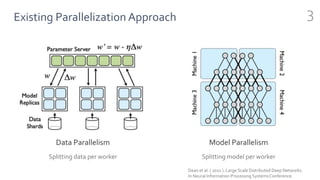
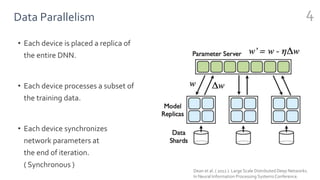
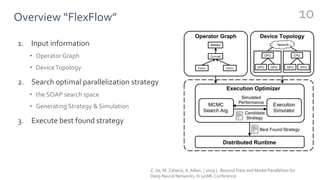
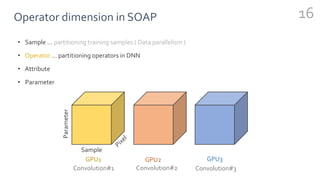
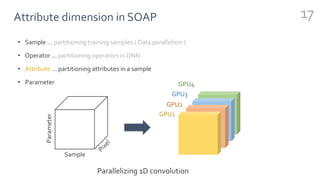
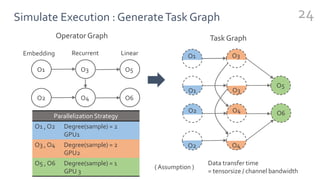
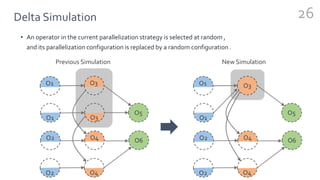
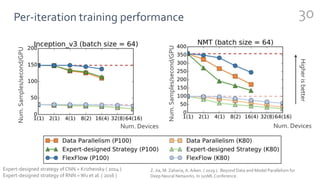
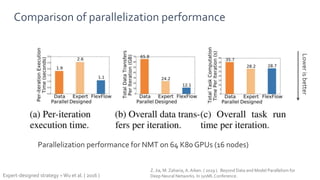
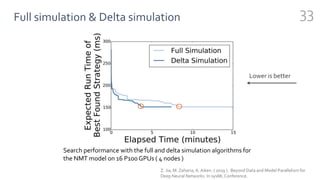
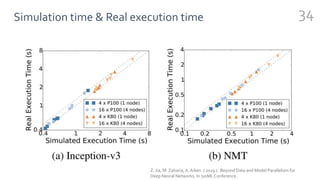
FlexFlow is a deep learning engine that automatically finds optimal parallelization strategies for arbitrary DNN models and hardware configurations. It defines a comprehensive search space called SOAP that includes sample, operator, attribute, and parameter parallelization. FlexFlow uses a Markov Chain Monte Carlo algorithm to search this space. It simulates strategy executions, either through full simulation or more efficient delta simulation, to identify high performing strategies. Evaluation on real-world DNN models and hardware showed FlexFlow outperforms expert-designed strategies and other automated frameworks by achieving up to 3.3x higher training throughput.