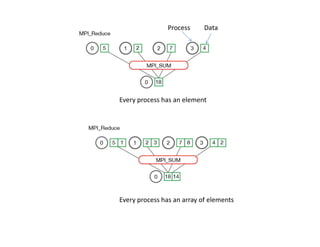
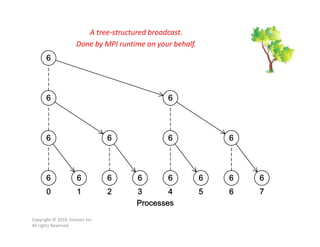
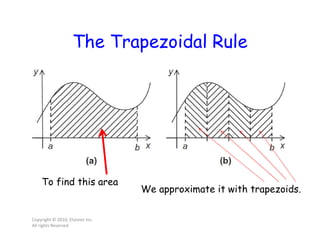
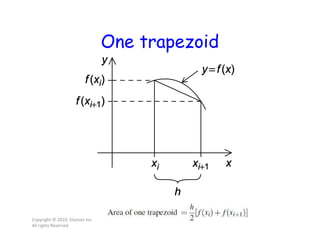
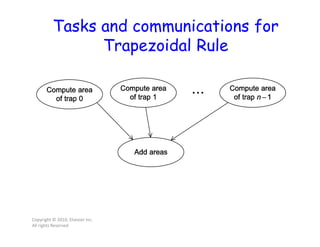
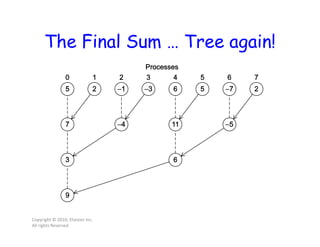
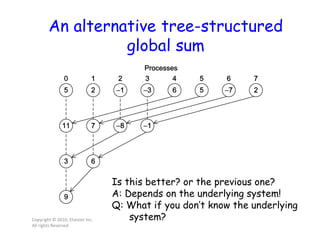
This document discusses parallel computing concepts in MPI including I/O, input/output, and collective communication functions. It introduces MPI functions like MPI_Reduce, MPI_Allreduce, and MPI_Bcast that allow processes to collectively perform operations like summation and broadcasting data. Examples are provided to illustrate how to parallelize the trapezoidal rule for numerical integration and handle input/output across processes.














![Reduction
• Reducing a set of numbers into a smaller
set of numbers via a function
– Example: reducing the group [1, 2, 3, 4, 5]
with the sum function 15
• MPI provides a handy function that
handles almost all of the common
reductions that a programmer needs to
do in a parallel application](https://image.slidesharecdn.com/mpi21-200417022429/85/MPI-2-19-320.jpg)