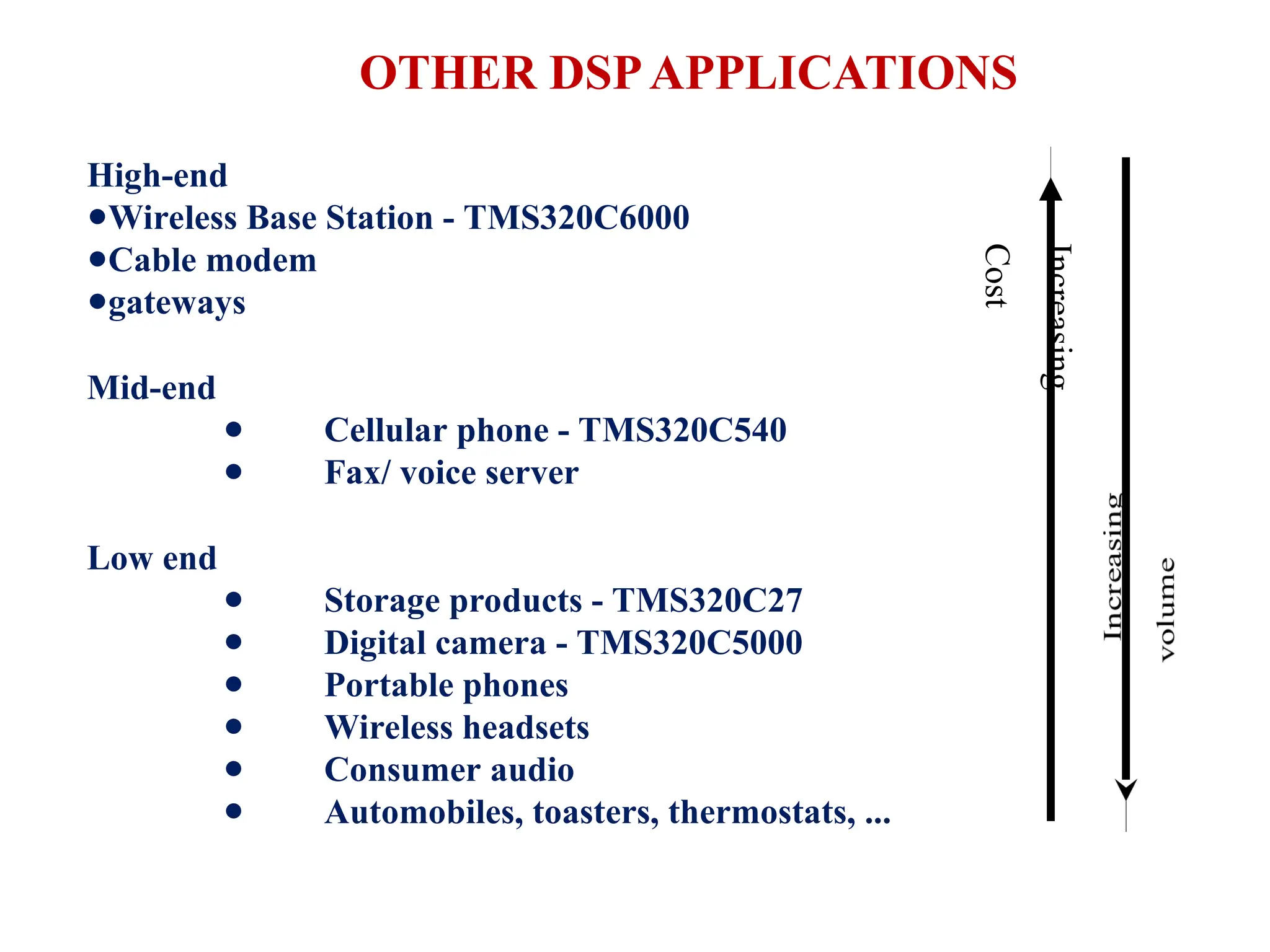
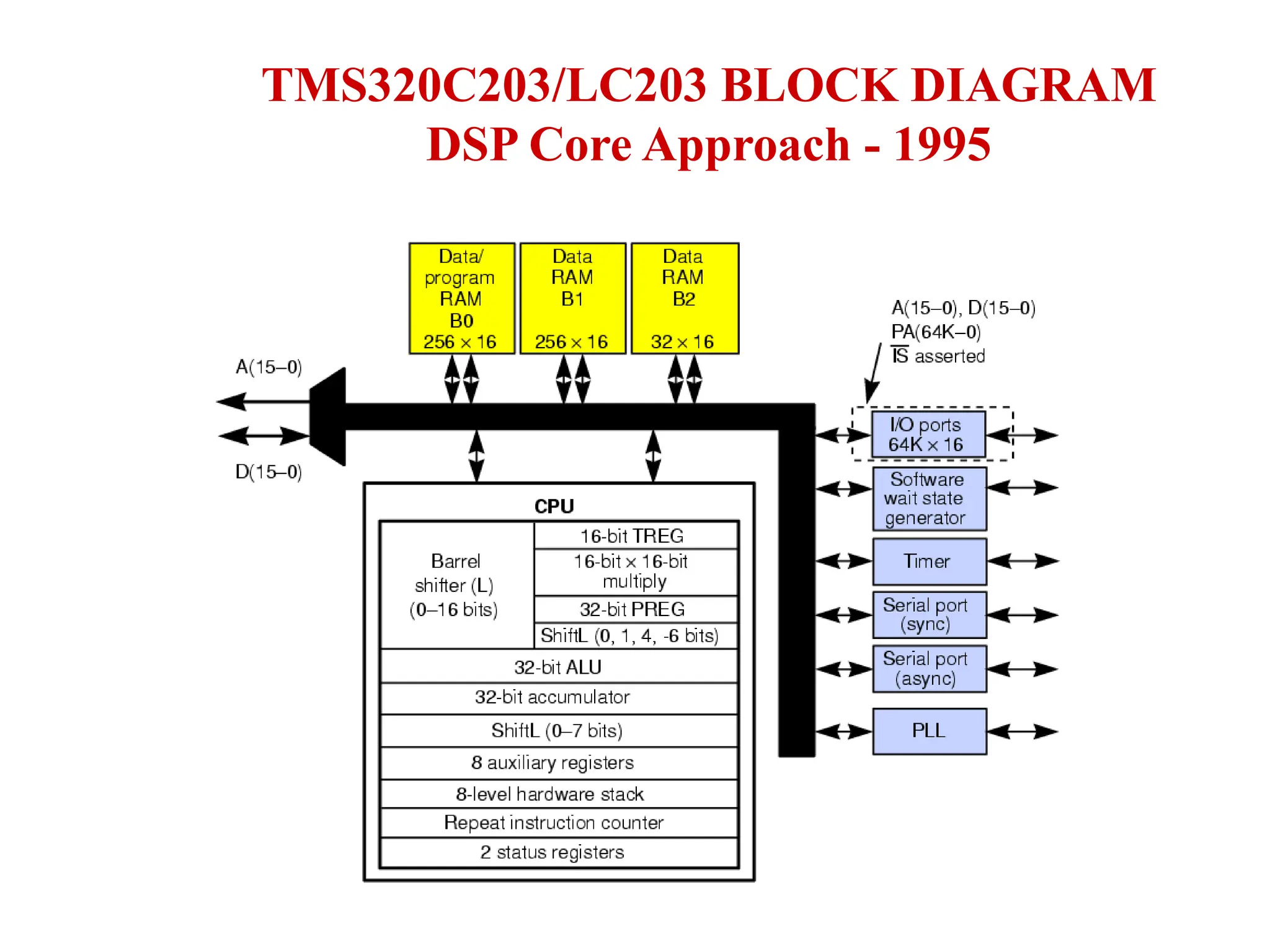
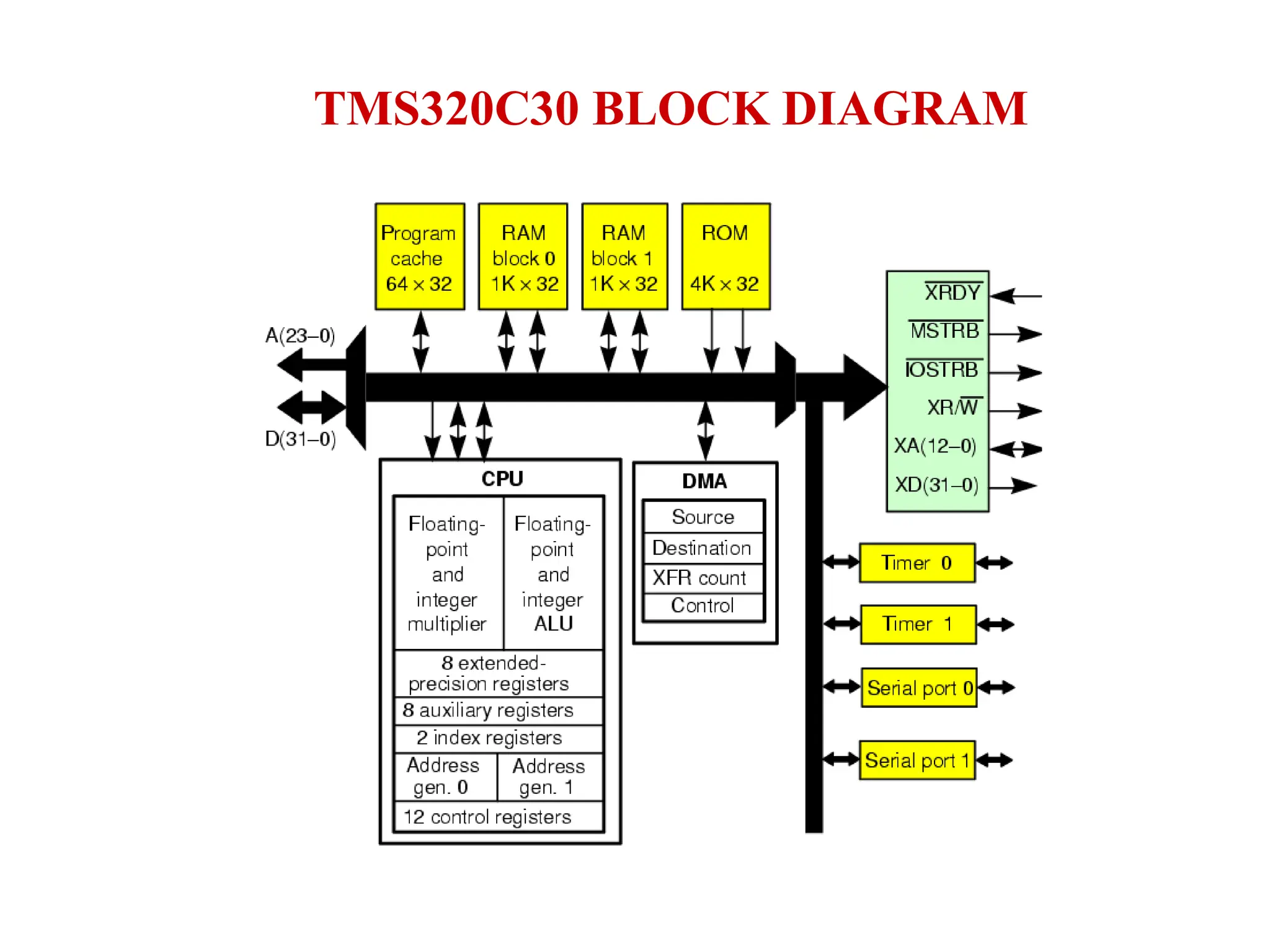
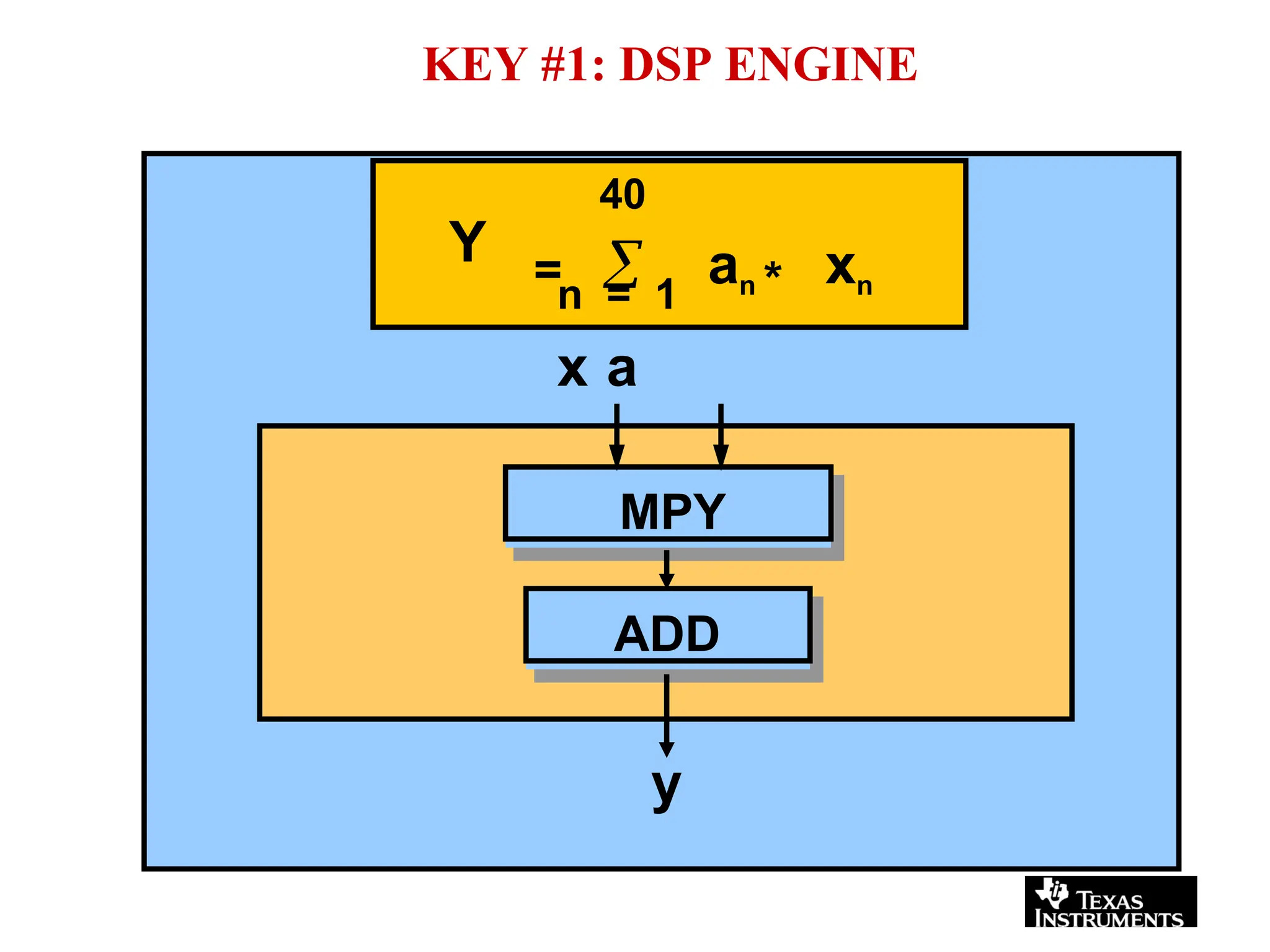
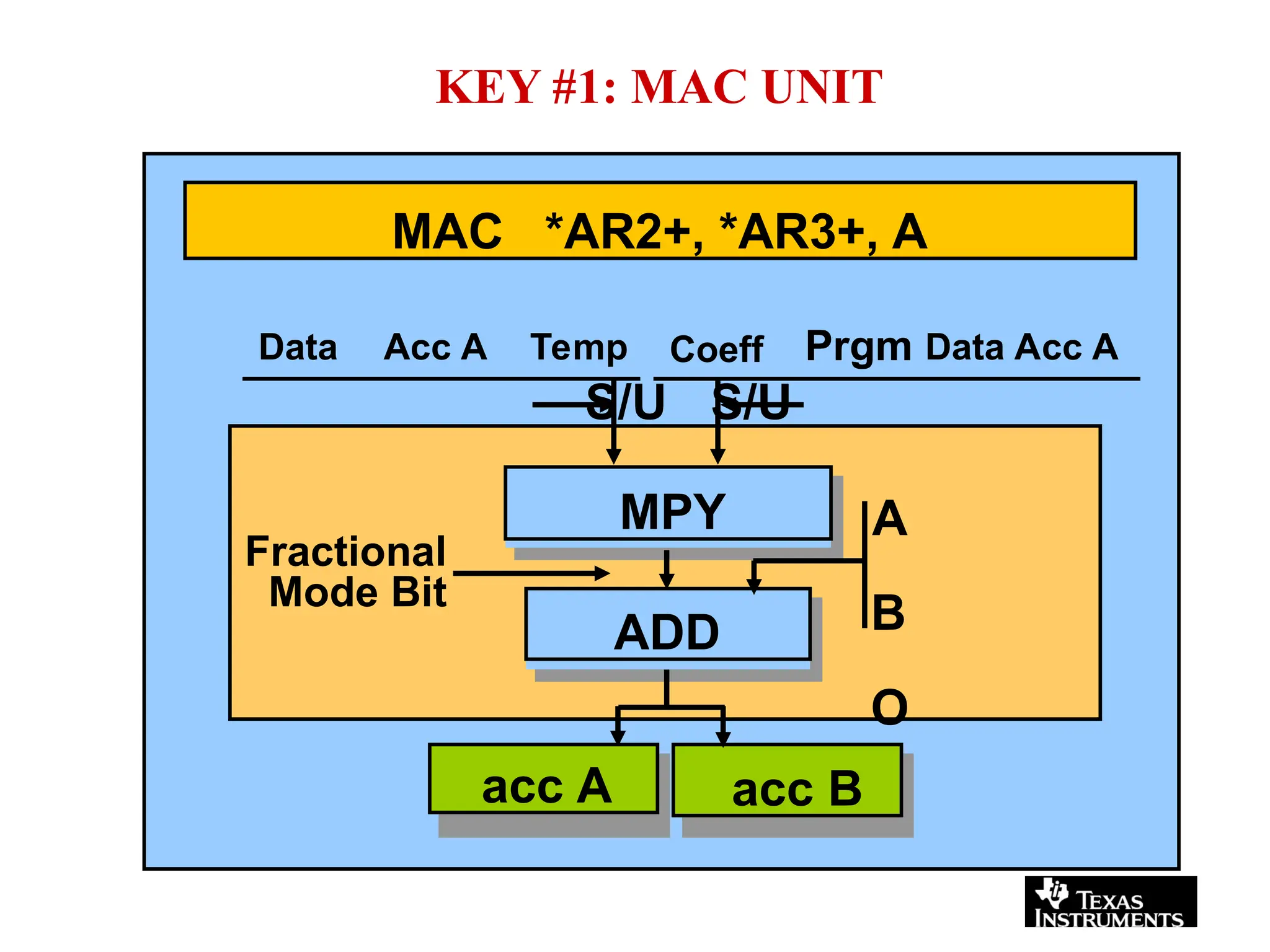
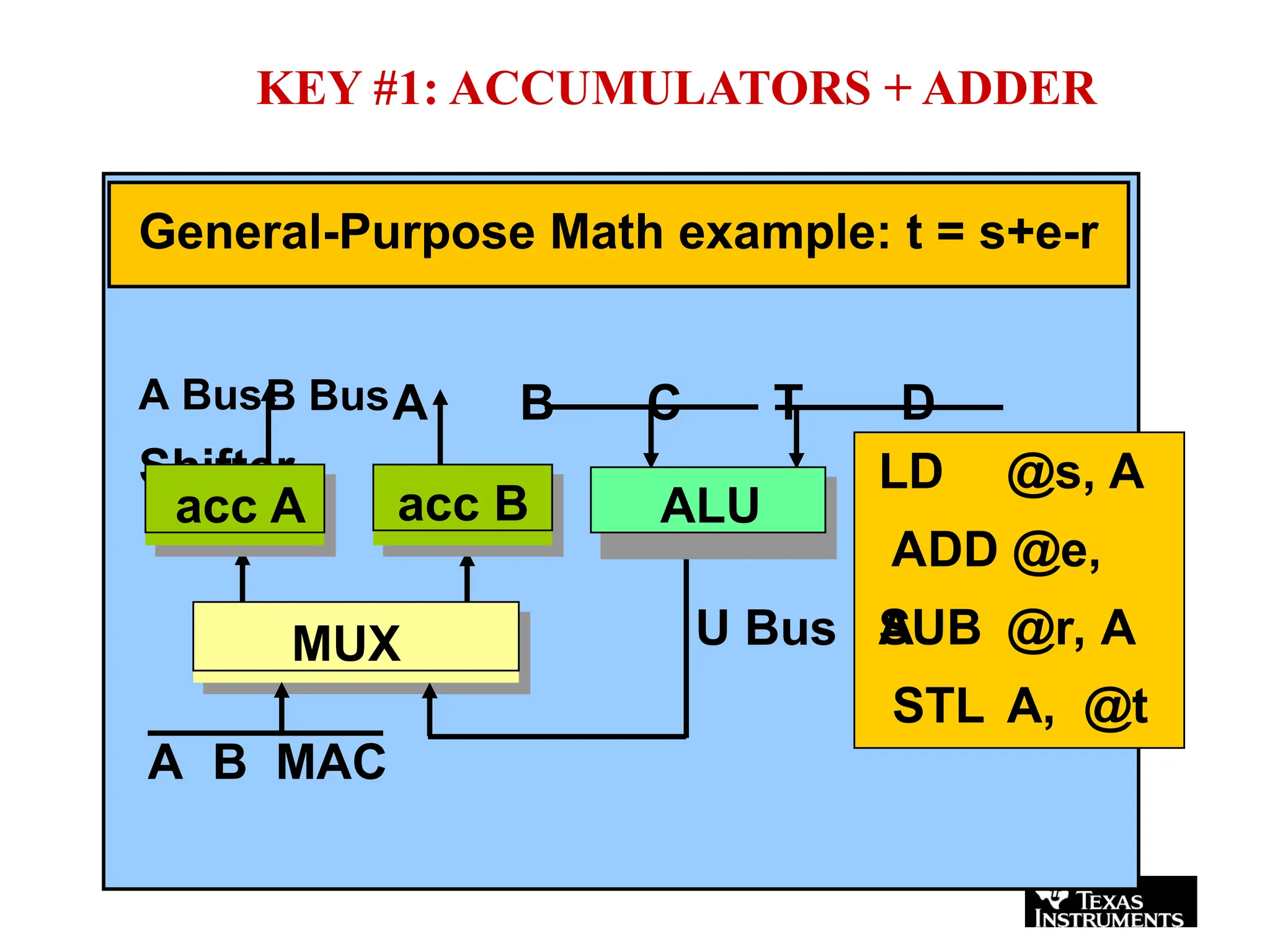
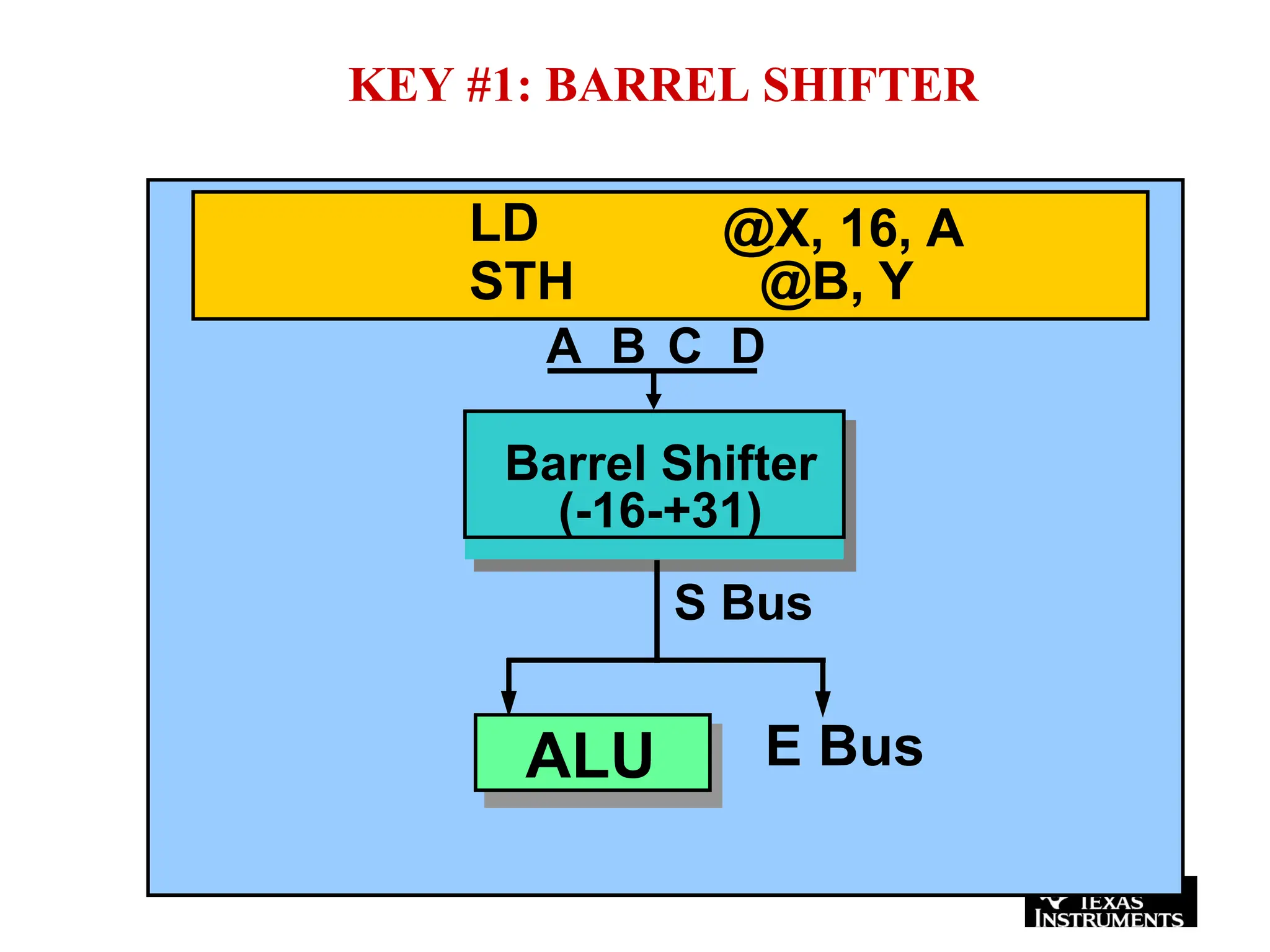
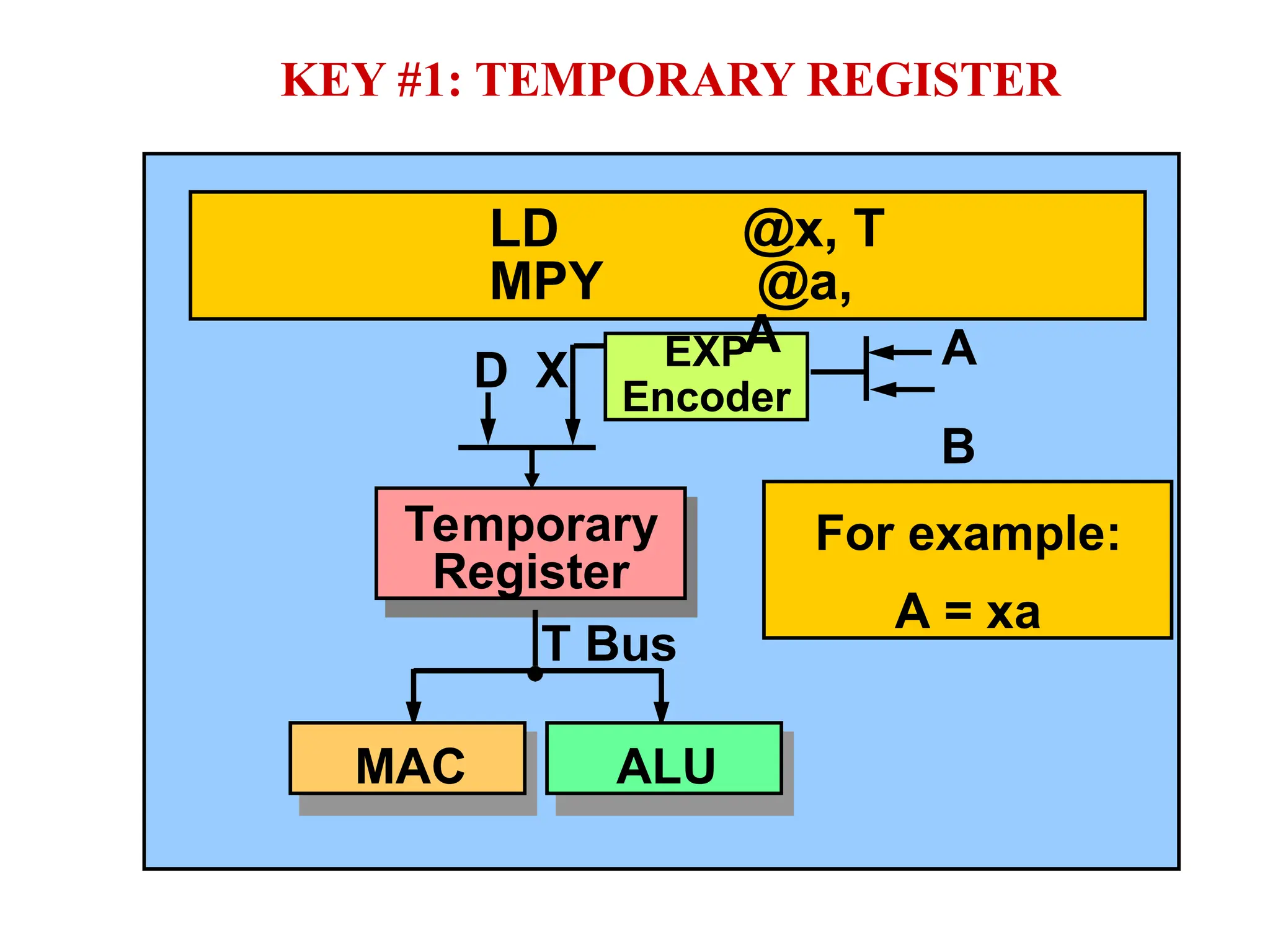
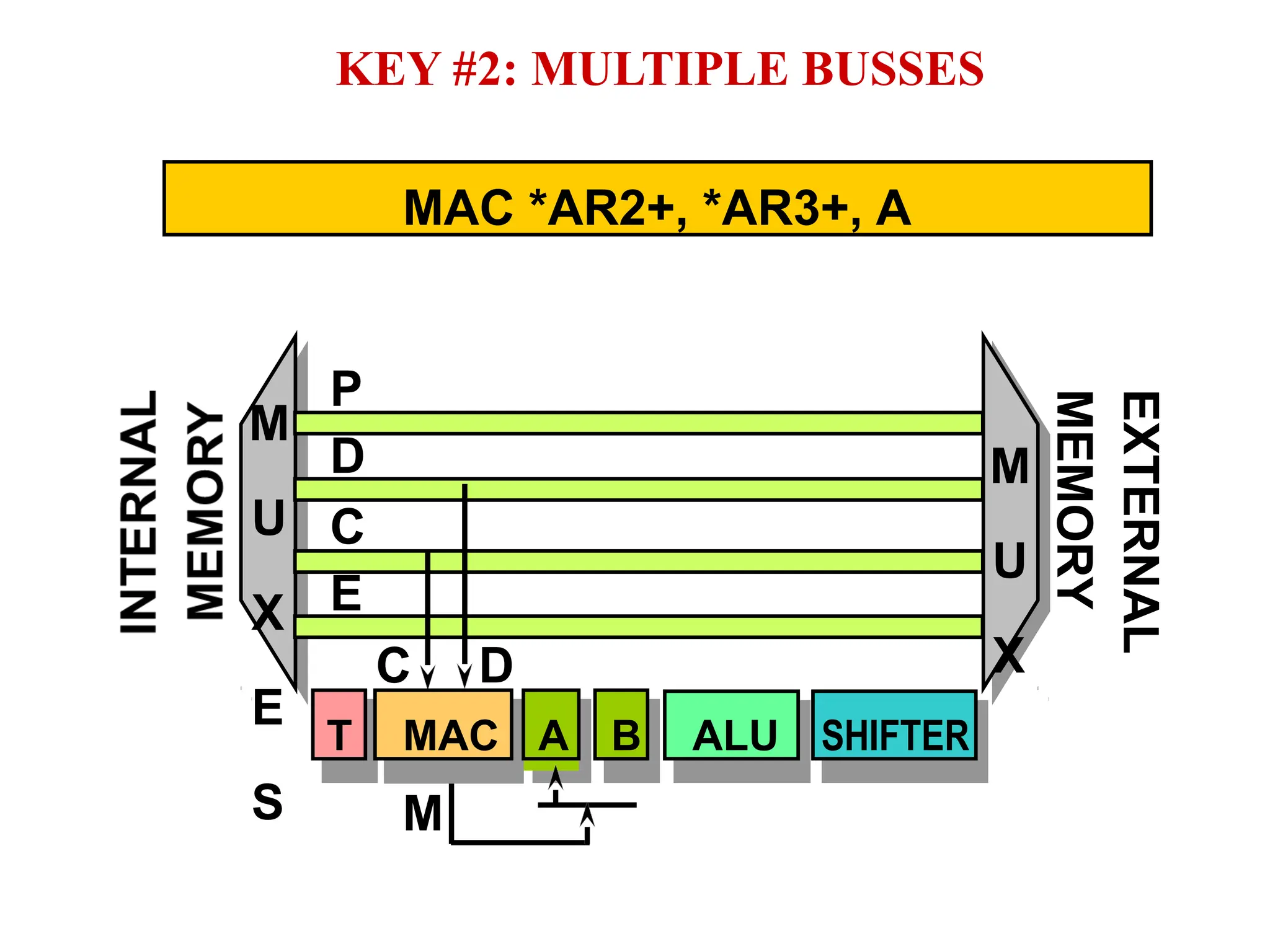
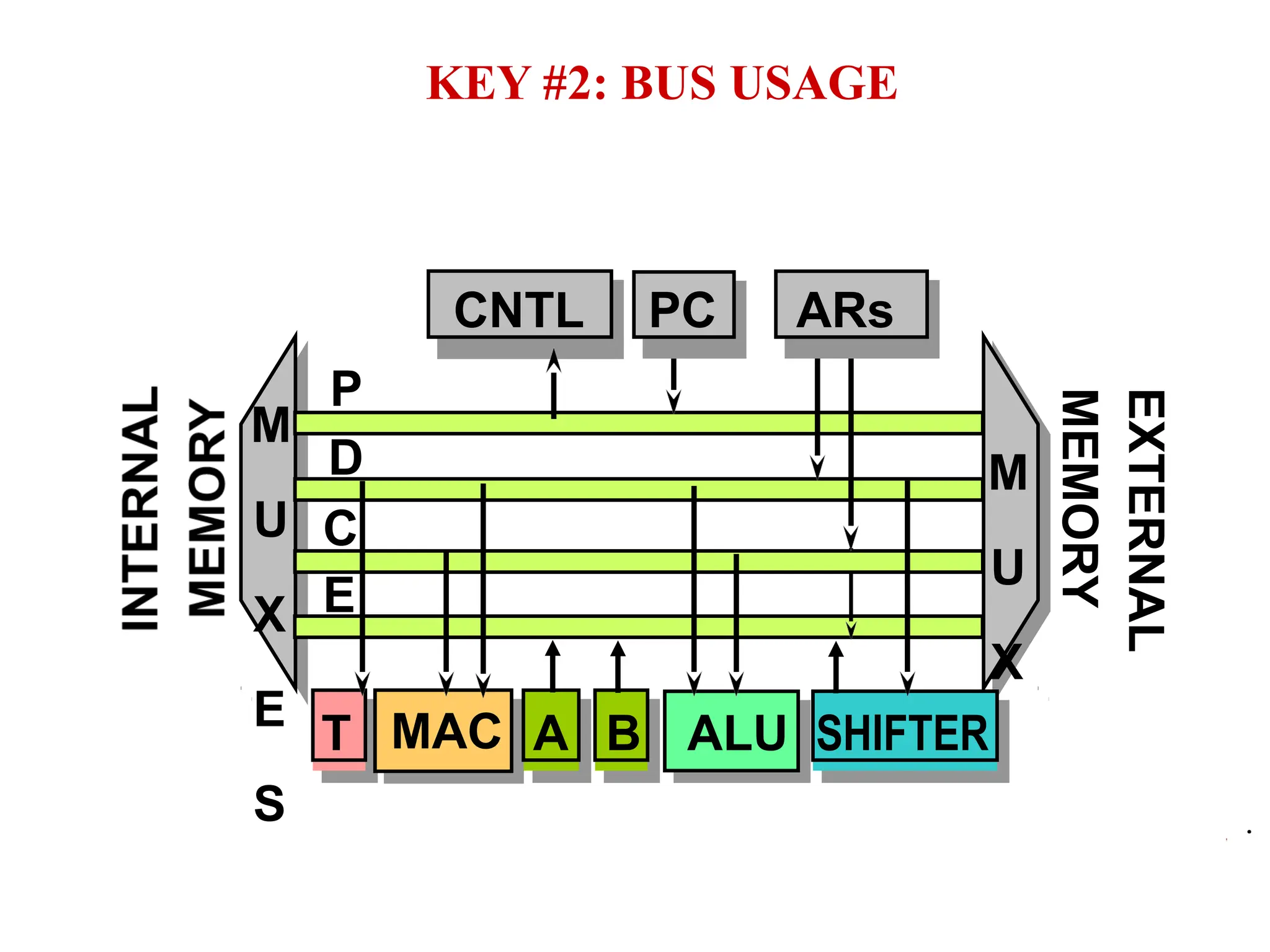
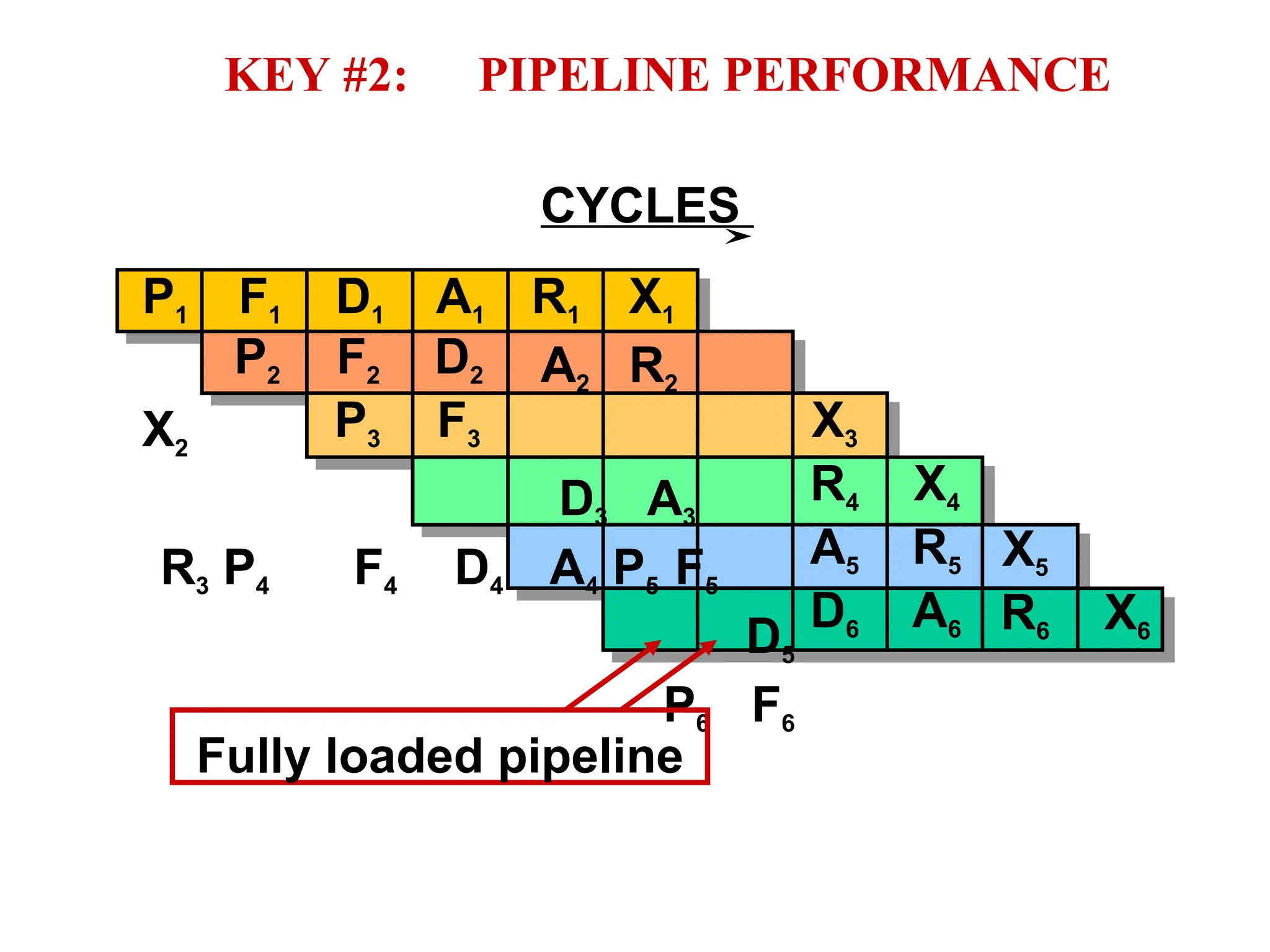
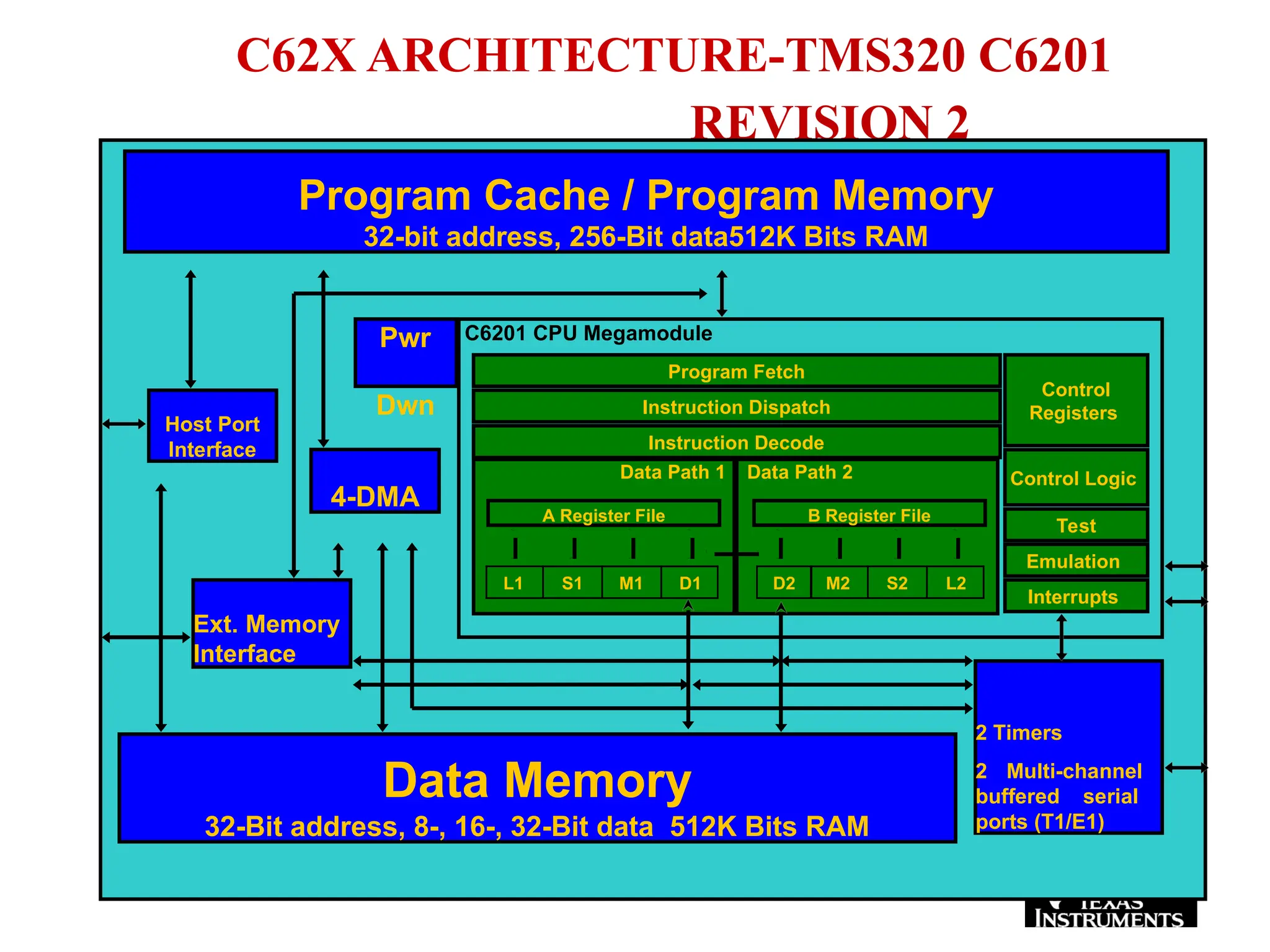
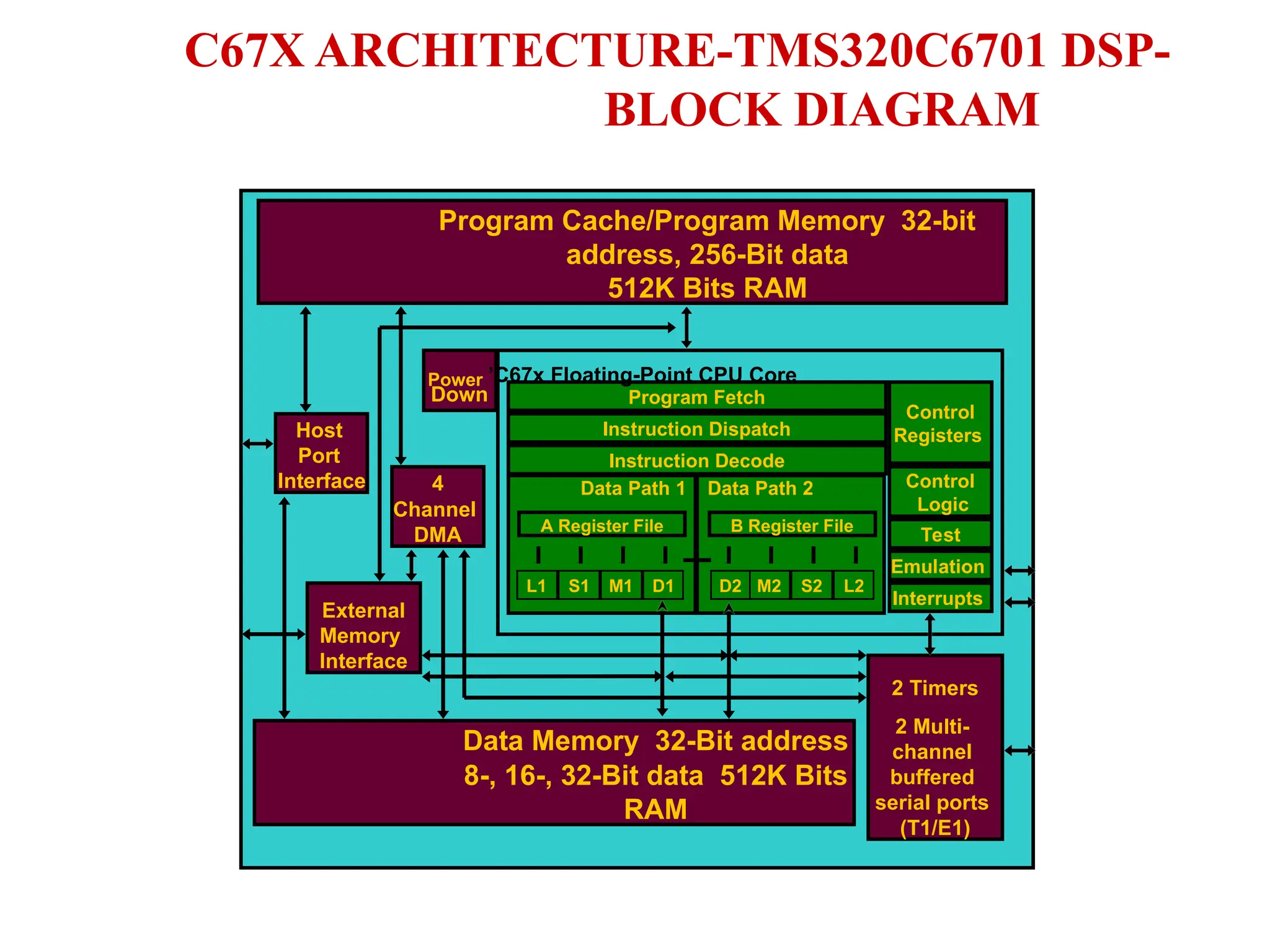
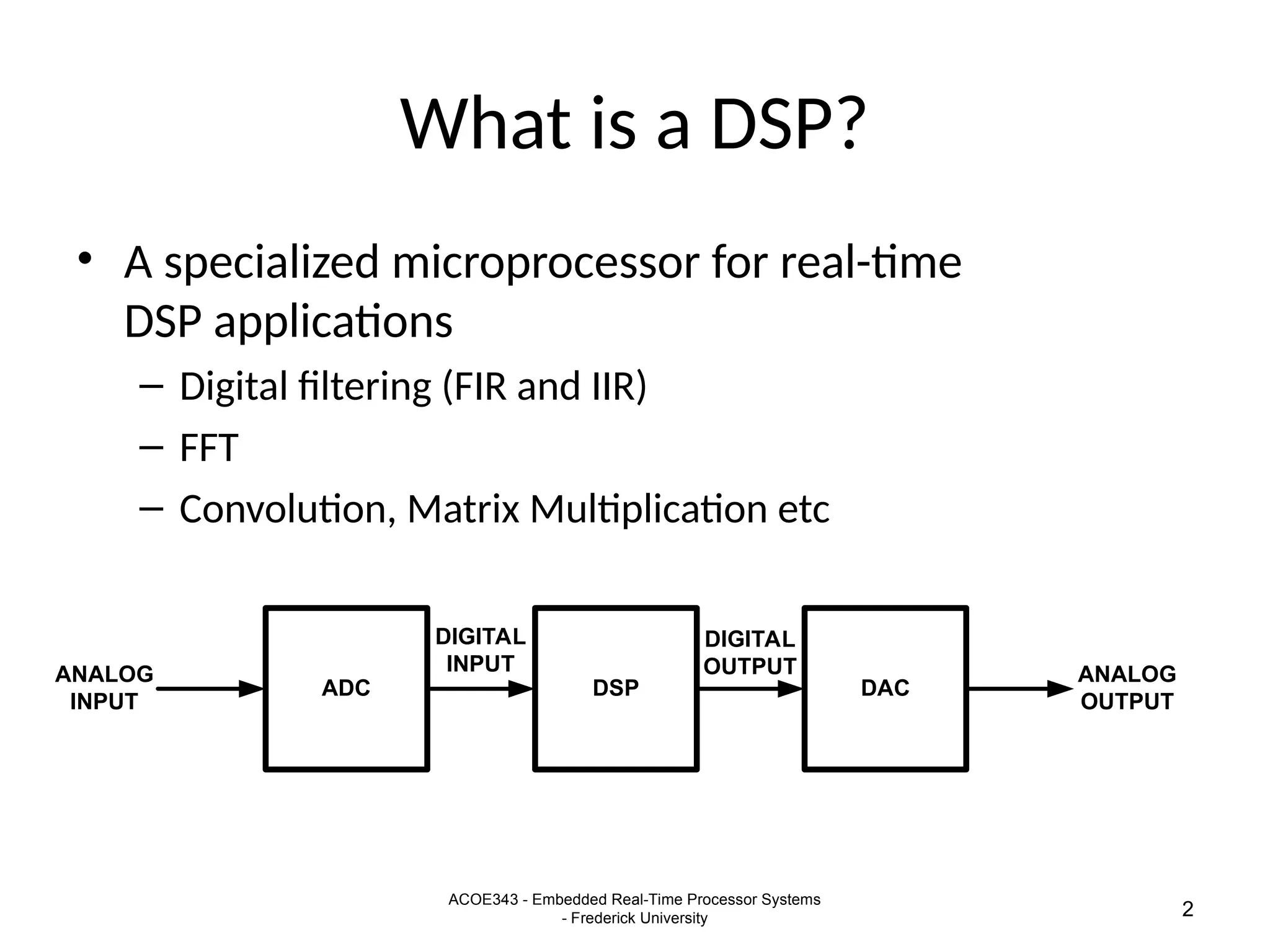
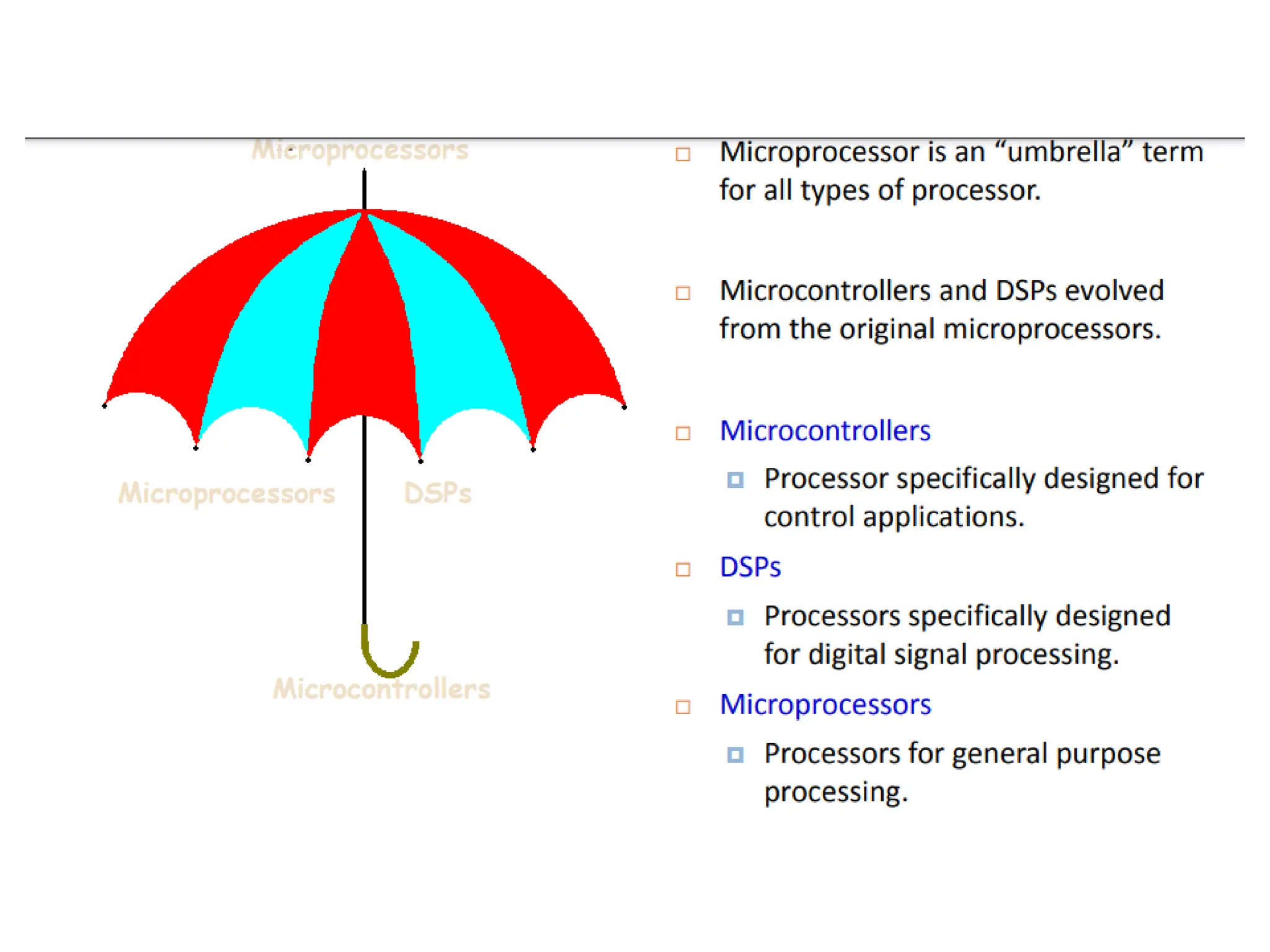
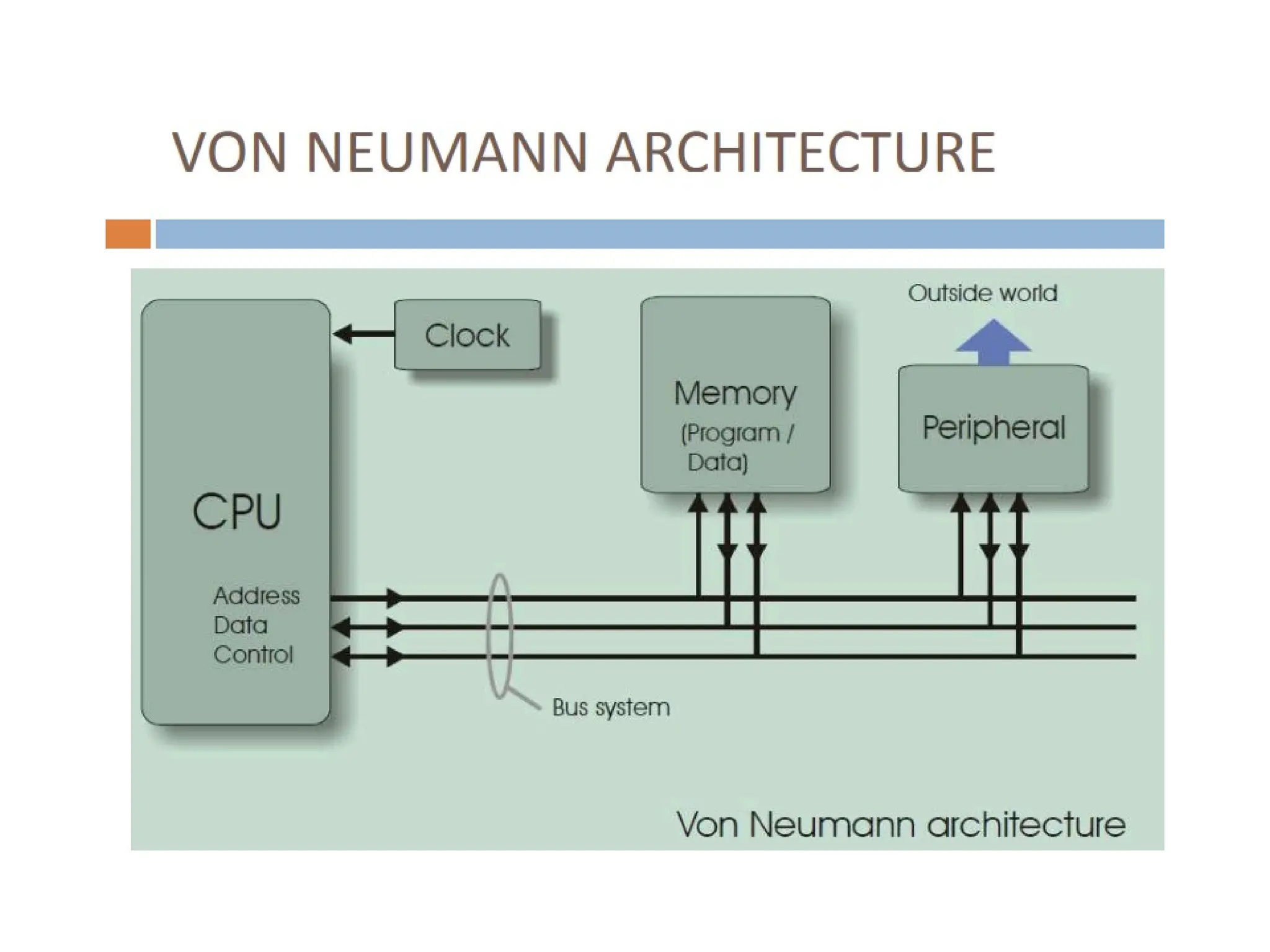
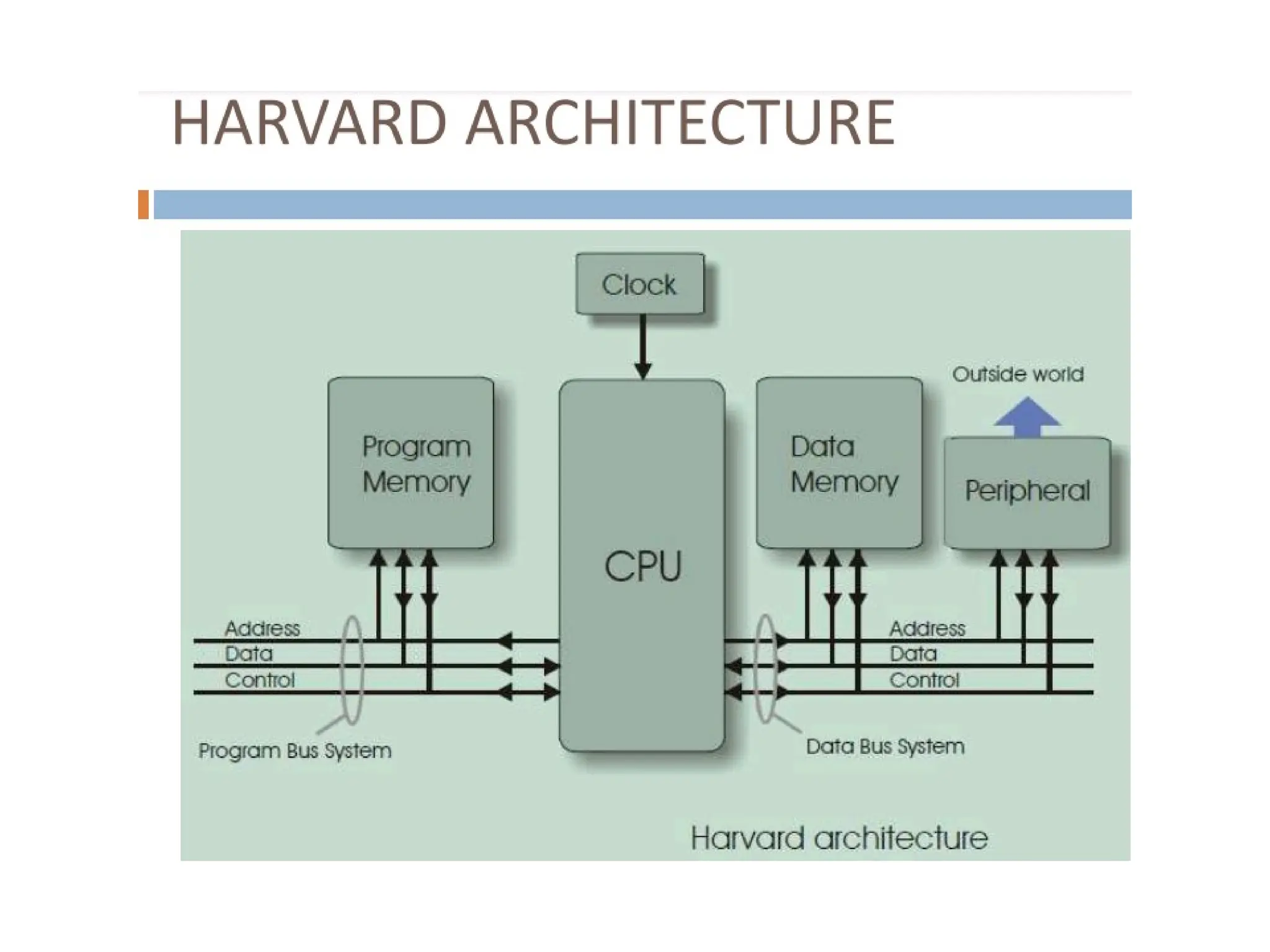
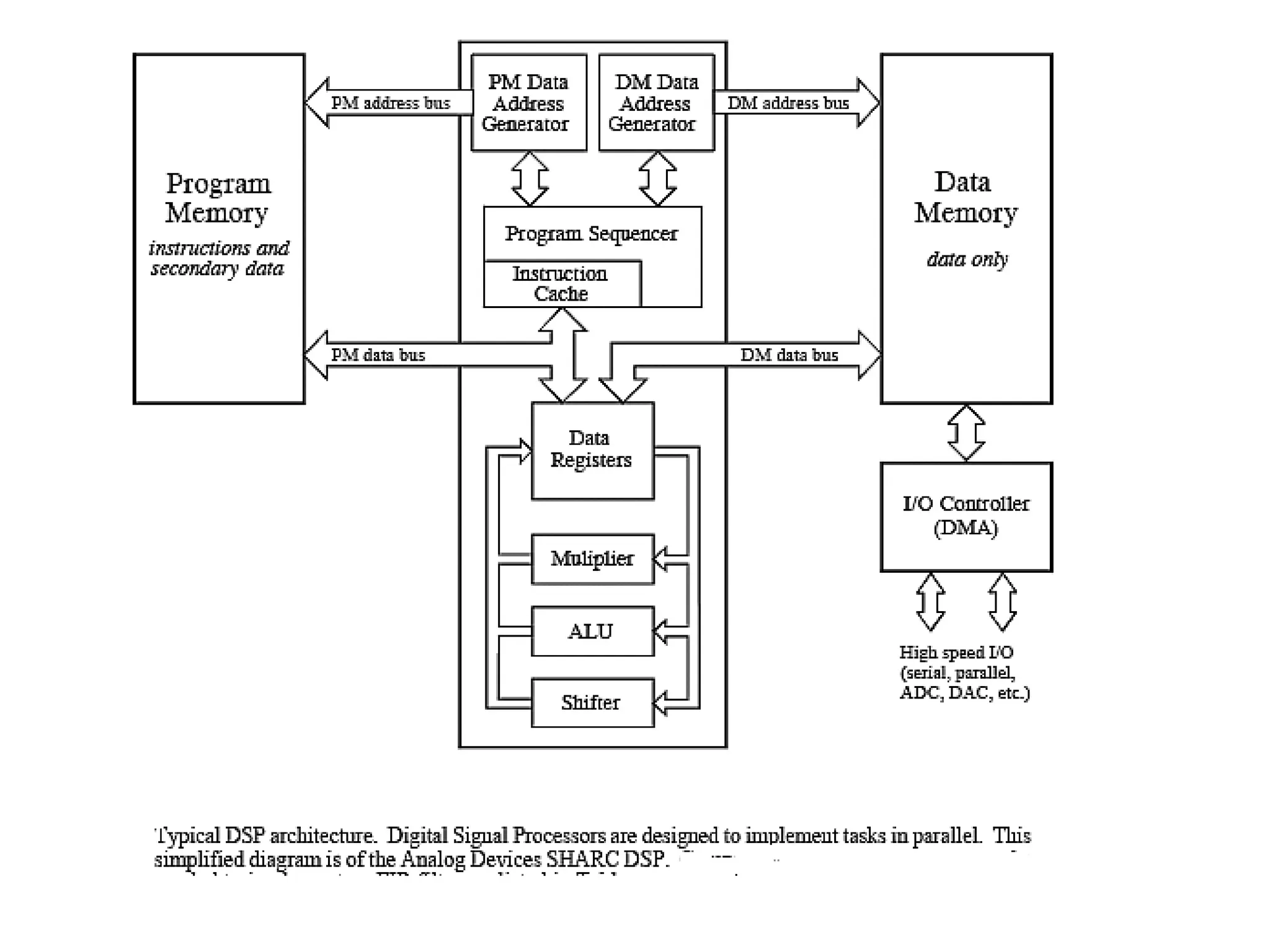
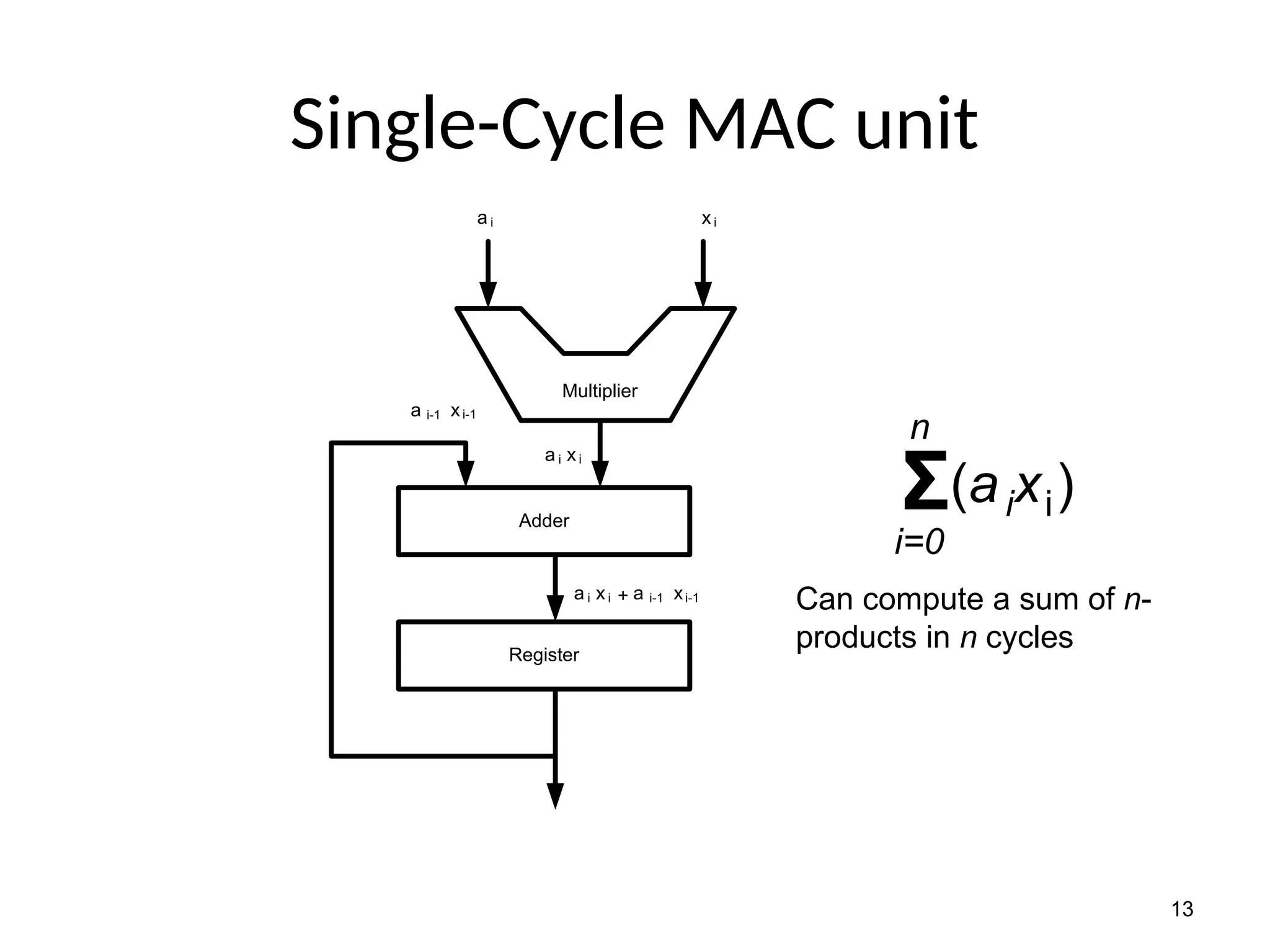
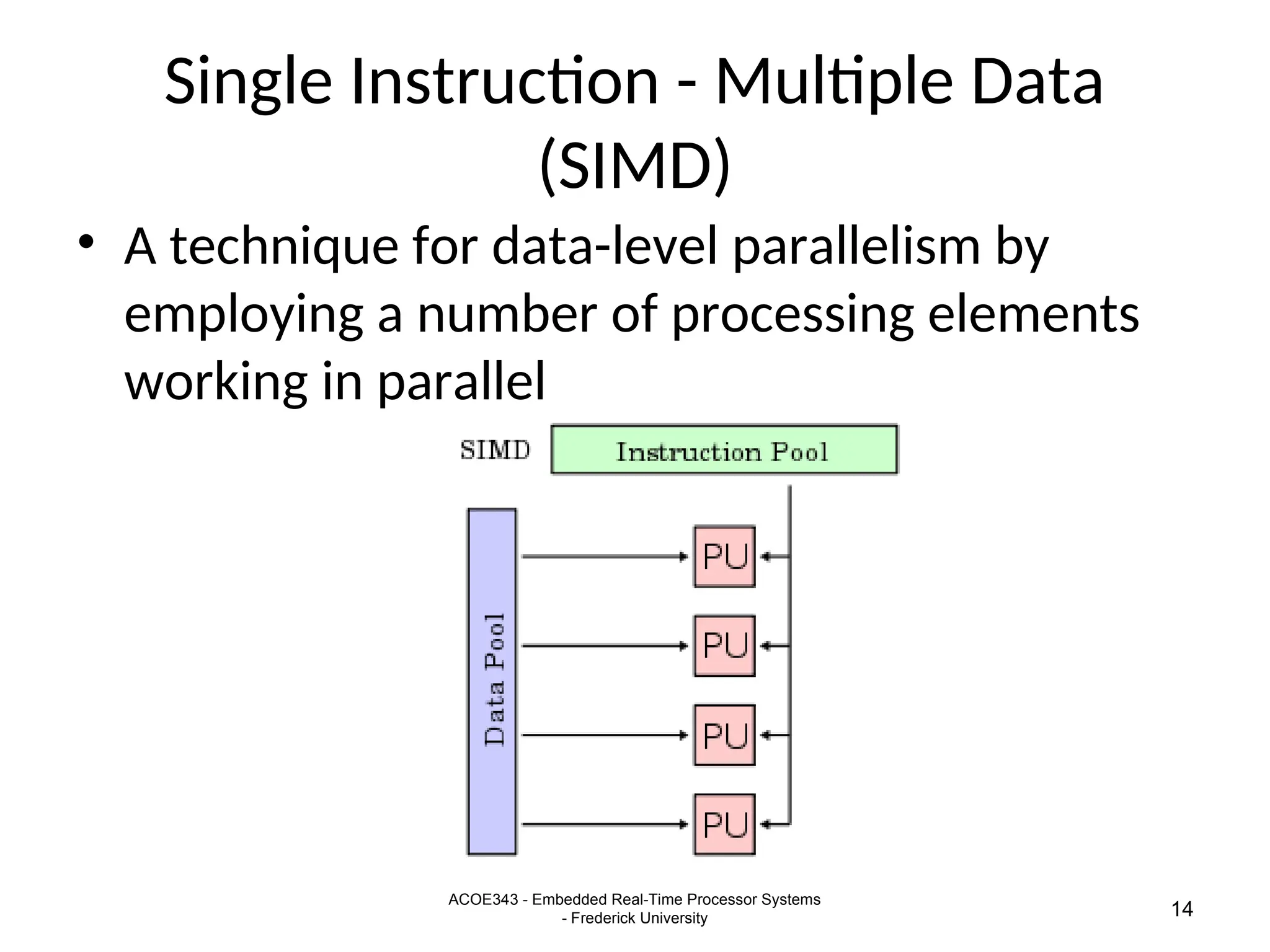
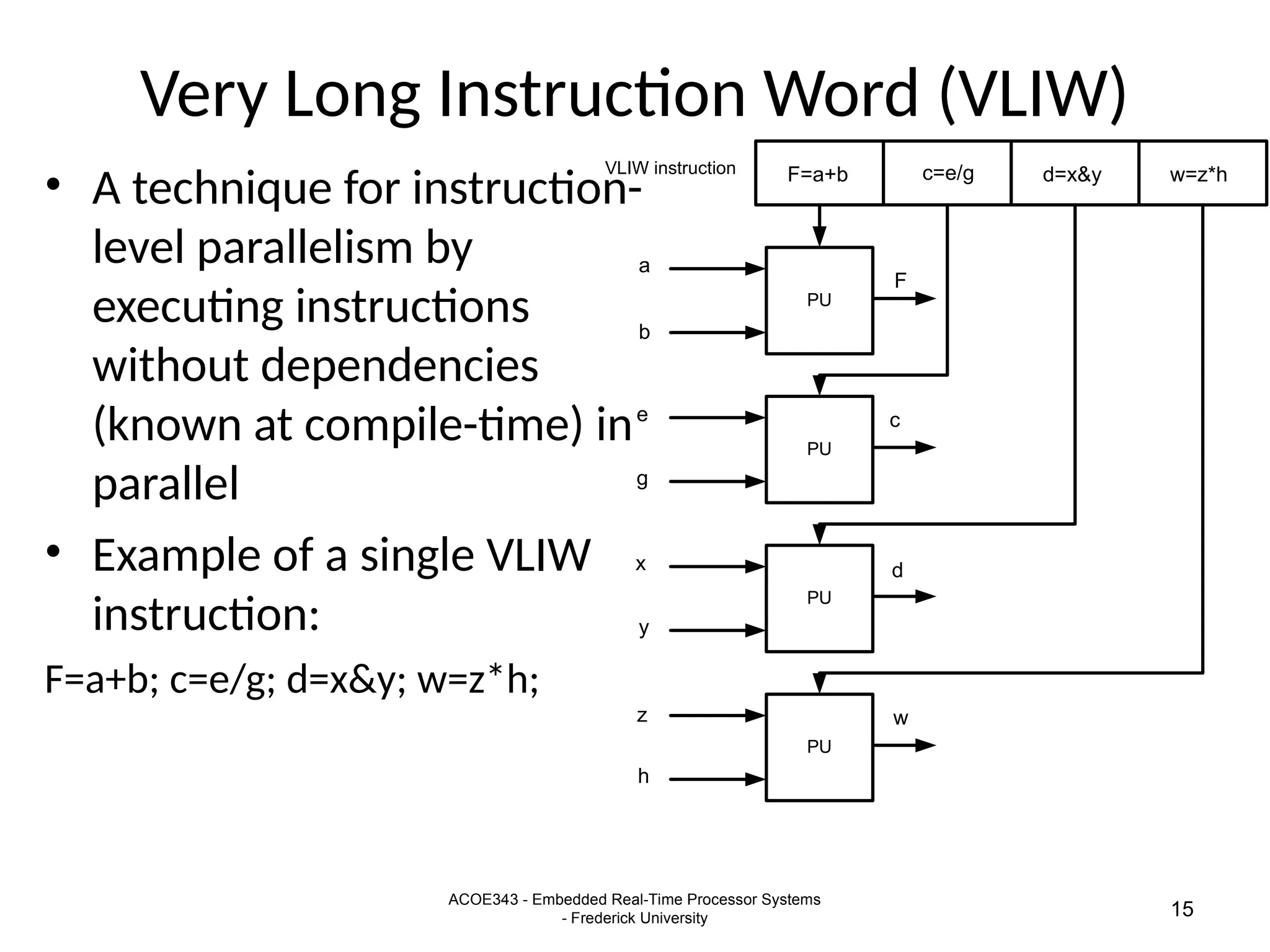
The document provides an overview of digital signal processing (DSP) and its key features, including specialized microprocessors designed for real-time applications like digital filtering, FFT, and convolution. It contrasts DSP architecture, which typically follows Harvard architecture with features like SIMD, VLIW, and hardware MAC units, against traditional microcontrollers that usually employ von Neumann architecture. Various examples of programmable DSPs, their applications, and architectural components are discussed, highlighting prominent manufacturers such as Texas Instruments.










![ACOE343 - Embedded Real-Time Processor Systems
- Frederick University 20
Hardware Circular Addressing
• A data structure
implementing a fixed length
queue of fixed size objects
where objects are added to
the head of the queue while
items are removed from the
tail of the queue.
• Requires at least 2 pointers
(head and tail)
• Extensively used in digital
filtering
y[n] = a0x[n]+a1x[n-1]+…+akx[n-k]
X[n]
X[n-1]
X[n-2]
X[n-3]
X[n]
X[n-1]
X[n-2]
X[n-3]
Head
Tail
Cycle1
Cycle2](https://image.slidesharecdn.com/unit-5-241205052029-93c64ba6/75/Yg-hvuihbijbh-itf-ygcinbjbiojbfhuujh-ppt-20-2048.jpg)