Download to read offline





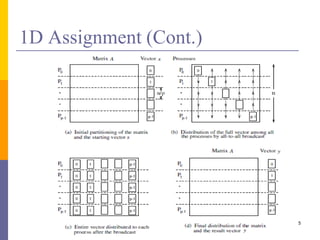
![1D Assignment – MPI Based
Implementation
For i-th process
a[i] = read(a[i]); //read row i
x = read(x[i]); //read part of vector
MPI_allgather(x, allx);
y = CalculateY(a[i], allx);
Write(y);
6](https://image.slidesharecdn.com/12-hardtoparalelizeproblems-240417105111-9be0efba/85/Hard-to-Paralelize-Problems-Matrix-Vector-and-Matrix-Matrix-6-320.jpg)

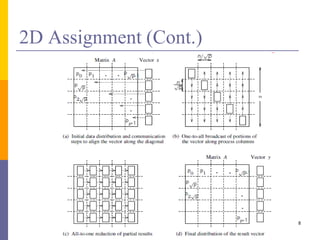
![2D Assignment (Cont.)
For (i, j)-th process
a[x][y] = read(a[x][y]);
If(j == n)
x = read(x[i]);
MPI_Send(x, (i, i))
If(i == j){
MPI_Receive(&block)
MPI_Broadcast(block, j);
blockRecv = block;
}
else{ //receive block from others
MPI_Broadcast(&block, 1, &blockRecv, 1, (j, j));
}
y(I, j ) = Calculate();
//reduce it at the 0th on earch row
MPI_REDUCE(y(I, j), 1, &resultrcv, 1, (i, 0));
write(&resultrcv);
9](https://image.slidesharecdn.com/12-hardtoparalelizeproblems-240417105111-9be0efba/85/Hard-to-Paralelize-Problems-Matrix-Vector-and-Matrix-Matrix-9-320.jpg)


![ Map
Make (key, value) pairs out of matrices mij & njk
Produce (j, (M, i, mij) and (j, (N, k, njk)
Reduce
Produce for each j (j, (i, k, mij, njk))
Map again
Produce [((i1, k1), m1j*nj1), ((i2, k2), m2j*nj2), …, ((ip, kp), mpj*njp)]
Reduce again
For each (i, k) pair sum all & produce ((i, k), v)
Matrix-Matrix Multiplication
12](https://image.slidesharecdn.com/12-hardtoparalelizeproblems-240417105111-9be0efba/85/Hard-to-Paralelize-Problems-Matrix-Vector-and-Matrix-Matrix-12-320.jpg)

The document discusses several problems that are hard to parallelize, including matrix-vector multiplication and matrix-matrix multiplication. It describes 1D and 2D assignment approaches to parallelizing matrix-vector multiplication across multiple processors. 1D assignment distributes the rows of the matrix and vector across processors, while 2D assignment distributes them in a 2D grid. It also outlines map-reduce approaches to parallelizing vector-matrix and matrix-matrix multiplication, breaking the problems into mapping and reducing stages.



































































