 2024Tobias Schneck
As AI technology is pushing into IT I was wondering myself, as an “infrastructure container kubernetes guy”, how get this fancy AI technology get managed from an infrastructure operational view? Is it possible to apply our lovely cloud native principals as well? What benefit’s both technologies could bring to each other?
Let me take this questions and provide you a short journey through existing deployment models and use cases for AI software. On practical examples, we discuss what cloud/on-premise strategy we may need for applying it to our own infrastructure to get it to work from an enterprise perspective. I want to give an overview about infrastructure requirements and technologies, what could be beneficial or limiting your AI use cases in an enterprise environment. An interactive Demo will give you some insides, what approaches I got already working for real.
UiPath Test Automation using UiPath Test Suite series, part 4DianaGray10
Welcome to UiPath Test Automation using UiPath Test Suite series part 4. In this session, we will cover Test Manager overview along with SAP heatmap.
The UiPath Test Manager overview with SAP heatmap webinar offers a concise yet comprehensive exploration of the role of a Test Manager within SAP environments, coupled with the utilization of heatmaps for effective testing strategies.
Participants will gain insights into the responsibilities, challenges, and best practices associated with test management in SAP projects. Additionally, the webinar delves into the significance of heatmaps as a visual aid for identifying testing priorities, areas of risk, and resource allocation within SAP landscapes. Through this session, attendees can expect to enhance their understanding of test management principles while learning practical approaches to optimize testing processes in SAP environments using heatmap visualization techniques
What will you get from this session?
1. Insights into SAP testing best practices
2. Heatmap utilization for testing
3. Optimization of testing processes
4. Demo
Topics covered:
Execution from the test manager
Orchestrator execution result
Defect reporting
SAP heatmap example with demo
Speaker:
Deepak Rai, Automation Practice Lead, Boundaryless Group and UiPath MVP
PHP Frameworks: I want to break free (IPC Berlin 2024)Ralf Eggert
In this presentation, we examine the challenges and limitations of relying too heavily on PHP frameworks in web development. We discuss the history of PHP and its frameworks to understand how this dependence has evolved. The focus will be on providing concrete tips and strategies to reduce reliance on these frameworks, based on real-world examples and practical considerations. The goal is to equip developers with the skills and knowledge to create more flexible and future-proof web applications. We'll explore the importance of maintaining autonomy in a rapidly changing tech landscape and how to make informed decisions in PHP development.
This talk is aimed at encouraging a more independent approach to using PHP frameworks, moving towards a more flexible and future-proof approach to PHP development.
Software Delivery At the Speed of AI: Inflectra Invests In AI-Powered QualityInflectra
In this insightful webinar, Inflectra explores how artificial intelligence (AI) is transforming software development and testing. Discover how AI-powered tools are revolutionizing every stage of the software development lifecycle (SDLC), from design and prototyping to testing, deployment, and monitoring.
Learn about:
• The Future of Testing: How AI is shifting testing towards verification, analysis, and higher-level skills, while reducing repetitive tasks.
• Test Automation: How AI-powered test case generation, optimization, and self-healing tests are making testing more efficient and effective.
• Visual Testing: Explore the emerging capabilities of AI in visual testing and how it's set to revolutionize UI verification.
• Inflectra's AI Solutions: See demonstrations of Inflectra's cutting-edge AI tools like the ChatGPT plugin and Azure Open AI platform, designed to streamline your testing process.
Whether you're a developer, tester, or QA professional, this webinar will give you valuable insights into how AI is shaping the future of software delivery.
Search and Society: Reimagining Information Access for Radical FuturesBhaskar Mitra
The field of Information retrieval (IR) is currently undergoing a transformative shift, at least partly due to the emerging applications of generative AI to information access. In this talk, we will deliberate on the sociotechnical implications of generative AI for information access. We will argue that there is both a critical necessity and an exciting opportunity for the IR community to re-center our research agendas on societal needs while dismantling the artificial separation between the work on fairness, accountability, transparency, and ethics in IR and the rest of IR research. Instead of adopting a reactionary strategy of trying to mitigate potential social harms from emerging technologies, the community should aim to proactively set the research agenda for the kinds of systems we should build inspired by diverse explicitly stated sociotechnical imaginaries. The sociotechnical imaginaries that underpin the design and development of information access technologies needs to be explicitly articulated, and we need to develop theories of change in context of these diverse perspectives. Our guiding future imaginaries must be informed by other academic fields, such as democratic theory and critical theory, and should be co-developed with social science scholars, legal scholars, civil rights and social justice activists, and artists, among others.
Connector Corner: Automate dynamic content and events by pushing a buttonDianaGray10
Here is something new! In our next Connector Corner webinar, we will demonstrate how you can use a single workflow to:
Create a campaign using Mailchimp with merge tags/fields
Send an interactive Slack channel message (using buttons)
Have the message received by managers and peers along with a test email for review
But there’s more:
In a second workflow supporting the same use case, you’ll see:
Your campaign sent to target colleagues for approval
If the “Approve” button is clicked, a Jira/Zendesk ticket is created for the marketing design team
But—if the “Reject” button is pushed, colleagues will be alerted via Slack message
Join us to learn more about this new, human-in-the-loop capability, brought to you by Integration Service connectors.
And...
Speakers:
Akshay Agnihotri, Product Manager
Charlie Greenberg, Host
Transcript: Selling digital books in 2024: Insights from industry leaders - T...BookNet Canada
The publishing industry has been selling digital audiobooks and ebooks for over a decade and has found its groove. What’s changed? What has stayed the same? Where do we go from here? Join a group of leading sales peers from across the industry for a conversation about the lessons learned since the popularization of digital books, best practices, digital book supply chain management, and more.
Link to video recording: https://bnctechforum.ca/sessions/selling-digital-books-in-2024-insights-from-industry-leaders/
Presented by BookNet Canada on May 28, 2024, with support from the Department of Canadian Heritage.
Accelerate your Kubernetes clusters with Varnish CachingThijs Feryn
A presentation about the usage and availability of Varnish on Kubernetes. This talk explores the capabilities of Varnish caching and shows how to use the Varnish Helm chart to deploy it to Kubernetes.
This presentation was delivered at K8SUG Singapore. See https://feryn.eu/presentations/accelerate-your-kubernetes-clusters-with-varnish-caching-k8sug-singapore-28-2024 for more details.
Key Trends Shaping the Future of Infrastructure.pdfCheryl Hung
Keynote at DIGIT West Expo, Glasgow on 29 May 2024.
Cheryl Hung, ochery.com
Sr Director, Infrastructure Ecosystem, Arm.
The key trends across hardware, cloud and open-source; exploring how these areas are likely to mature and develop over the short and long-term, and then considering how organisations can position themselves to adapt and thrive.
Smart TV Buyer Insights Survey 2024 by 91mobiles.pdf91mobiles
91mobiles recently conducted a Smart TV Buyer Insights Survey in which we asked over 3,000 respondents about the TV they own, aspects they look at on a new TV, and their TV buying preferences.
LF Energy Webinar: Electrical Grid Modelling and Simulation Through PowSyBl -...DanBrown980551
Do you want to learn how to model and simulate an electrical network from scratch in under an hour?
Then welcome to this PowSyBl workshop, hosted by Rte, the French Transmission System Operator (TSO)!
During the webinar, you will discover the PowSyBl ecosystem as well as handle and study an electrical network through an interactive Python notebook.
PowSyBl is an open source project hosted by LF Energy, which offers a comprehensive set of features for electrical grid modelling and simulation. Among other advanced features, PowSyBl provides:
- A fully editable and extendable library for grid component modelling;
- Visualization tools to display your network;
- Grid simulation tools, such as power flows, security analyses (with or without remedial actions) and sensitivity analyses;
The framework is mostly written in Java, with a Python binding so that Python developers can access PowSyBl functionalities as well.
What you will learn during the webinar:
- For beginners: discover PowSyBl's functionalities through a quick general presentation and the notebook, without needing any expert coding skills;
- For advanced developers: master the skills to efficiently apply PowSyBl functionalities to your real-world scenarios.
The Art of the Pitch: WordPress Relationships and SalesLaura Byrne
Clients don’t know what they don’t know. What web solutions are right for them? How does WordPress come into the picture? How do you make sure you understand scope and timeline? What do you do if sometime changes?
All these questions and more will be explored as we talk about matching clients’ needs with what your agency offers without pulling teeth or pulling your hair out. Practical tips, and strategies for successful relationship building that leads to closing the deal.
De-mystifying Zero to One: Design Informed Techniques for Greenfield Innovati...
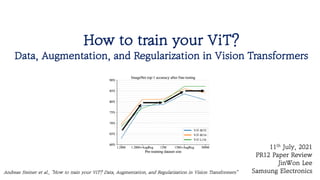
PR-330: How To Train Your ViT? Data, Augmentation, and Regularization in Vision Transformers
1. How to train your ViT?
Data, Augmentation, and Regularization in Vision Transformers
Andreas Steiner et al., “How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers”
11th July, 2021
PR12 Paper Review
JinWon Lee
Samsung Electronics
2. Introduction
• ViT has recently emerged as a competitive alternative to
convolutional neural networks.
• Without the translational equivariance of CNNs, ViT models are
generally found to perform best in settings with large amounts of
training data[ViT] or to require strong AugReg(Augmentation and
Reegularization) schemes[DeiT] to avoid overfitting.
• There was no comprehensive study of the trade-offs between model
regularization, data augmentation, training data size and compute
budget in Vision Transformers.
3. Introduction
• The authors pre-train a large collection of ViT models on datasets of
different sizes, while at the same time performing comparisons across
different amounts of regularization and data augmentation.
• The homogeneity of the performed study constitutes one of the key
contributions of this paper.
• The insights from this study constitute another important
contribution of this paper.
4. More than 50,000 ViT Models
• https://github.com/google-research/vision_transformer
• https://github.com/rwightman/pytorch-image-models
5. Scope of the Study
• Pre-training models on large datasets once and re-using their
parameters as initialization or a part of the model as feature
extractors in models trained on a broad variety of other tasks become
common practice in computer vision.
• In this setup, there are multiple ways to characterize computational
and sample efficiency.
▪ One approach is to look at the overall computational and sample cost of both
pre-training and fine-tuning. Normally, pre-training cost will dominate overall
costs. This interpretation is valid in specific scenarios, especially when pre-
training needs to be done repeatedly or reproduced for academic/industrial
purposes.
6. Scope of the Study
▪ However, in the majority of cases the pre-trained model can be downloaded
or, in the worst case, trained once in a while. Contrary, in these cases, the
budget required for adapting this model may become the main bottleneck.
▪ A more extreme viewpoint is that the training cost is not crucial, and all what
matters is eventual inference cost of the trained model, deployment cost
which will amortize all other costs.
• Overall, there are three major viewpoints on what is considered to be
the central cost of training a vision model. In this study we touch on
all three of them, but mostly concentrate on “practioner’s” and
“deployment” costs.
7. Experimental Setup
• Datasets and metrics
▪ For pre-training
➢ImageNet-21k – approximately 14M images with about 21,000 categories.
➢ImageNet-1k – a subset of ImageNet-21k consisting of about 1.3M training images and
1000 categories.
➢De-duplicate images in ImageNet-21k with respect to the test sets of the downstream
tasks
➢ImageNet V2 are used for valuation purposes.
▪ For transfer learning
➢4 popular computer vision datasets from the VTAB benchmark
• CIFAR-100, Oxford IIIT Pets(or Pets37 for short), Resisc45 and Kitti-distance
▪ Top-1 classification accuracy is used as main metric.
8. Experimental Setup
• Models
▪ 4 different configuration: ViT-Ti, ViT-S, ViT-B and ViT-L.
▪ Patch-size 16 for all models, and additionally patch-size 32 for the ViT-S and ViT-B.
▪ The hidden layer in the head of ViT is dropped, as empirically it does not lead to
more accurate models and often results in optimization instabilities.
▪ Hybrid models that first process images with ResNet and then feed the spatial
output to a ViT as the initial patch embeddings are used.
▪ Rn+{Ti,S,L}/p when n counts the number of convolutions and p denotes the
patch-size in the input image.
9. Experimental Setup
• Regularization and data augmentations
▪ Dropout to intermediate activations of ViT and the stochastic depth
regularization technique are applied.
▪ For data augmentation, Mixup and RandAugment are applied. 𝛼 is a Mixup
parameter and 𝑙, 𝑚 are number of augmentation layers and magnitude
respectively in RandAugment.
▪ Weight decay is used too.
▪ Sweep contains 28 configurations, which is a cross-product of the followings.
➢No dropout/no stochastic depth or dropout with prob. 0.1 and stochastic depth with
maximal layer dropping prob. 0.1
➢7 data augmentation setups for (𝑙, 𝑚, 𝛼): none (0,0,0), light1 (2,0,0), light2 (2,10,0.2),
medium1 (2,15,0.2), medium2 (2,15,0.5), strong1 (2,20,0.5), strong(2,20,0.8)
➢Weight decay: 0.1 or 0.03
10. Experimental Setup
• Pre-training
▪ Models were pre-trained with Adam, with a batch size of 4096 and a cosine
learning rate schedule with a linear warmup.
▪ To stabilize training, gradients were clipped at global norm 1.
▪ The images are pre-processed by Inception-style cropping and random
horizontal flipping.
▪ ImageNet-1k was trained for 300 epochs and ImageNet-21k dataset was
trained for 30 and 300 epochs. This allows us to examine the effects of the
increased dataset size also with a roughly constant total compute used for
pre-training.
11. Experimental Setup
• Fine-tuning
▪ Models were fine-tuned with SGD with a momentum of 0.9, sweeping over 2-
3 learning rates and 1-2 training durations per dataset.
▪ A fixed batch size of 512 was used, gradients were clipped at global norm 1
and a cosine learning rate schedule with linear warmup was also used.
▪ Fine-tuning was done both at the original resolution (224), as well as at a
higher resolution (384).
12. Findings - Scaling datasets with AugReg and
compute
• Best models trained on AugReg ImageNet-
1k perform about equal to the same
models pre-trained on the 10x larger plain
ImageNet-21k dataset. Similarly, best
models trained on AugReg ImageNet-21k,
when compute is also increased, match or
outperform those from which were trained
on the plain JFT-300M dataset with 25x
more images.
13. Findings - Scaling datasets with AugReg and
compute
• It is possible to match these private results with a publicly available
dataset, and it is imaginable that training longer and with AugReg on
JFT-300M might further increase performance.
• These results cannot hold for arbitrarily small datasets. Training a
ResNet50 on only 10% of ImageNet-1k with heavy data augmentation
improves results, but does not recover training on the full dataset.
Table 5. from “Unsupervised Data Augmentation for Consistency Training”
14. Findings – Transfer is the better option
• For most practical purposes, transferring a pre-trained model is both
more cost-efficient and leads to better results.
• The most striking finding is that, no matter how much training time is
spent, for the tiny Pet37 dataset, it does not seem possible to train
ViT models from scratch to reach accuracy anywhere near that of
transferred models.
15. Findings – Transfer is the better option
• For the larger Resisc45 dataset, this result still holds, although spending
two orders of magnitude more compute and performing a heavy search
may come close (but not reach) to the accuracy of pre-trained models.
• Notably, this does not account for the exploration cost which is difficult
to quantify.
16. Findings – More data yields more generic models
• Interestingly, the model pre-trained on ImageNet-21k(30 ep) is
significantly better than the ImageNet-1k(300 ep) one, across all the
three VTAB categories.
• As the compute budget keeps growing, we observe consistent
improvements on ImageNet-21k dataset with 10x longer schedule.
• Overall, we conclude that more data yields more generic models, the
trend holds across very diverse tasks.
17. Findings – Prefer augmentation to regularization
• The authors aim to discover general patterns for data augmentation and
regularization that can be used as rules of thumb when applying Vision
Transformers to a new task.
• The colour of a cell encodes its improvement or deterioration in score
when compared to the unregularized, unaugmented setting.
18. Findings – Prefer augmentation to regularization
• The first observation that becomes visible, is that for the mid-sized
ImageNet-1k dataset, any kind of AugReg helps.
• However, when using the 10x larger ImageNet-21k dataset and
keeping compute fixed, i.e. running for 30 epochs, any kind of AugReg
hurts performance for all but the largest models.
19. Findings – Prefer augmentation to regularization
• It is only when also increasing the computation budget to 300 epochs
that AugReg helps more models, although even then, it continues
hurting the smaller ones.
• Generally speaking, there are significantly more cases where adding
augmentation helps, than where adding regularization helps.
20. Findings – Prefer augmentation to regularization
• Below figure tells us that when using ImageNet-21k, regularization
hurts almost across the board.
21. Findings – Choosing which pre-trained model to
transfer
• When pre-training ViT models, various regularization and data
augmentation settings result in models with drastically different
performance.
• Then, from the practitioner’s point of view, a natural question
emerges: how to select a model for further adaption for an end
application?
• One way is to run for all available pre-trained models and then select
the best performing model, based on the validation score on the
downstream task of interest. This could be quite expensive in practice.
• Alternatively, one can select a single pre-trained model based on the
upstream validation accuracy and then only use this model for
adaptation, which is much cheaper.
22. Findings – Choosing which pre-trained model to
transfer
• Below figure shows the performance difference between the cheaper
strategy and the more expensive strategy.
• The results are mixed, but generally reflect that the cheaper strategy works
equally well as the more expensive strategy in the majority of scenarios.
• Selecting a single pre-trained model based on the upstream score is a cost-
effective practical strategy.
23. Findings – Choosing which pre-trained model to
transfer
• For every architecture and upstream dataset, the best model selected
by upstream validation accuracy.
• Bold numbers indicate results that are on par or surpass the
published JFT-300M results without AugReg for the same models.
24. Findings – Prefer increasing patch-size to
shrinking model-size
• Models containing the “Tiny” variants perform
significantly worse than the similarly fast larger
models with “/32” patch-size.
• For a given resolution, the patch-size influences
the amount of tokens on which self-attention is
performed and, thus, is a contributor to model
capacity which is not reflected by parameter
count.
• Parameter count is reflective neither of speed,
nor of capacity.
25. Conclusion
• This paper conduct the first systematic, large scale study of the
interplay between regularization, data augmentation, model size, and
training data size when pre-training ViTs.
• These experiments yield a number of surprising insights around the
impact of various techniques and the situations when augmentation
and regularization are beneficial and when not.
• Across a wide range of datasets, even if the downstream data of
interest appears to only be weakly related to the data used for pre-
training, transfer learning remains the best available option.
• Among similarly performing pre-trained models, for transfer learning
a model with more training data should likely be preferred over one
with more data augmentation.
![Introduction
• ViT has recently emerged as a competitive alternative to
convolutional neural networks.
• Without the translational equivariance of CNNs, ViT models are
generally found to perform best in settings with large amounts of
training data[ViT] or to require strong AugReg(Augmentation and
Reegularization) schemes[DeiT] to avoid overfitting.
• There was no comprehensive study of the trade-offs between model
regularization, data augmentation, training data size and compute
budget in Vision Transformers.](data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7)