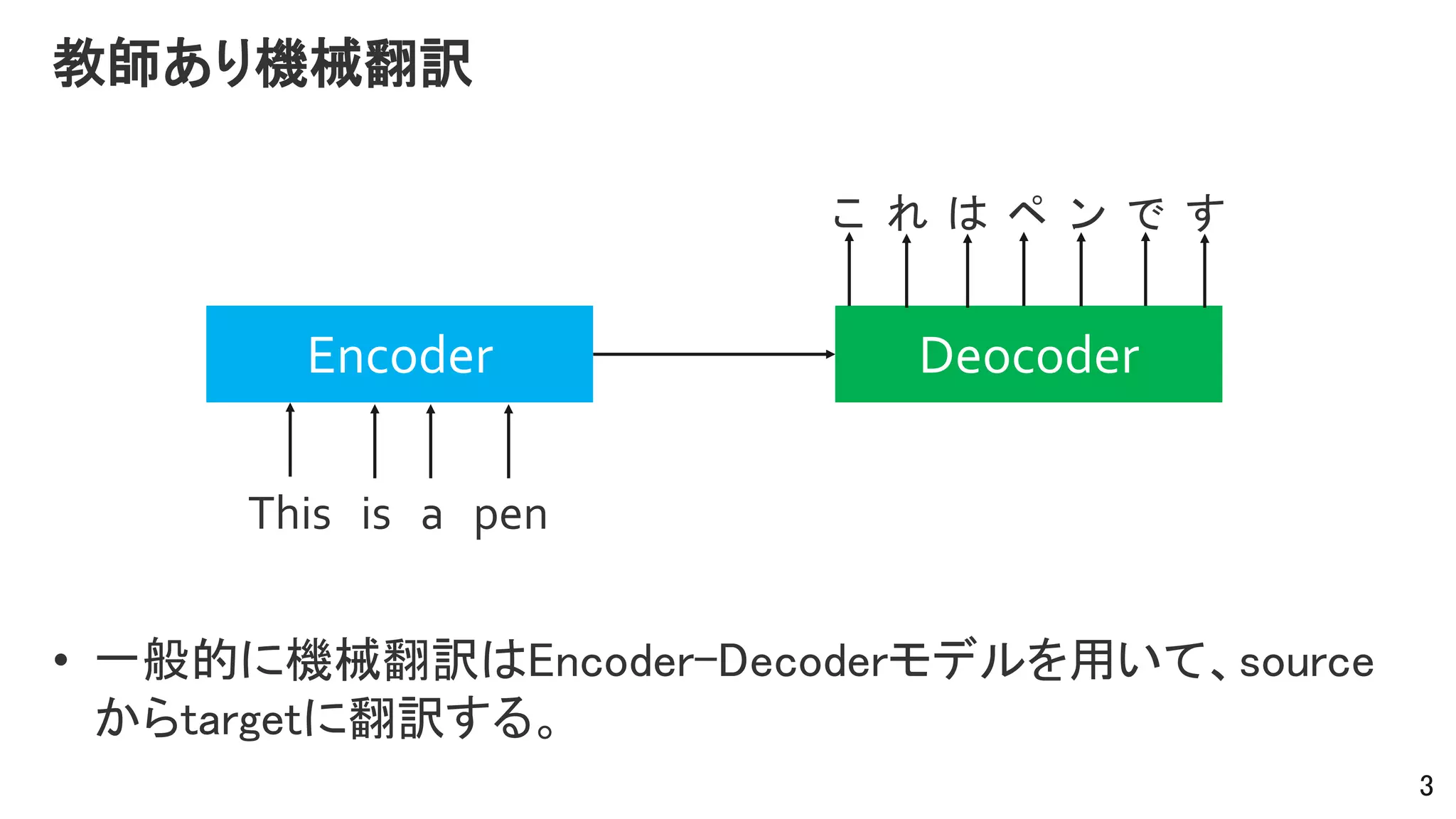
Teacher-student approach
A teacher-studentframework for zero-resource neural machine
translation. [Chen+ ACL2017]
• X-ZコーパスとZ-Yコーパスはあるが、X-Yコーパスはない。
• X->Yへ翻訳できるモデルが欲しい。
8
X
Z
Y
☓
9.
Teacher-student approach
A teacher-studentframework for zero-resource neural machine
translation. [Chen+ ACL2017]
• まず、Z-Yコーパスを用いてZ->Yへの翻訳モデルを学習し、Z->Y
モデルを教師とする
9
X
Z
Y
学習
10.
Teacher-student approach:
A teacher-studentframework for zero-resource neural machine
translation. [Chen+ ACL2017]
• XとZは異なる言語で同じ意味の文である場合、XからYへの翻訳
文とZからYへの翻訳文は同じになるという仮定から、
と の分布を近づけるように学習。 10
X
Z
Y
这是一支钢笔
これはペンです
日中(X-Z)の
対訳を使う
this an pen is
this is a pen
これらの分布を
近づける。
(KLを小さくする
ように学習)
![1
DEEP LEARNING JP
[DL Papers]
http://deeplearning.jp/
“Unsupervised Neural MachineTranslation(ICLR2018)”
MasashiYokota, Nakayama Lab](https://image.slidesharecdn.com/dlyokota20180316-180316003237/75/DL-Unsupervised-Neural-Machine-Translation-1-2048.jpg)

![教師あり機械翻訳の問題点
• 大量のparallel corpus が必要
– 十分な学習データがないと良い性能が得ることが難しいことは知られて
いる [Koehn & Knowles, ACL 2017]
– 十分な学習データを得にくいマイナー言語(ex. バスク語)の学習は特に
困難。
4](https://image.slidesharecdn.com/dlyokota20180316-180316003237/75/DL-Unsupervised-Neural-Machine-Translation-4-2048.jpg)
![リソースの少ない言語への取り組み
• Pivot-base approach:
Neural machine translation with pivot languages.[Cheng+
CoRR2016]
• teacher-student approach:
A teacher-student framework for zero-resource neural machine
translation. [Chen+ ACL2017]
5](https://image.slidesharecdn.com/dlyokota20180316-180316003237/75/DL-Unsupervised-Neural-Machine-Translation-5-2048.jpg)
![Pivot-base approach
Neural machine translation with pivot languages.[Cheng+
CoRR2016]
6
• X-ZコーパスとZ-Yコーパスがそれぞれあり、X-Y
コーパスがない場合。XからZに翻訳し、さらにZからYを翻訳(ピ
ボット)することで結果としてX->Yへの翻訳を行う。](https://image.slidesharecdn.com/dlyokota20180316-180316003237/75/DL-Unsupervised-Neural-Machine-Translation-6-2048.jpg)

![Teacher-student approach
A teacher-student framework for zero-resource neural machine
translation. [Chen+ ACL2017]
• X-ZコーパスとZ-Yコーパスはあるが、X-Yコーパスはない。
• X->Yへ翻訳できるモデルが欲しい。
8
X
Z
Y
☓](https://image.slidesharecdn.com/dlyokota20180316-180316003237/75/DL-Unsupervised-Neural-Machine-Translation-8-2048.jpg)
![Teacher-student approach
A teacher-student framework for zero-resource neural machine
translation. [Chen+ ACL2017]
• まず、Z-Yコーパスを用いてZ->Yへの翻訳モデルを学習し、Z->Y
モデルを教師とする
9
X
Z
Y
学習](https://image.slidesharecdn.com/dlyokota20180316-180316003237/75/DL-Unsupervised-Neural-Machine-Translation-9-2048.jpg)
![Teacher-student approach:
A teacher-student framework for zero-resource neural machine
translation. [Chen+ ACL2017]
• XとZは異なる言語で同じ意味の文である場合、XからYへの翻訳
文とZからYへの翻訳文は同じになるという仮定から、
と の分布を近づけるように学習。 10
X
Z
Y
这是一支钢笔
これはペンです
日中(X-Z)の
対訳を使う
this an pen is
this is a pen
これらの分布を
近づける。
(KLを小さくする
ように学習)](https://image.slidesharecdn.com/dlyokota20180316-180316003237/75/DL-Unsupervised-Neural-Machine-Translation-10-2048.jpg)

















![まとめと感想
• 完全な教師なし学習で機械翻訳を学習する手法を提案
– Denoising:
ノイズを入れた文からノイズを除去する
– On-the-fly backtranslation:
学習中のモデルを使って擬似的対訳コーパスを作成し学習
• 教師なし学習の提案の貢献は非常に大きいが、性能的には改善
の余地が大いにある
• Dual learning for machine translation [He+ NIPS2016]のように上
手く強化学習を取り入れられたら、もっと性能上がりそう。
29](https://image.slidesharecdn.com/dlyokota20180316-180316003237/75/DL-Unsupervised-Neural-Machine-Translation-29-2048.jpg)









![[最新版] JSAI2018 チュートリアル「"深層学習時代の" ゼロから始める自然言語処理」](https://cdn.slidesharecdn.com/ss_thumbnails/jsai2018tutorialslideshare-180607030706-thumbnail.jpg?width=640&height=640&fit=bounds)










![[旧版] JSAI2018 チュートリアル「"深層学習時代の" ゼロから始める自然言語処理」](https://cdn.slidesharecdn.com/ss_thumbnails/jsai2018tutorialslideshare-180606065226-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]GraphSeq2Seq: Graph-Sequence-to-Sequence for Neural Machine Translation](https://cdn.slidesharecdn.com/ss_thumbnails/20181117graphseq2seqkayama-181116022737-thumbnail.jpg?width=640&height=640&fit=bounds)






















