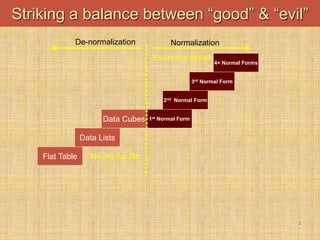
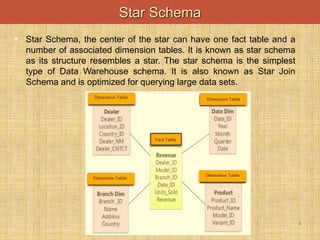
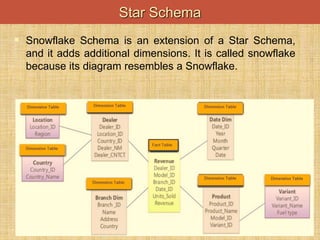
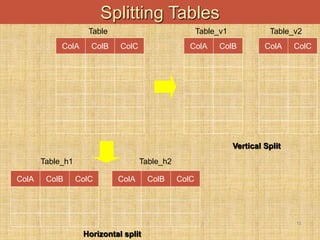
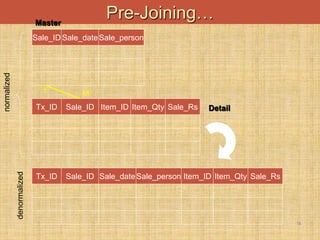
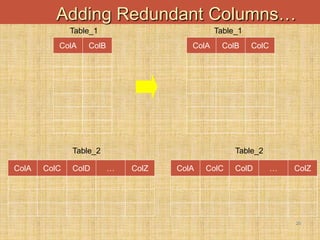
This document discusses denormalization techniques used in data warehousing to improve query performance. It explains that while normalization is important for databases, denormalization can enhance performance in data warehouses where queries are frequent and updates are less common. Some key denormalization techniques covered include collapsing tables, splitting tables horizontally or vertically, pre-joining tables, adding redundant columns, and including derived attributes. Guidelines for when and how to apply denormalization carefully are also provided.




























































![Normalisation [Slides].pdf introduction language](https://cdn.slidesharecdn.com/ss_thumbnails/normalisationslides-241027214218-f965ea10-thumbnail.jpg?width=640&height=640&fit=bounds)











































