Downloaded 18 times


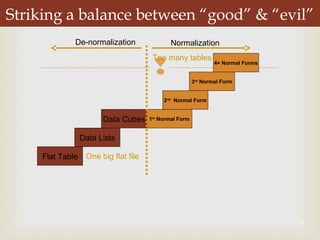






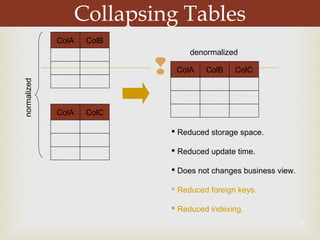
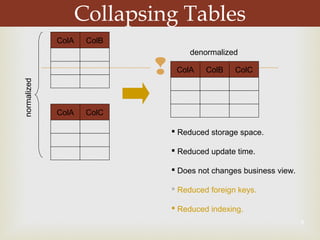

De-normalization involves combining or modifying tables in a database to improve query performance for data warehousing and decision support systems (DSS). It aims to enhance performance without losing information by bringing related data items closer together through techniques like collapsing tables, splitting tables, pre-joining tables, and adding redundant or derived columns. The level of de-normalization should be carefully considered based on a cost-benefit analysis of storage needs, maintenance issues, and query requirements.


































![Normalisation [Slides].pdf introduction language](https://cdn.slidesharecdn.com/ss_thumbnails/normalisationslides-241027214218-f965ea10-thumbnail.jpg?width=640&height=640&fit=bounds)



















































