Downloaded 14 times


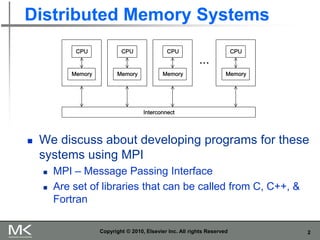













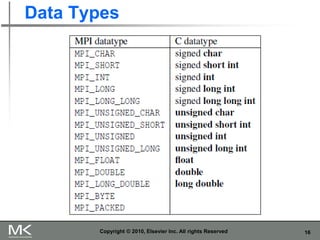

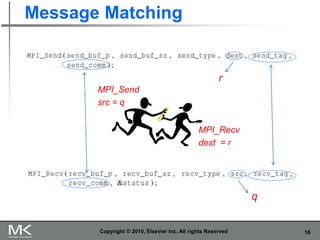



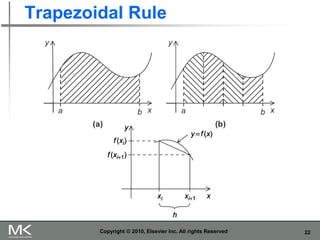








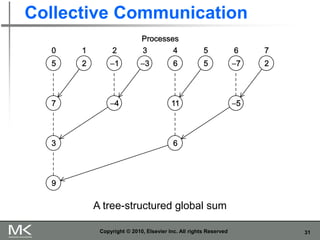
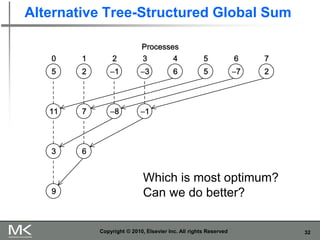

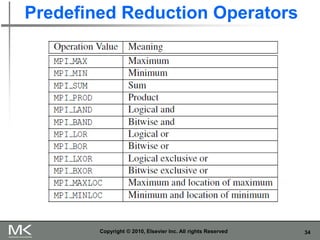



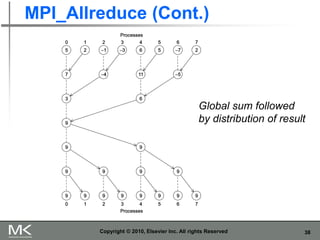
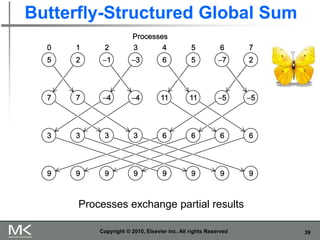

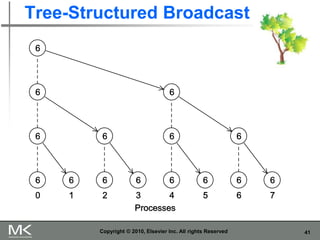

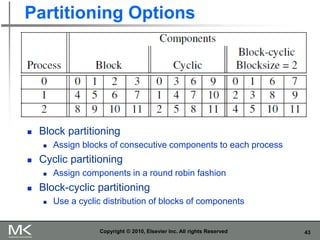





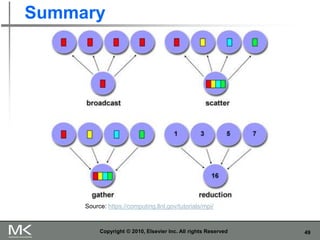

The document provides an overview of distributed memory programming using the Message Passing Interface (MPI), detailing its components, functions, and communication methods. It highlights the structure of MPI programs, explains the single-program multiple-data (SPMD) model, and covers important functions for message sending and receiving. Additionally, it discusses collective versus point-to-point communication, as well as techniques for data distribution and processing in parallel computing.























































































