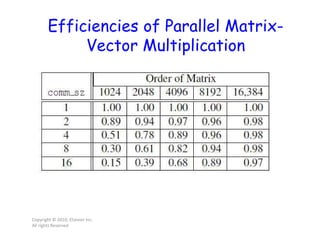
This document discusses parallel computing concepts like MPI, data distributions, scatter, gather, allgather operations, and matrix-vector multiplication. It explains how to distribute data across processes, use MPI routines to share data, implement parallel matrix-vector multiplication, and measure performance of serial vs parallel versions. Derivative datatypes are also introduced to efficiently describe complex data structures for communication.





![Parallel implementation of
vector addition
Copyright © 2010, Elsevier Inc.
All rights Reserved
How will you distribute parts of x[] and y[] to processes?](https://image.slidesharecdn.com/mpi31-200417022452/85/MPI-3-5-320.jpg)



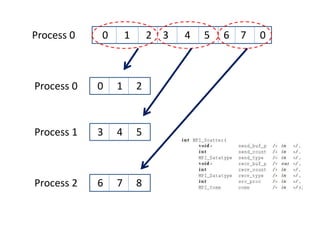






![Serial matrix-vector multiplication
Let’s assume x[] is distributed among the different processes](https://image.slidesharecdn.com/mpi31-200417022452/85/MPI-3-17-320.jpg)

































![Data Structures - Lecture 1 [introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/lecture-1introduction-141217054305-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)















































