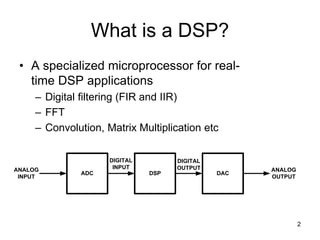
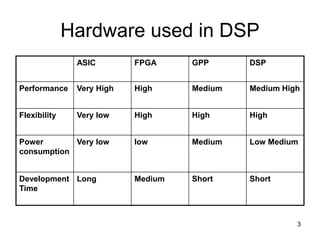
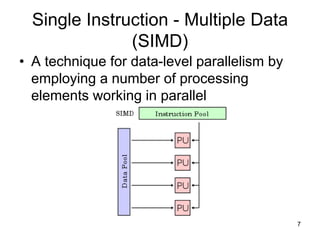
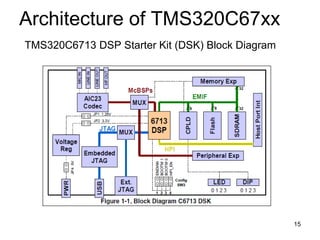
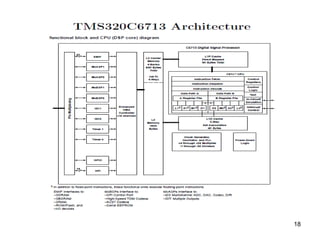
A digital signal processor (DSP) is a specialized microprocessor designed for real-time digital signal processing applications such as digital filtering, Fast Fourier Transforms, and matrix multiplication. DSPs have hardware features that accelerate these types of mathematical operations, including a Harvard architecture with separate program and data memory, dedicated multiply-accumulate units, and single-instruction multiple-data (SIMD) or very long instruction word (VLIW) architectures for parallel execution. Common DSP chips also have pipelined architectures, cache memory, and direct memory access (DMA) controllers.