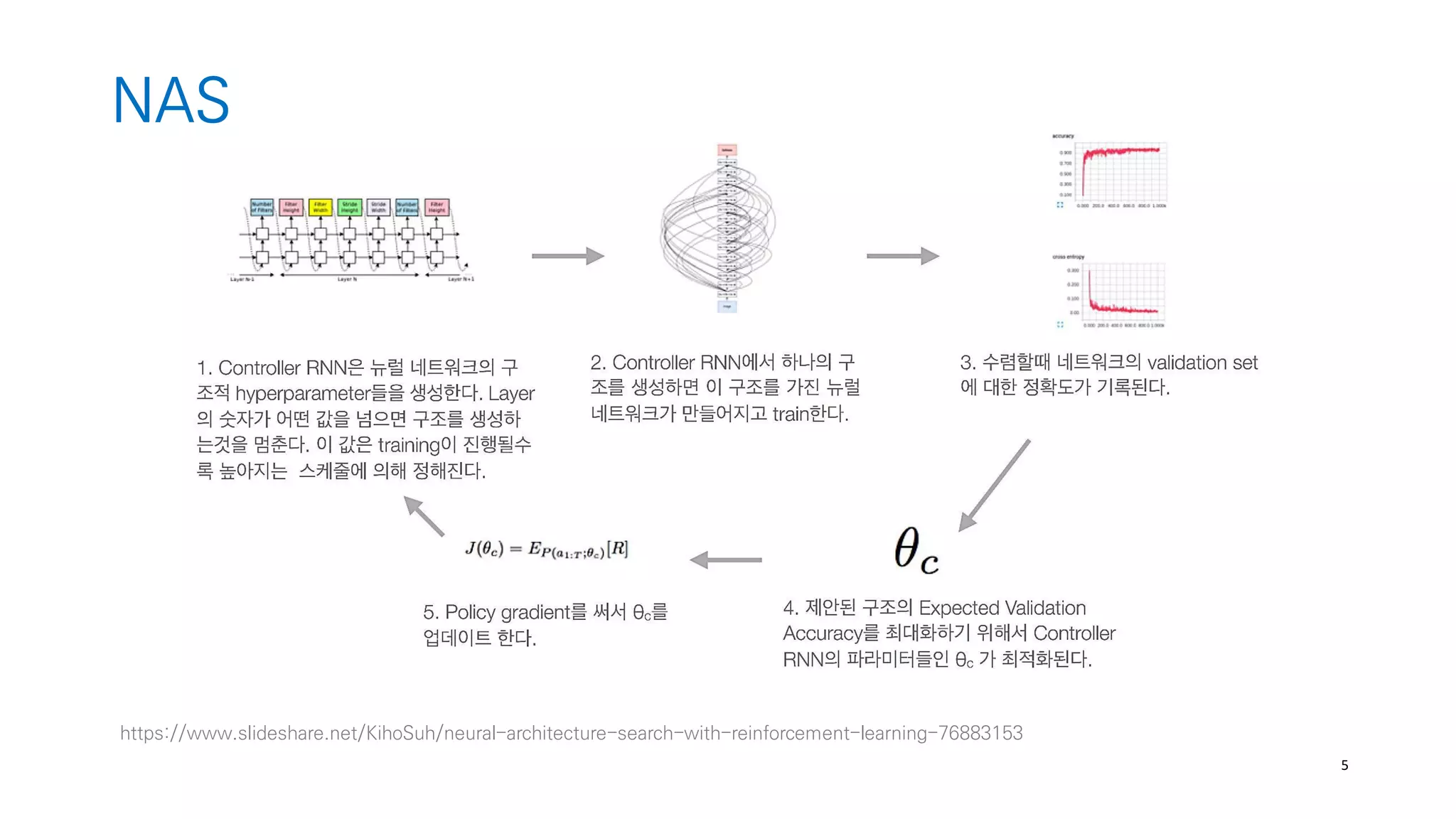
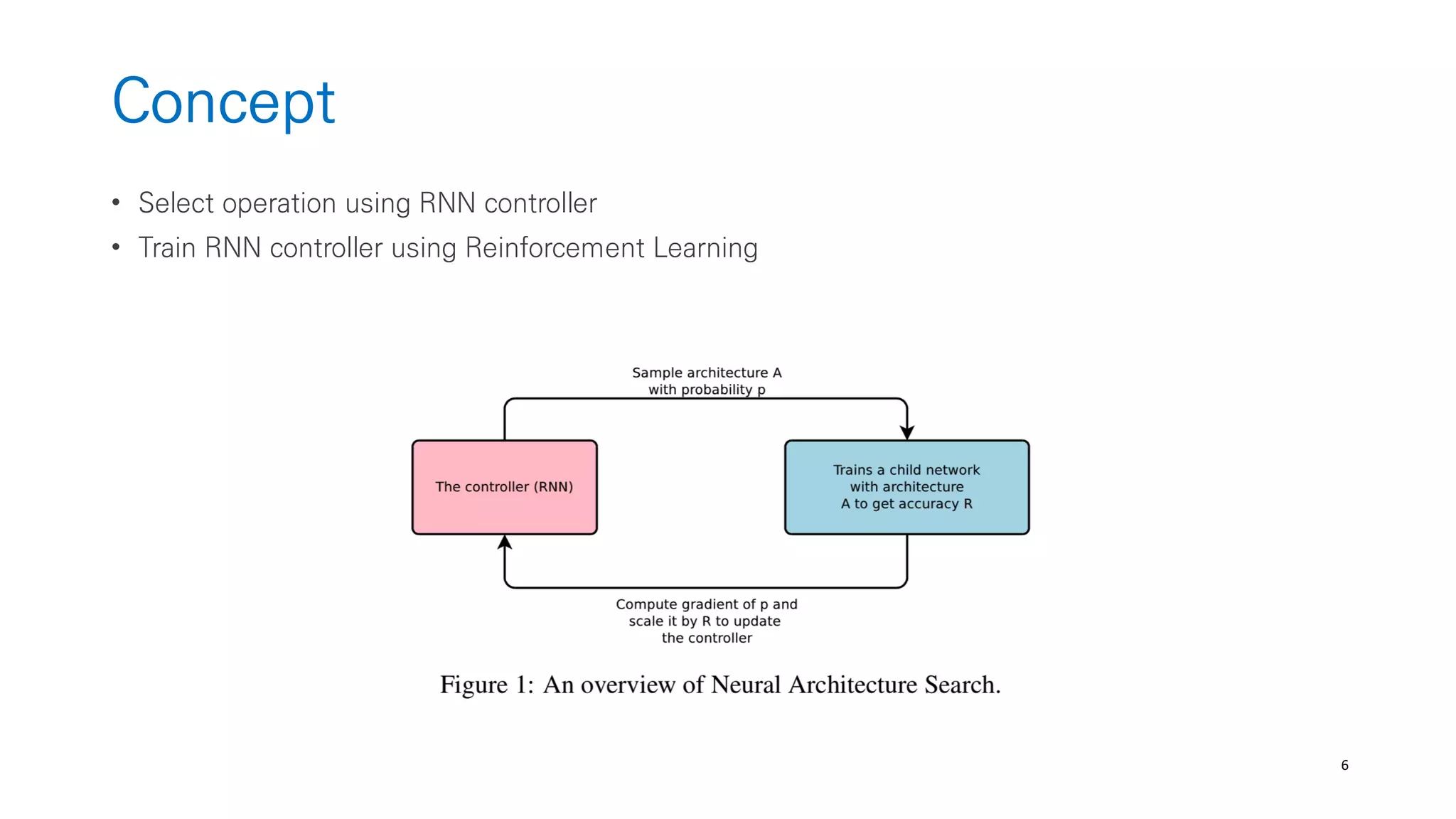
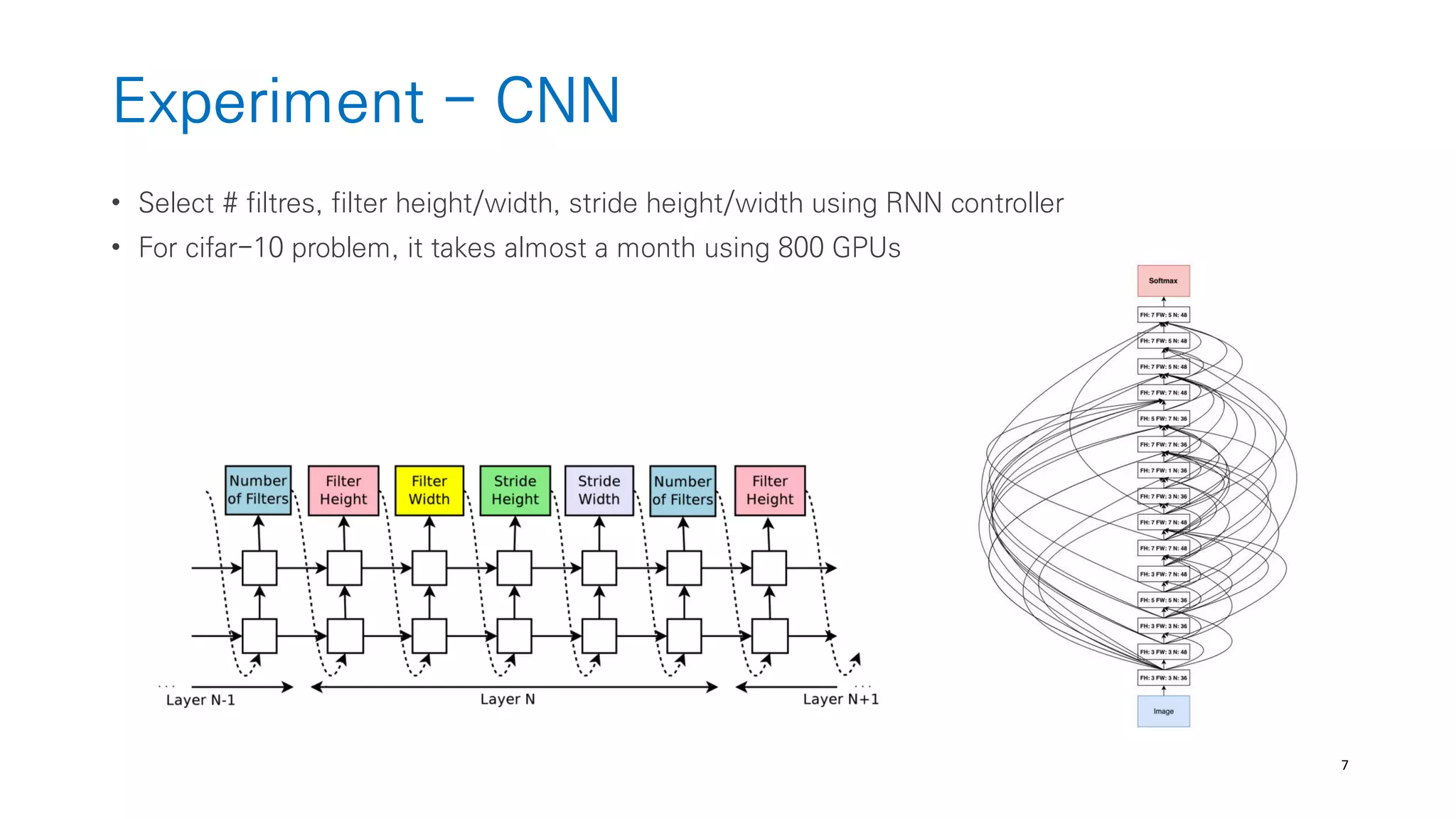
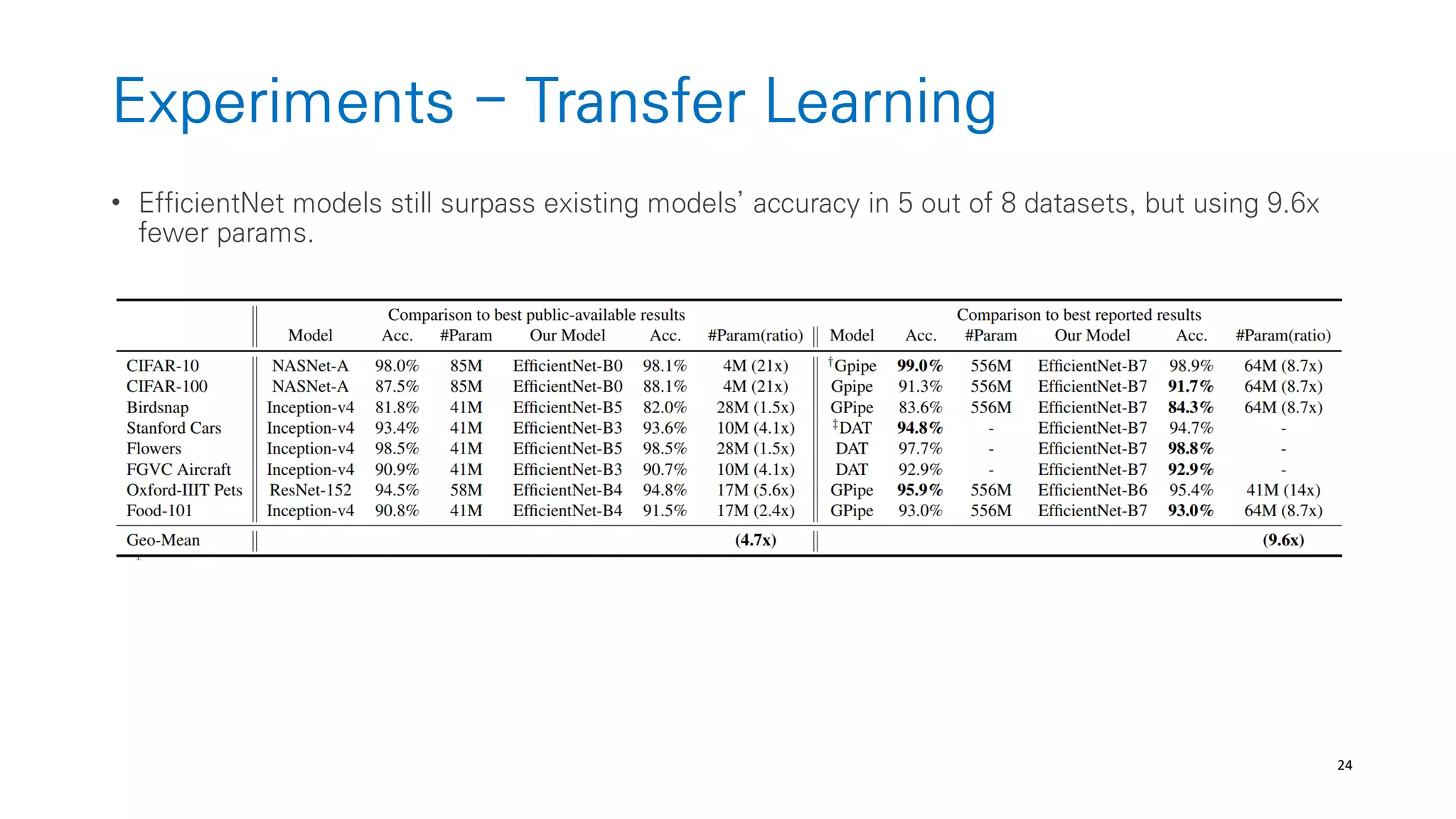
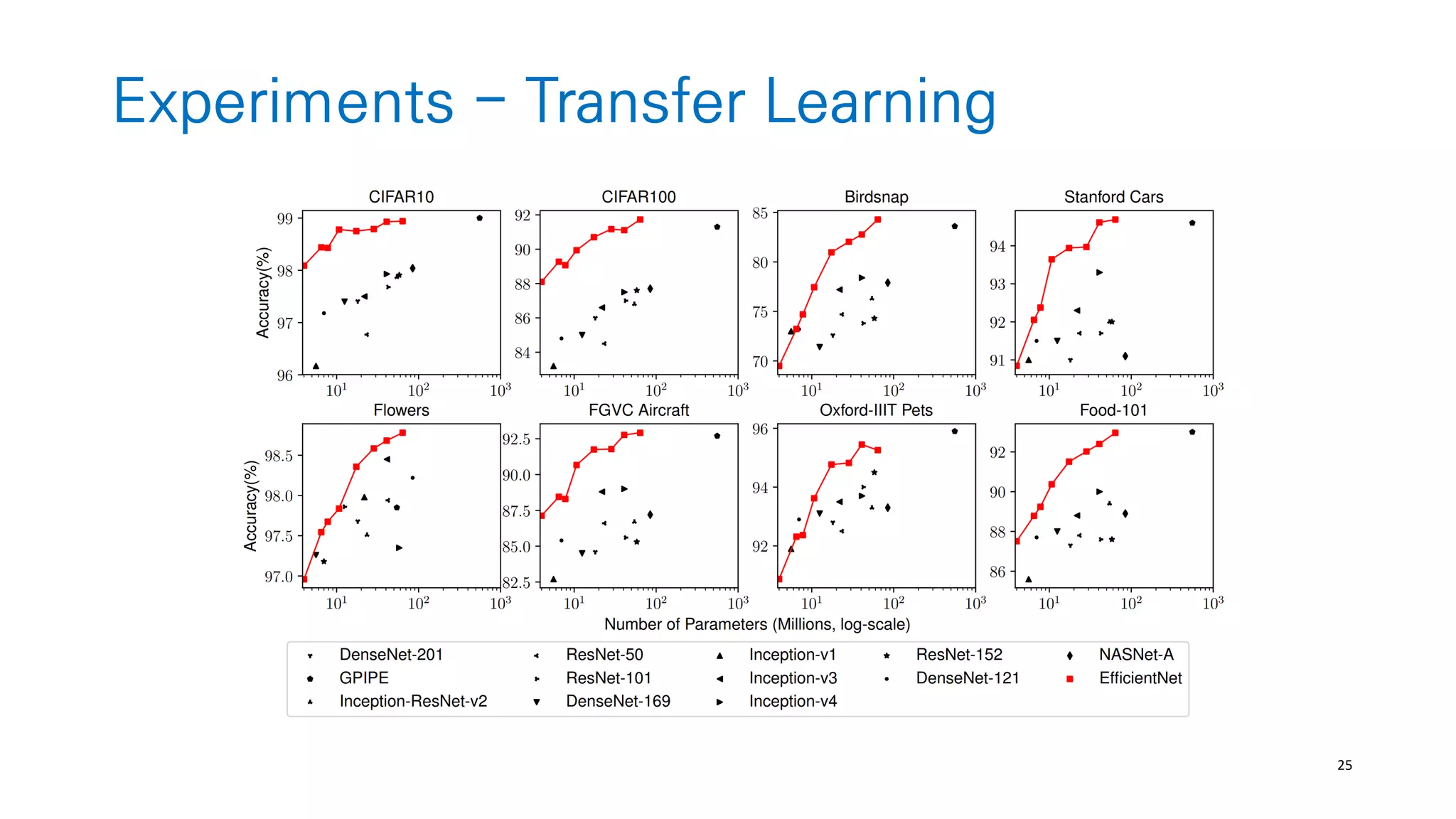
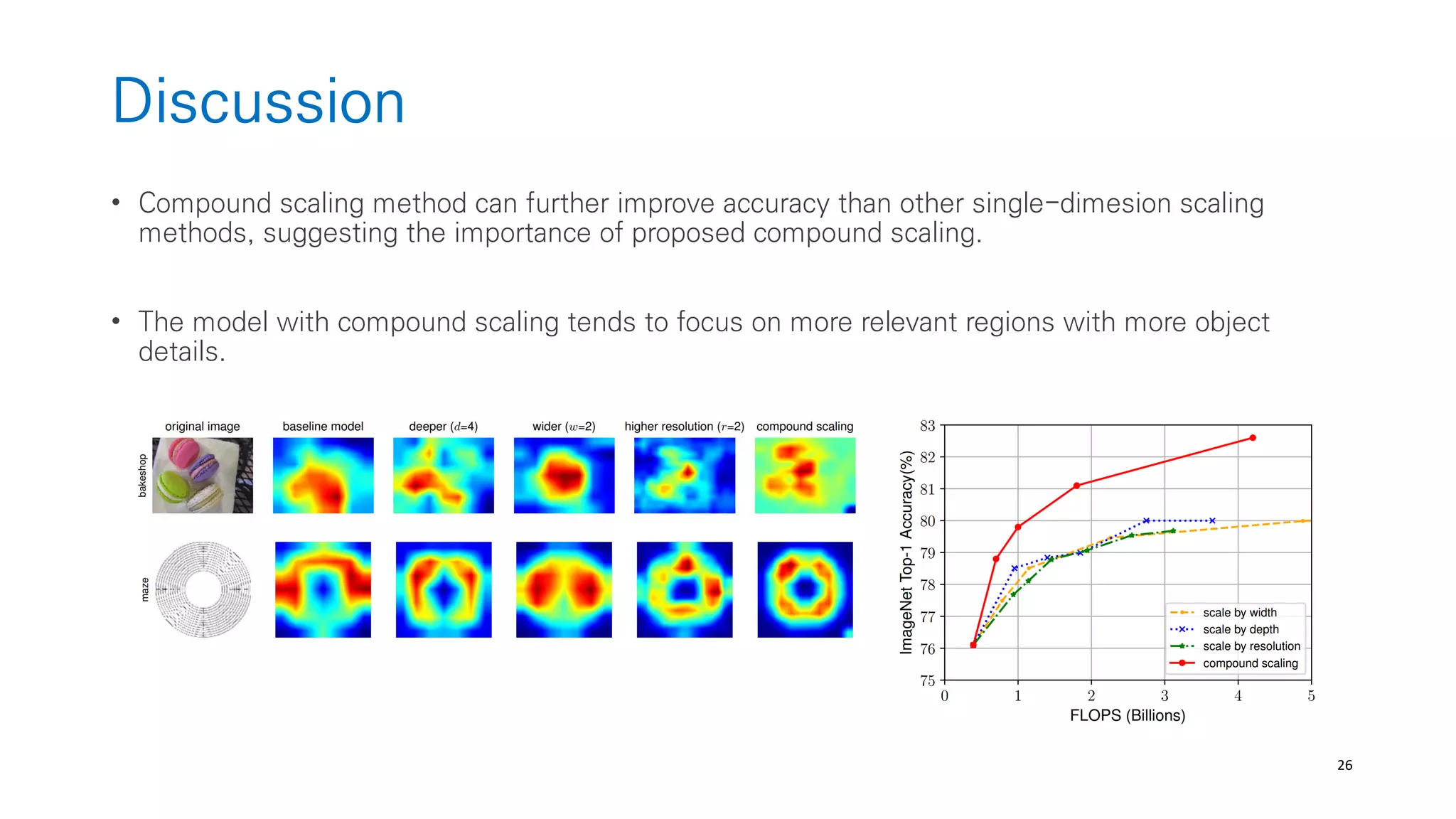
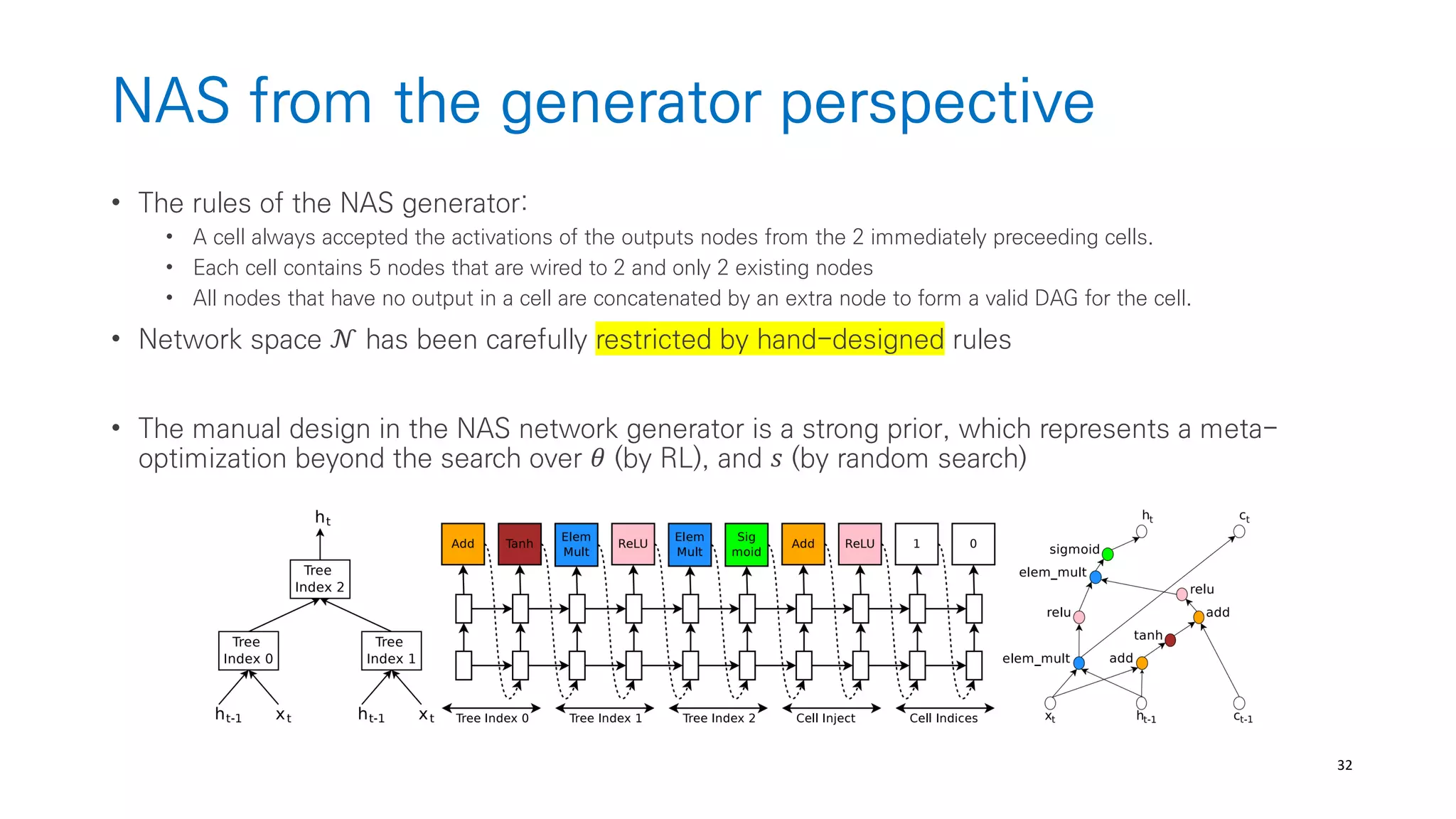
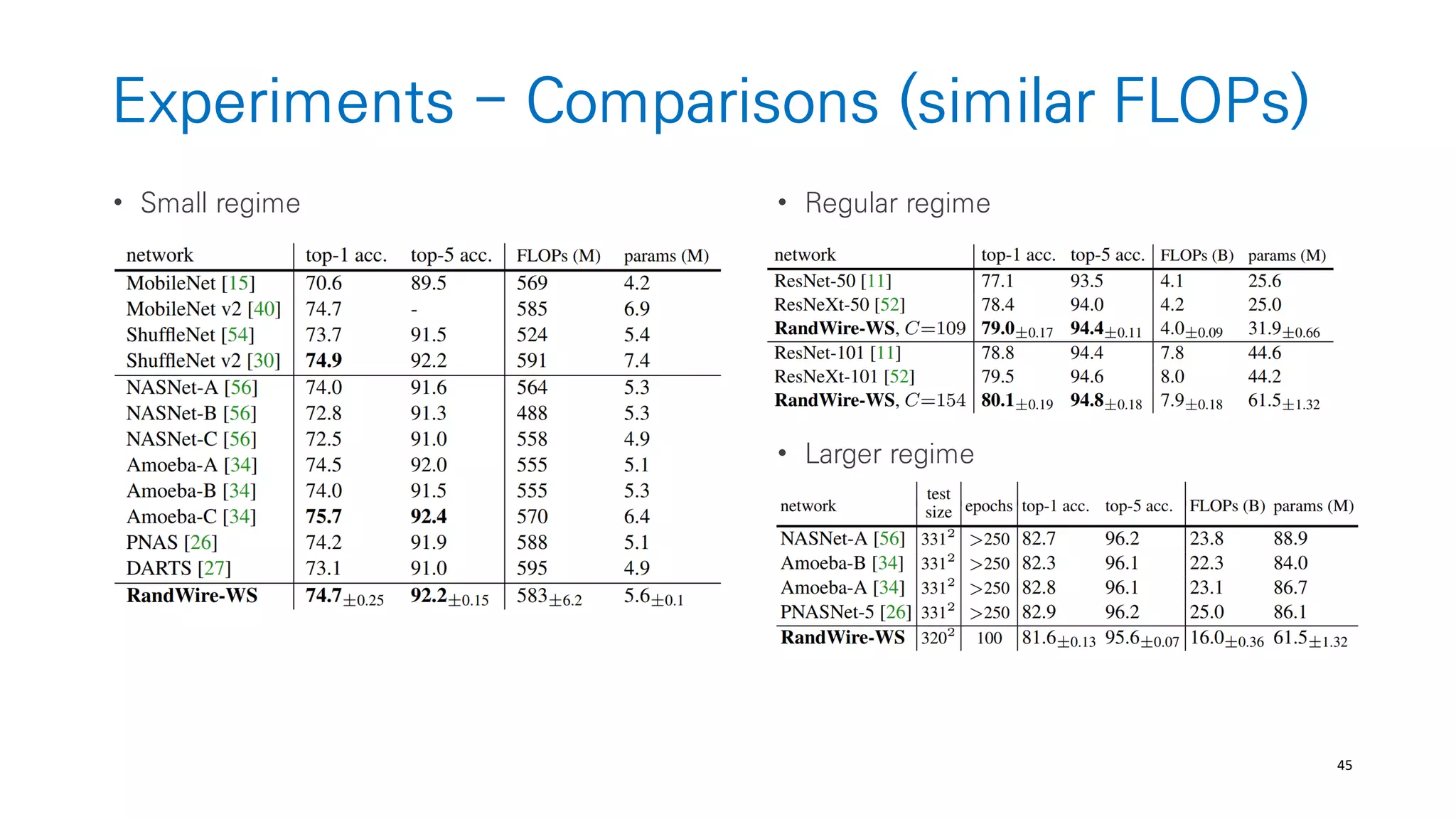
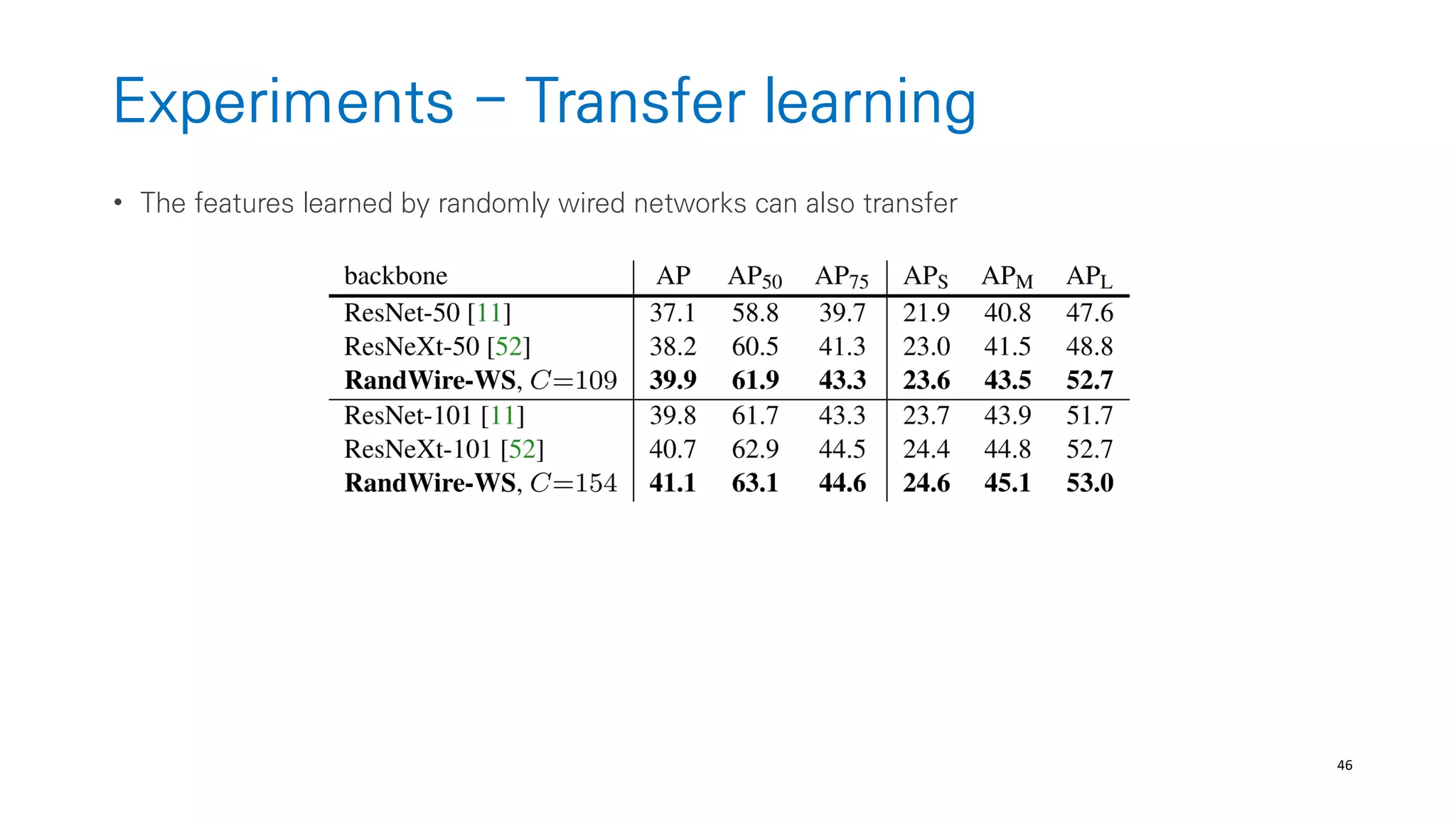
The document discusses AutoML and Neural Architecture Search (NAS), highlighting EfficientNet and randomly wired neural networks for image recognition. EfficientNet emphasizes compound scaling for improved accuracy with fewer parameters, while the research on randomly wired networks explores the potential for novel network designs that could enhance performance. Overall, the text underscores the significance of network generation methods in the evolution of neural architecture search.
















![33
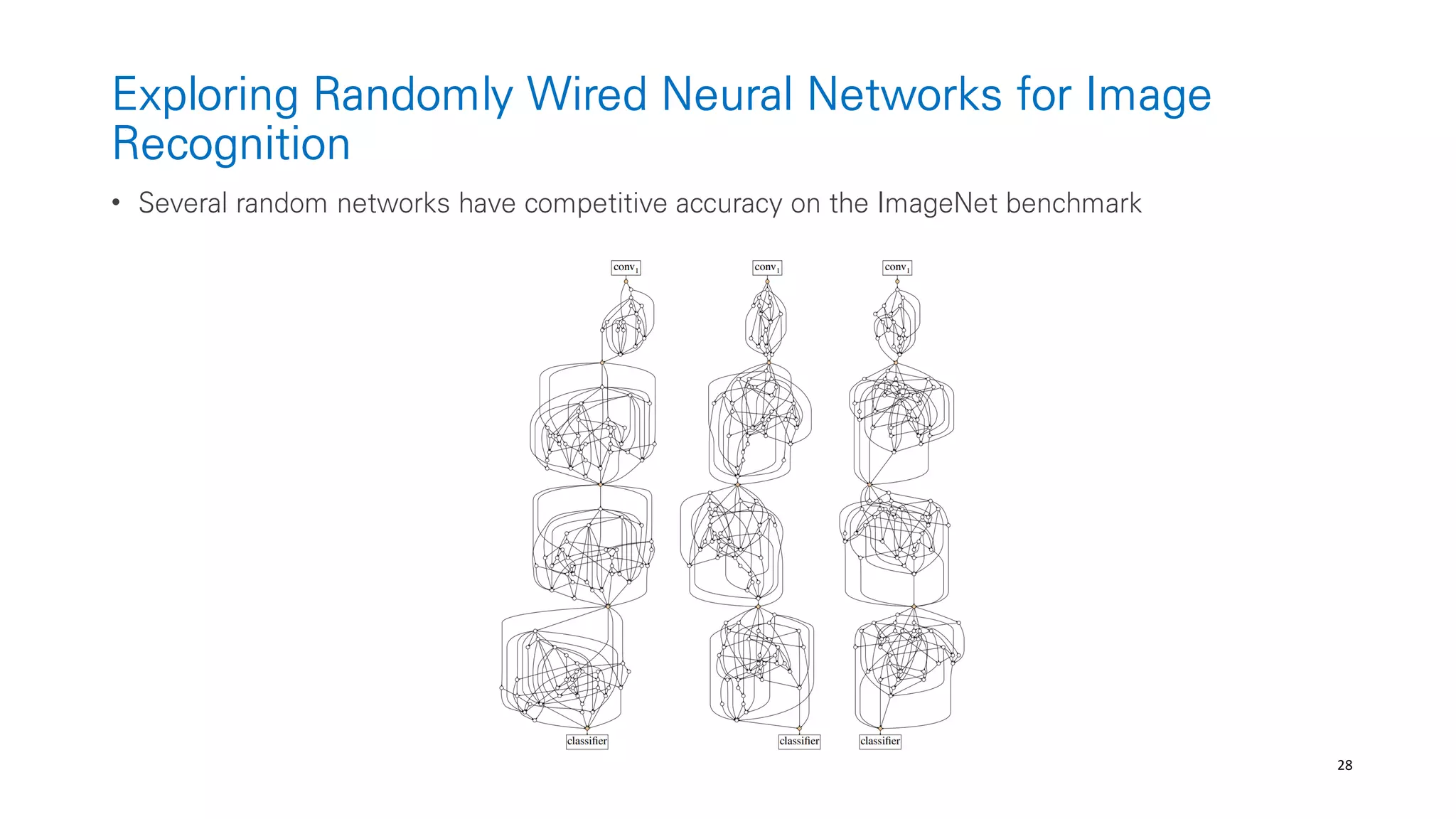
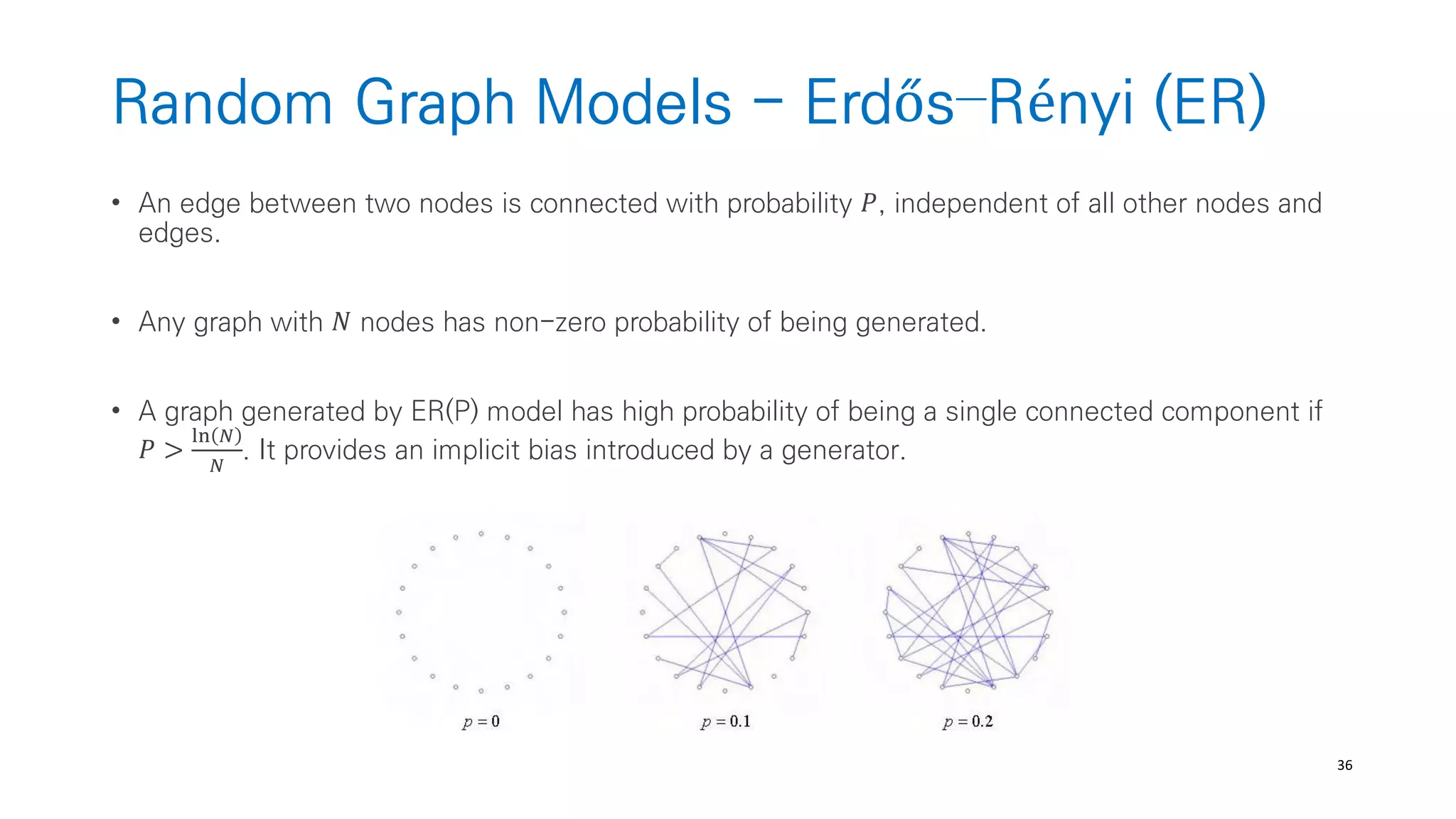
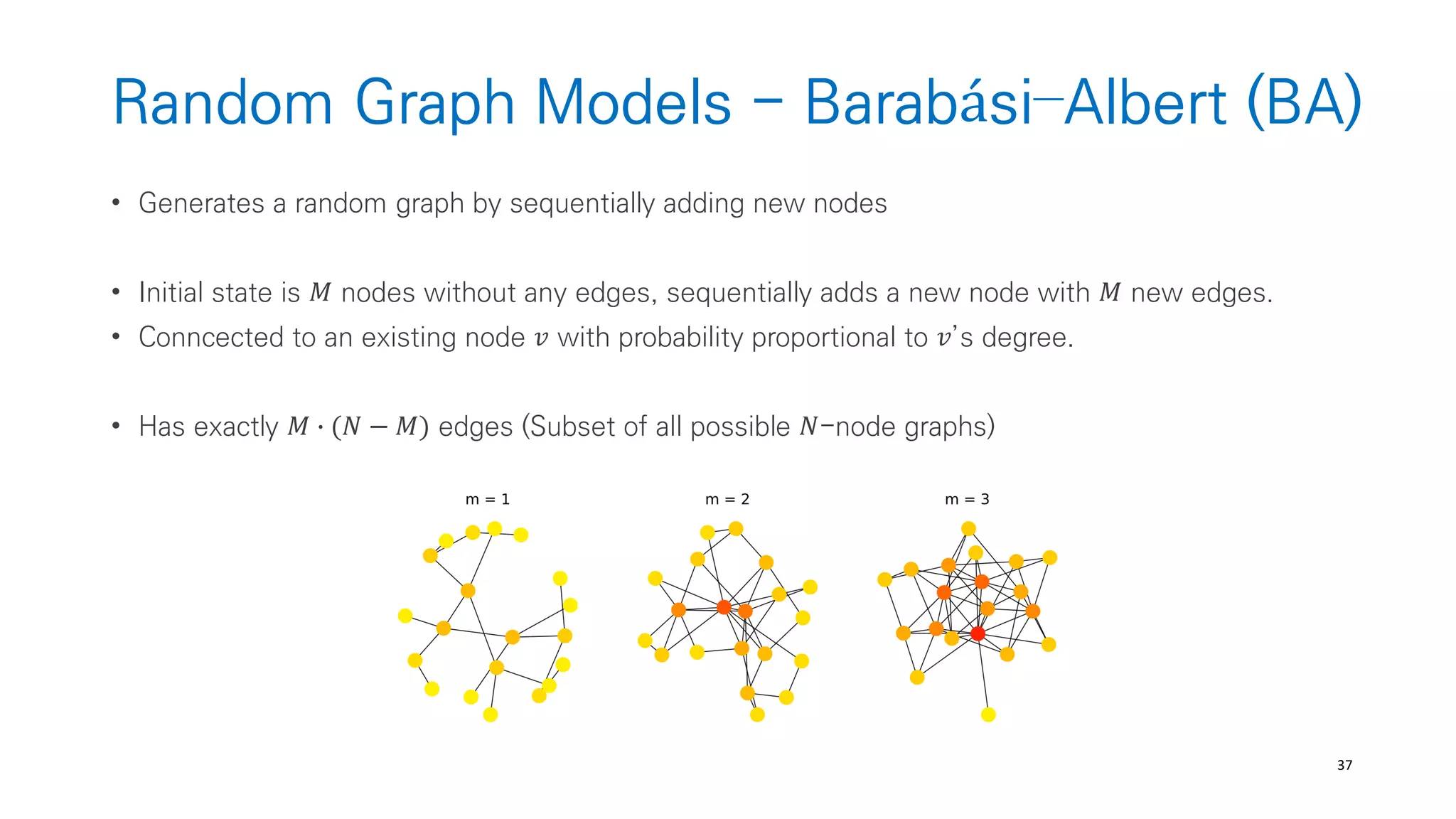
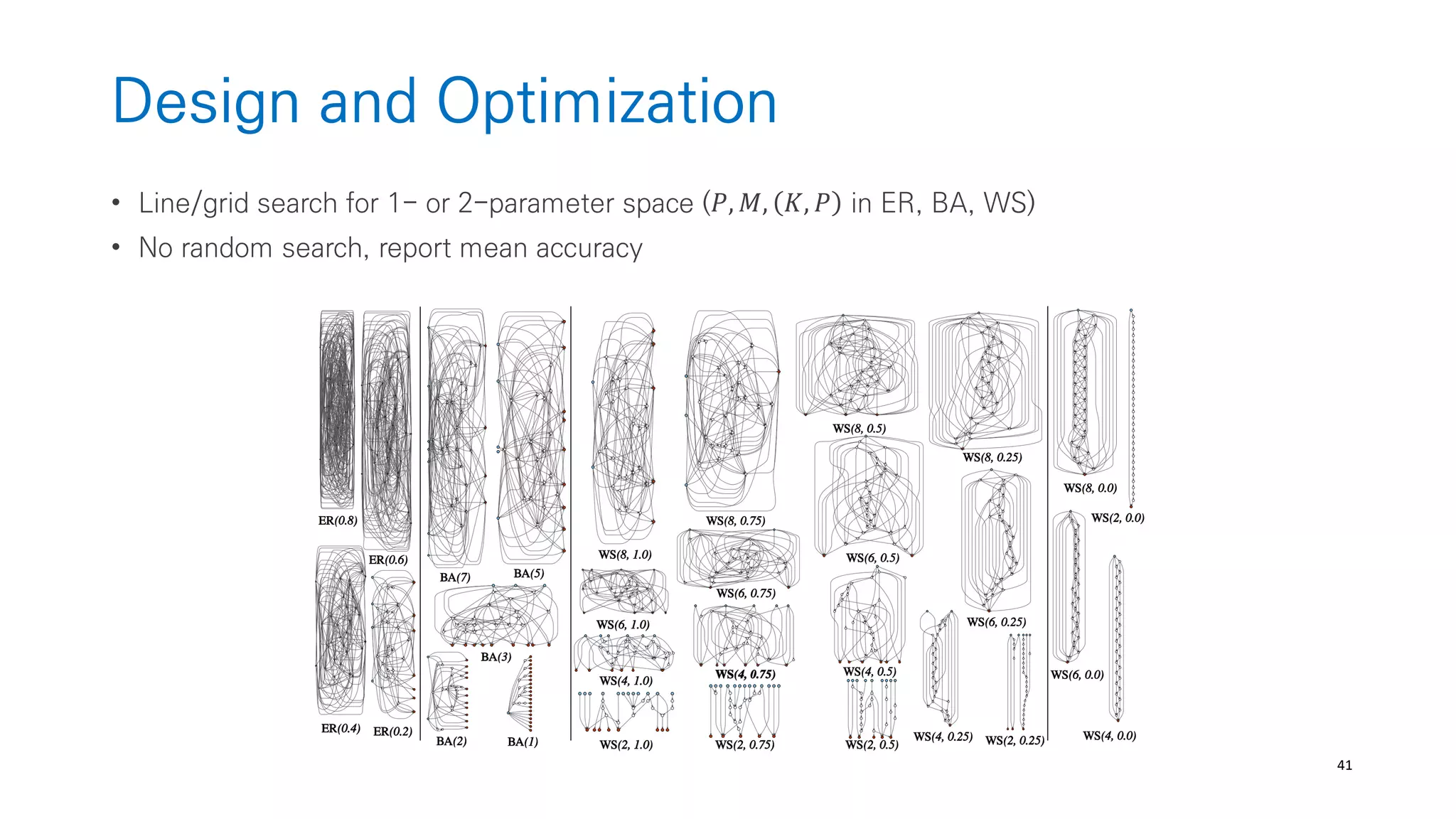
Randomly Wired Neural Networks
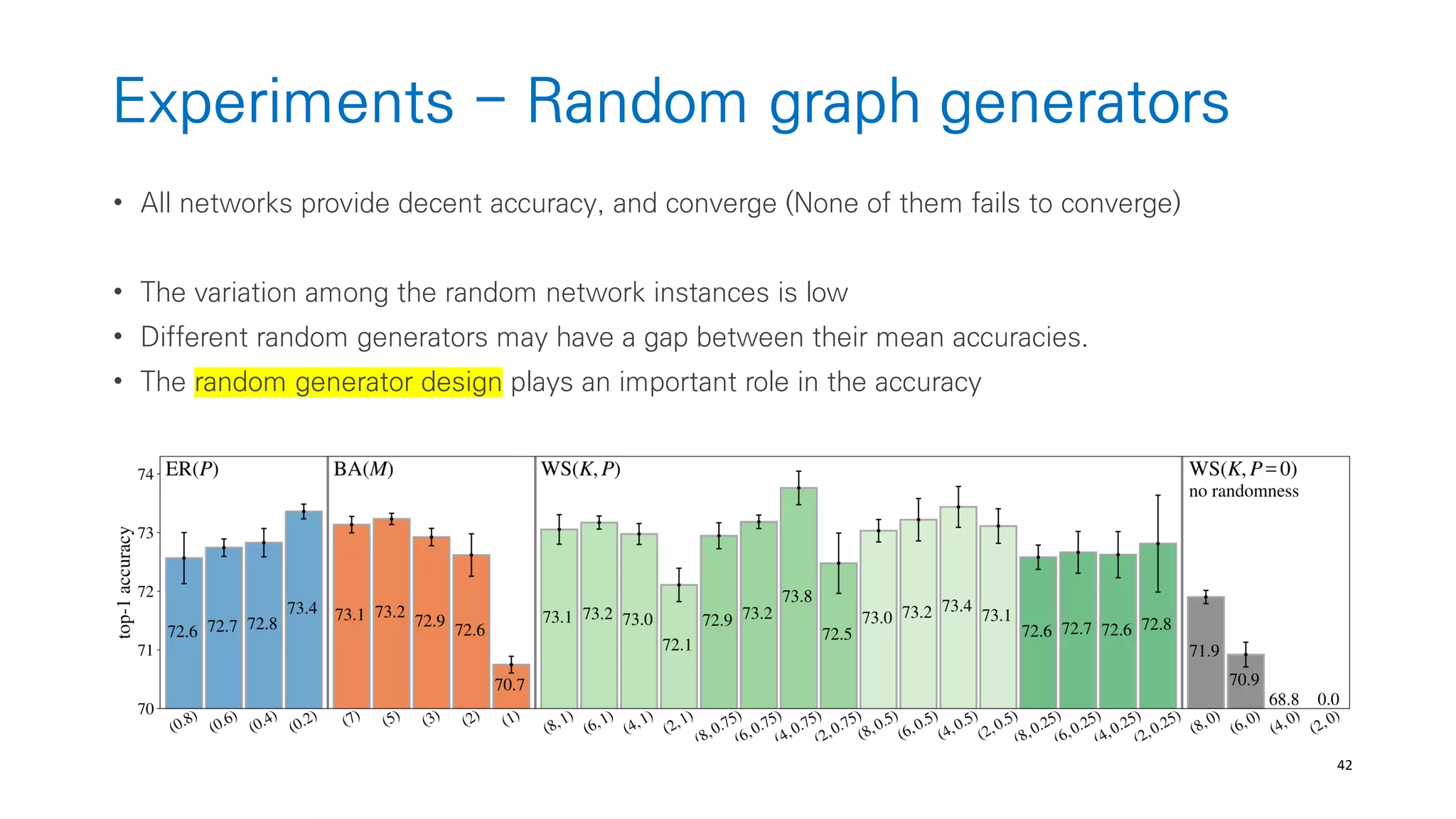
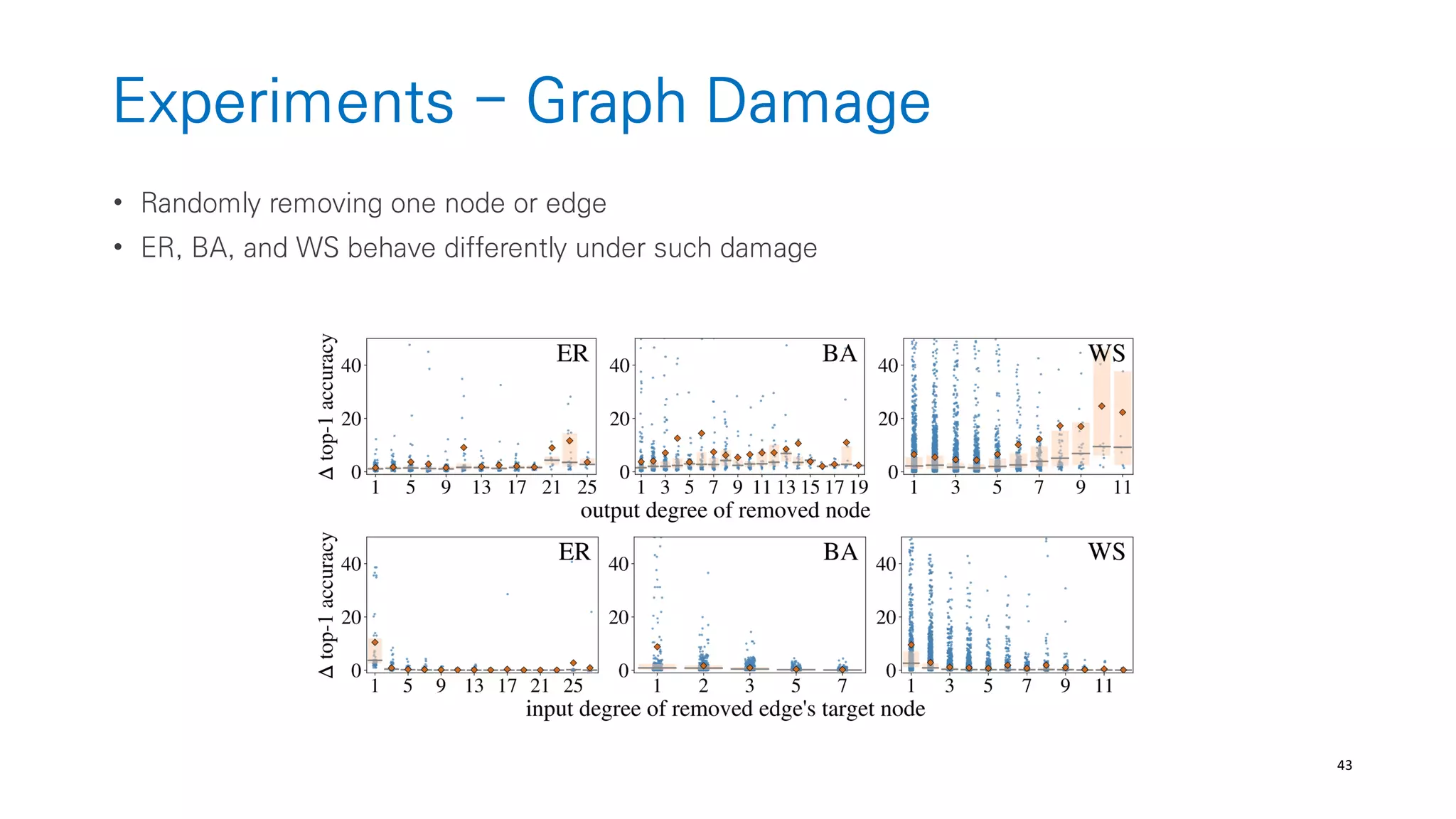
• Generate a general graphs w.o restricting how the graphs correspond to neural-networks
(from graph theory like ER, BA, WS)
• The edges are data flow (send data from one node to another node)
• Node operation
Aggregation: The input data are combied via a weighted sum; The weights are positive
Transformation: The aggregated data is processed by [ReLU-convolution-BN]
All nodes have same type of convolution!
Distribtuion: The same copy of the transformed data is sent out to other nodes.](https://image.slidesharecdn.com/201907automlandneuralarchitecturesearch-190705085959/75/201907-AutoML-and-Neural-Architecture-Search-33-2048.jpg)









![[DL輪読会]Model-Based Reinforcement Learning via Meta-Policy Optimization](https://cdn.slidesharecdn.com/ss_thumbnails/model-basedreinforcementlearningviameta-policyoptimization-190705000247-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会] off-policyなメタ強化学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190405journalclub-190415082841-thumbnail.jpg?width=640&height=640&fit=bounds)







![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]AutoAugment: LearningAugmentation Strategies from Data & Learning Data...](https://cdn.slidesharecdn.com/ss_thumbnails/dlp0712f-190719034120-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Shaping Belief States with Generative Environment Models for RL](https://cdn.slidesharecdn.com/ss_thumbnails/20190705suzuki-191204061058-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Deep Learning 第5章 機械学習の基礎](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning5-180601021956-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Deep Learning 第2章 線形代数](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearningchapter2-180601014406-thumbnail.jpg?width=640&height=640&fit=bounds)