Downloaded 21 times








![MPI Example – Hello World
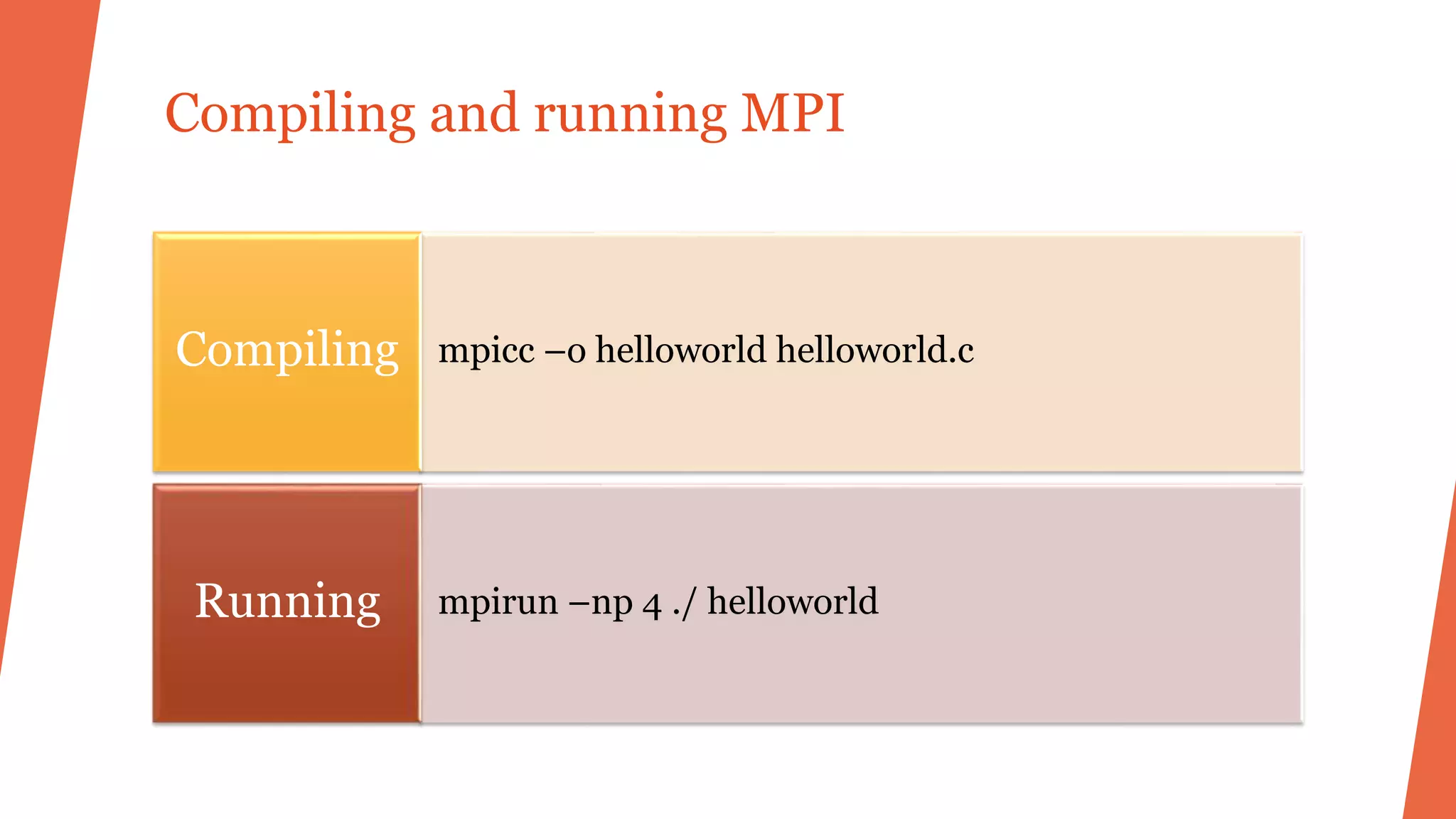
#include "mpi.h"
#include <stdio.h>
int main( int argc, char *argv[] )
{
int rank, size; MPI_Init( &argc, &argv );
MPI_Comm_rank( MPI_COMM_WORLD, &rank );
MPI_Comm_size( MPI_COMM_WORLD, &size );
printf( "Hello World from process %d of %dn", rank, size );
MPI_Finalize();
return 0;
}](https://image.slidesharecdn.com/myppthpcu4-170504100438/75/My-ppt-hpc-u4-11-2048.jpg)













![Variables
A thread can access its own private variables, but cannot access the
private variable of another thread.
In parallel for pragma, variables are by default shared, except
loop index variable which is private.
#pragma omp parallel for private(privDbl )
for ( i = 0; i < arraySize; i++ ) {
for ( privIndx = 0; privIndx < 16; privIndx++ ) { privDbl = ( (double)
privIndx ) / 16;
y[i] = sin( exp( cos( - exp( sin(x[i]) ) ) ) ) + cos( privDbl );
}
}](https://image.slidesharecdn.com/myppthpcu4-170504100438/75/My-ppt-hpc-u4-26-2048.jpg)


![OpenMP compiler directives (Pragma)
A compiler directive in C or c++ is called a pragma.
Format:
#pragma omp directive-name [clause,..]
1. #pragma omp parallel
Block of code should be executed by all of the threads (code block is
replicated among the threads)
use curly braces {} to create a block of code from a statement group.](https://image.slidesharecdn.com/myppthpcu4-170504100438/75/My-ppt-hpc-u4-29-2048.jpg)
![OpenMP compiler directives (Pragma)
2. #pragma omp parallel for
indicate to the compiler that the iterations of a for loop may
be executed in parallel.
e.g.
#pragma omp parallel for
for (i = first; i < size; i += prime)
marked[i] = 1;](https://image.slidesharecdn.com/myppthpcu4-170504100438/75/My-ppt-hpc-u4-30-2048.jpg)


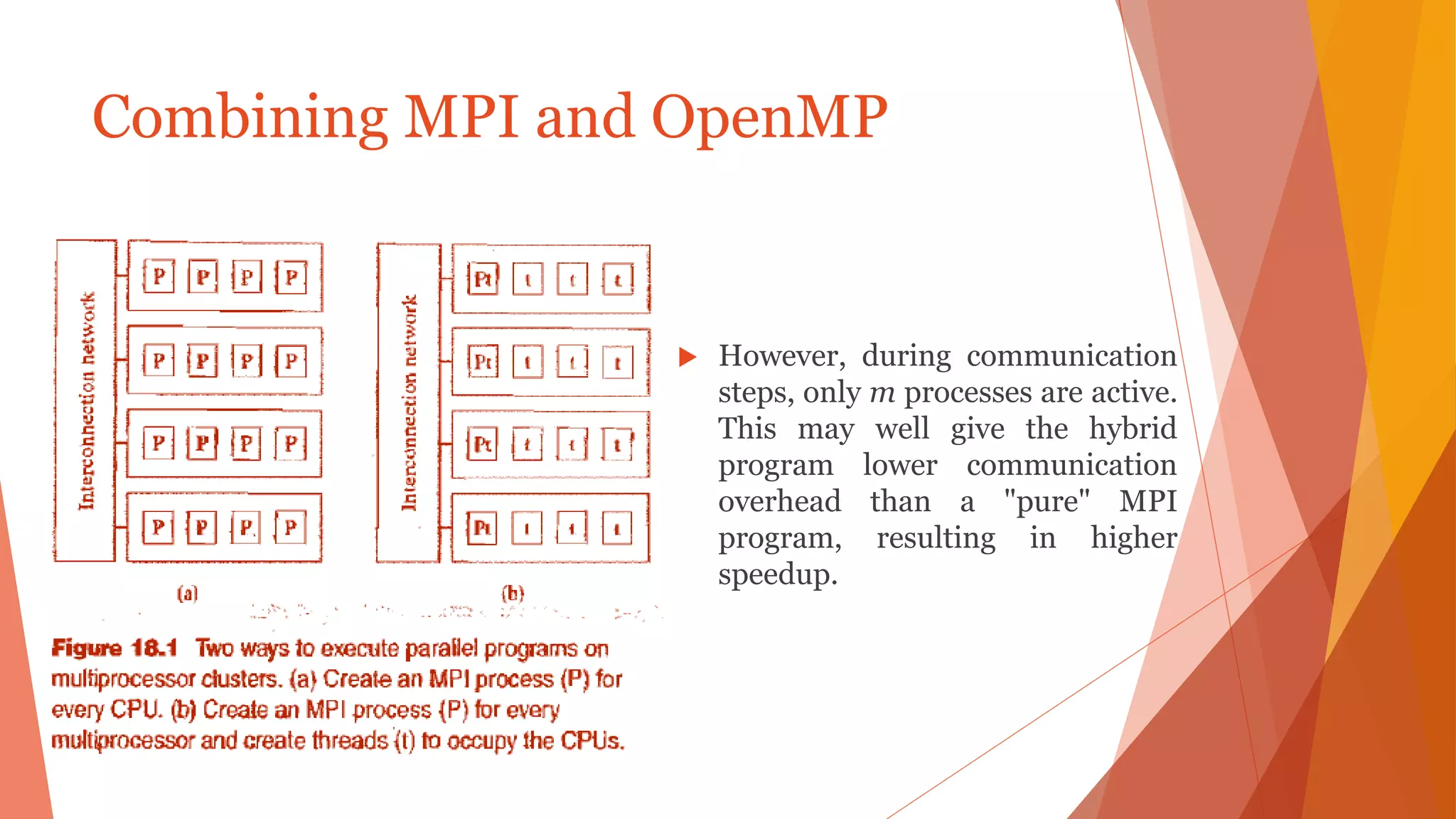
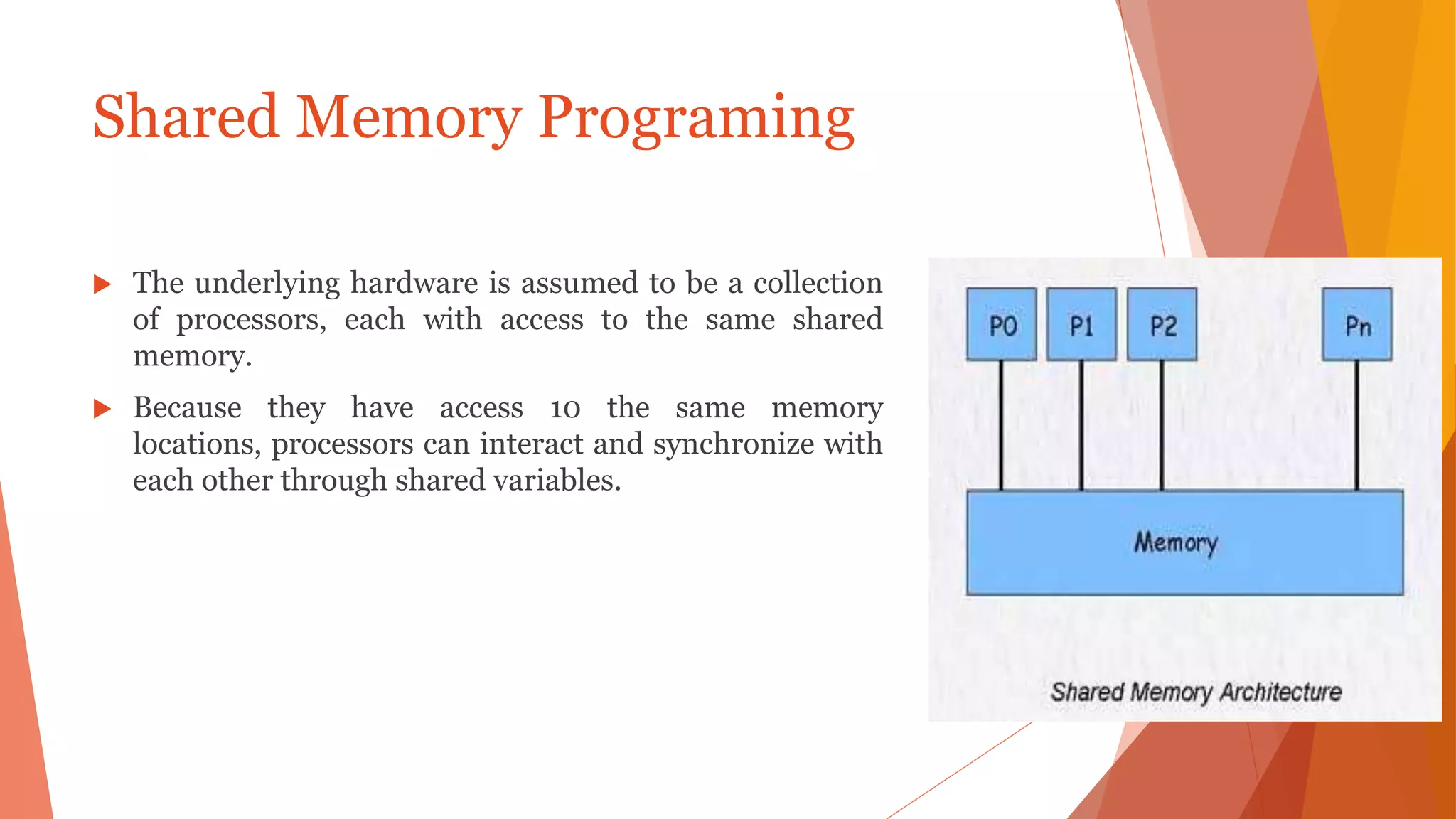

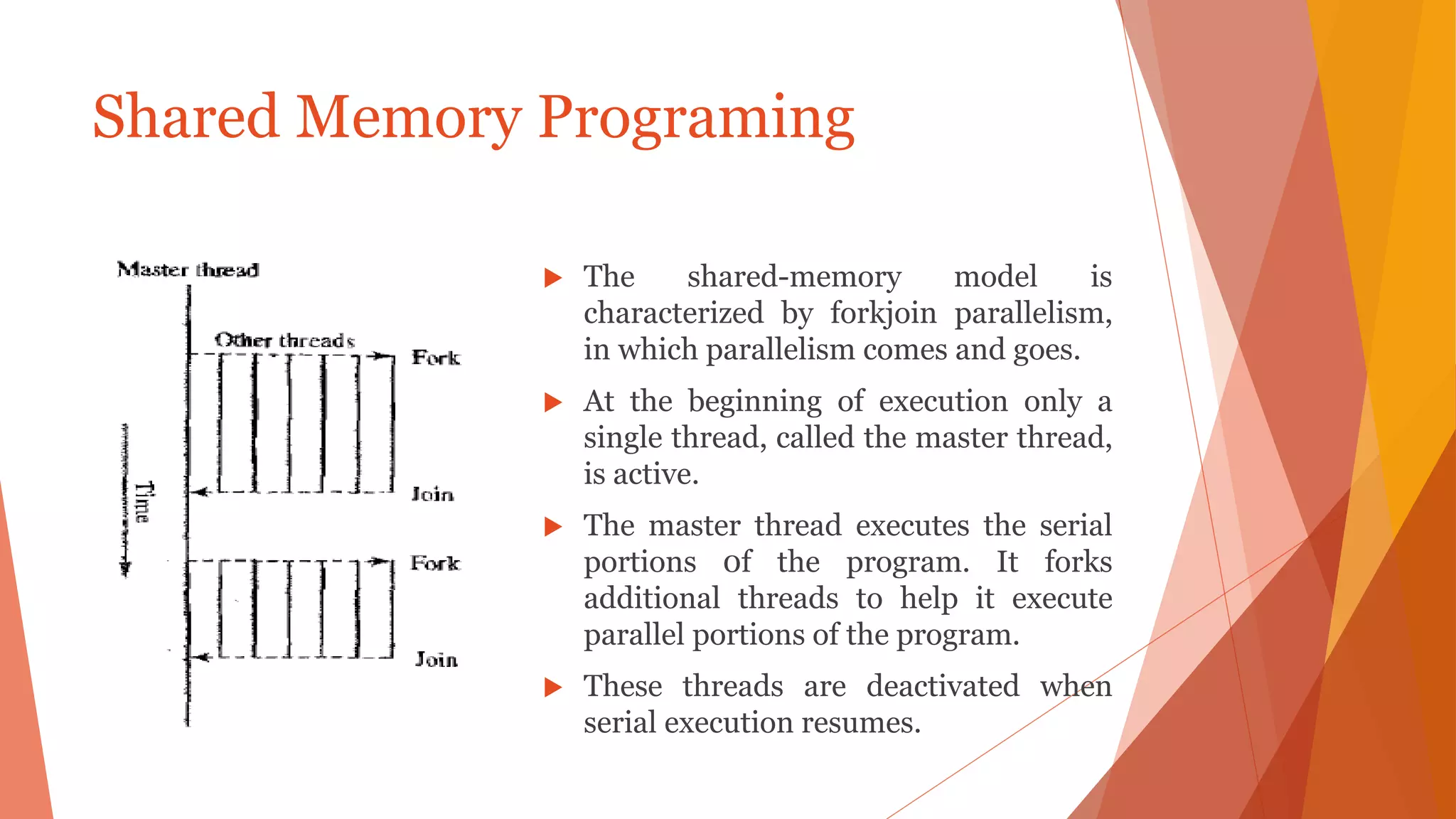




The document outlines key concepts of MPI (Message Passing Interface) and OpenMP (Open Multi-Processing) for parallel programming, discussing principles, building blocks, communication methods, and synchronization constructs of both models. MPI eliminates the need for shared memory architectures, while OpenMP facilitates shared memory multiprocessing through thread-based parallelism using directives. The document also highlights the benefits and drawbacks of both MPI and OpenMP, as well as their combined usage for optimized hybrid programming.

















































![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)









![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)


![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)


