







![Introduction to Data Structures
One-dimensional Arrays
Example: Let NOFDAYS be an array of 12 element
representing total number of days in a month.
int NOFDAYS[12];
Then,
NOFDAYS[0] = 31 NOFDAYS[1] = 28
NOFDAYS[2] = 31 and so on...
The array will be represented as shown in the
following figure:
31 28 31 30 31 30
NOFDAYS[0] NOFDAYS[1] NOFDAYS[2]…
©NIIT Introduction to Data Structures/Lesson 1/Slide 8 of 34](https://image.slidesharecdn.com/ds1-120423051636-phpapp01/85/Ds-1-8-320.jpg)



![Introduction to Data Structures
Just a Minute…
2. Find the address of numbers [13] and numbers [40] of
the array numbers [40] assuming a Base address of
250 and length of each element as 4.
3. Matrix is an example of _________ dimensional
array.
4. How many types of arrays are available?
©NIIT Introduction to Data Structures/Lesson 1/Slide 13 of 34](https://image.slidesharecdn.com/ds1-120423051636-phpapp01/85/Ds-1-13-320.jpg)



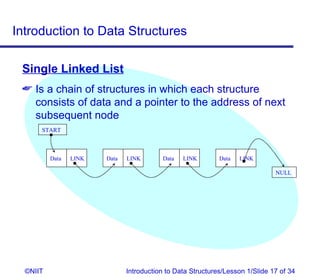
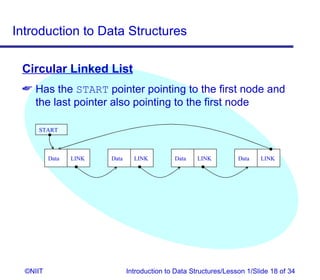






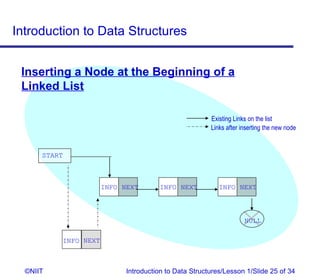

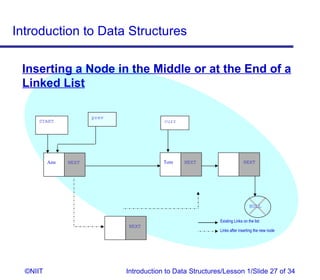








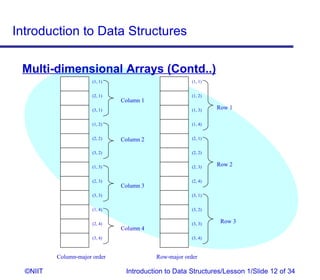
The document introduces data structures and their types. It discusses arrays, linked lists, and how to insert nodes in a single linked list. Specifically, it covers classifying data structures as static, dynamic or elastic. It also describes one-dimensional and multi-dimensional arrays, and different types of linked lists like single, circular and double linked lists. The key operations on linked lists are insertion, traversal, deletion and modification.






































































































