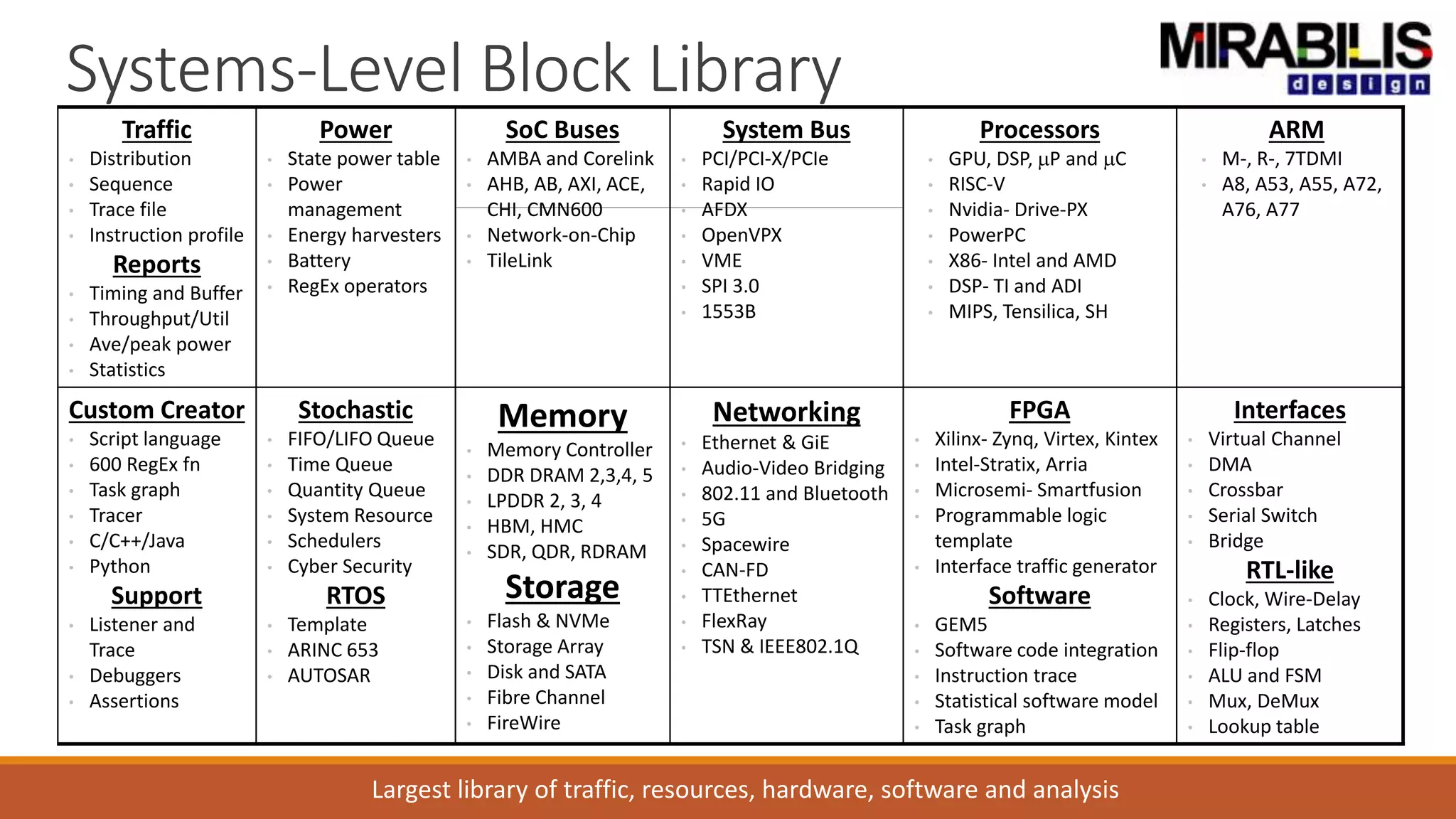
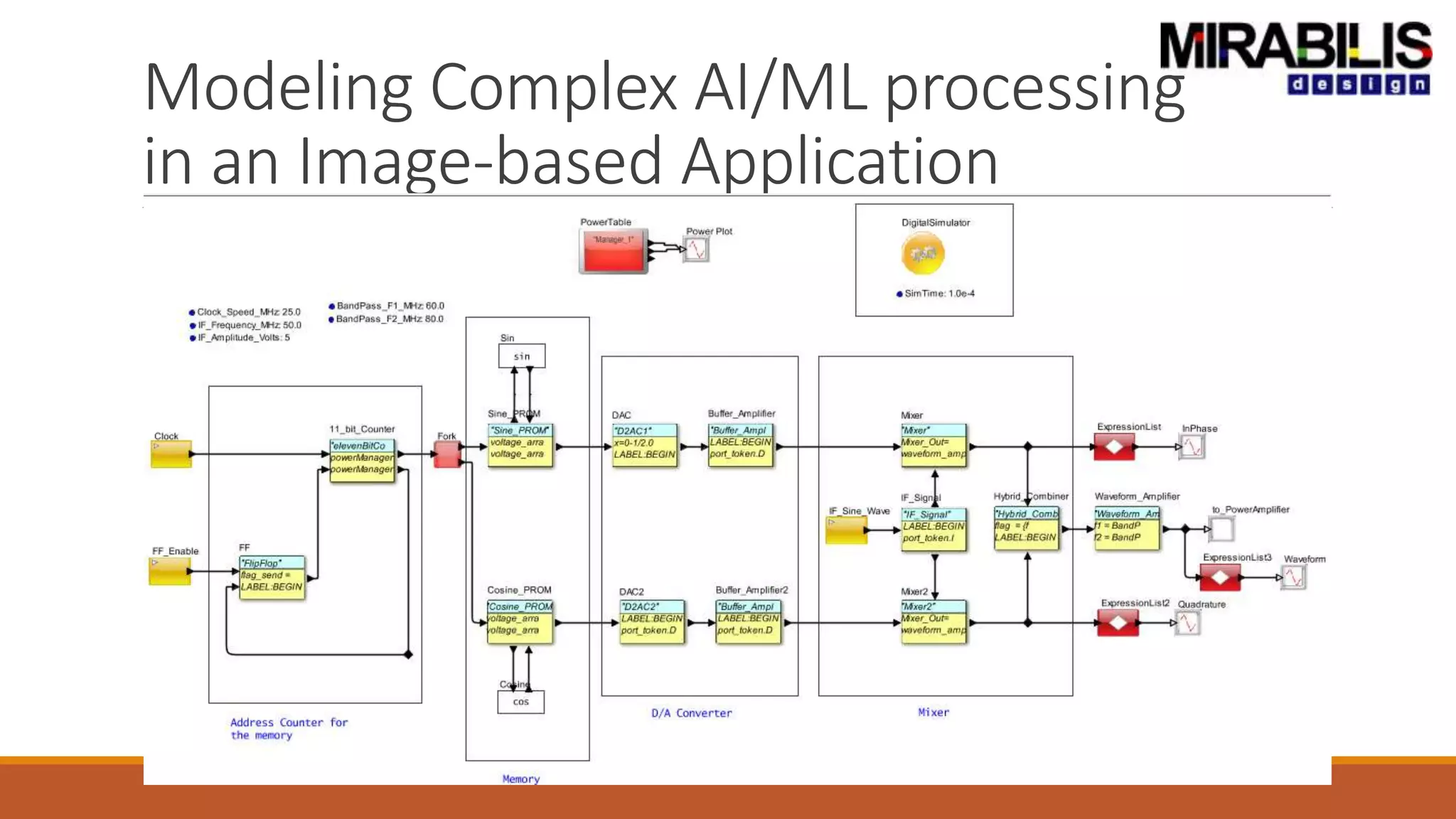
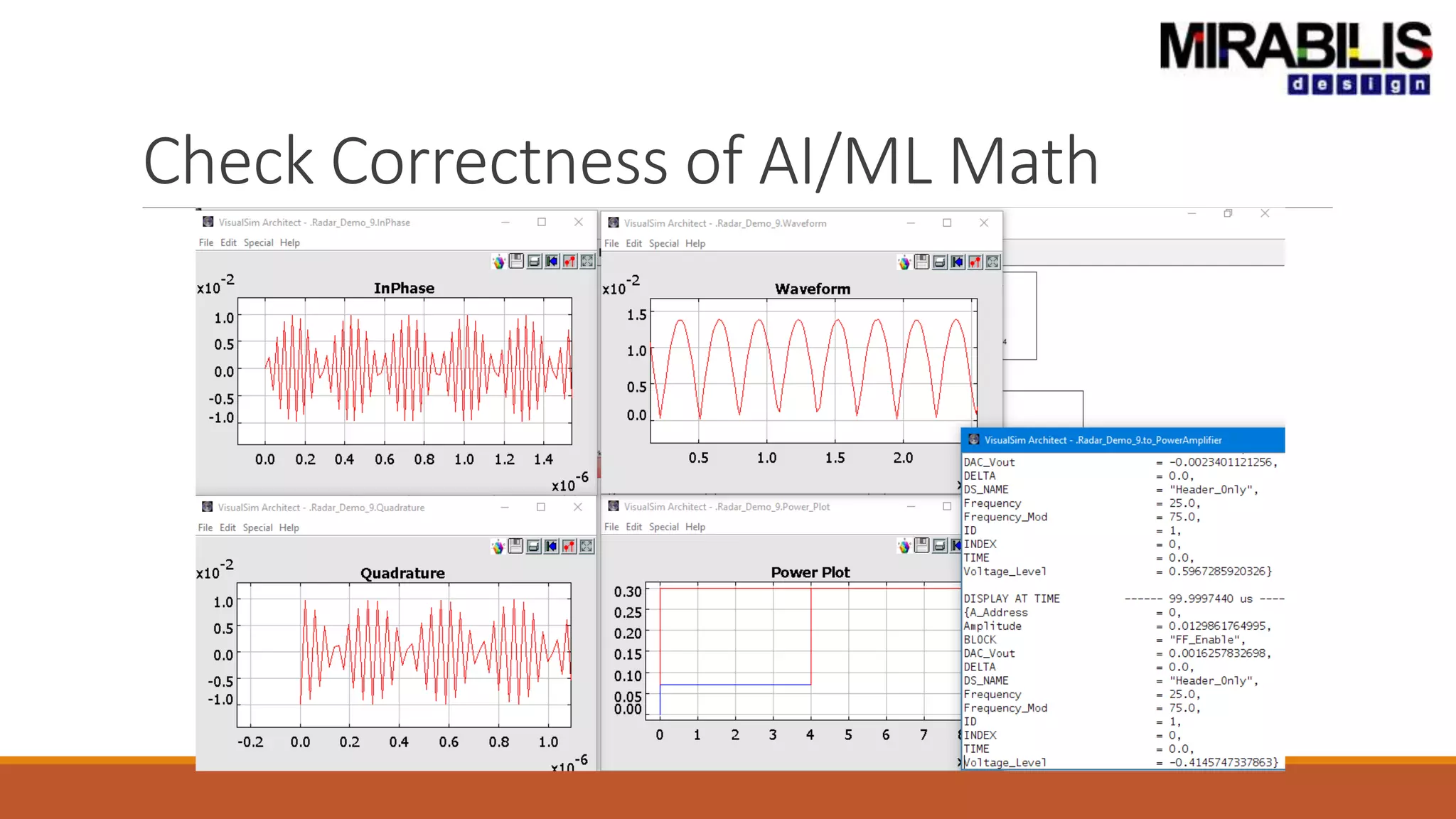
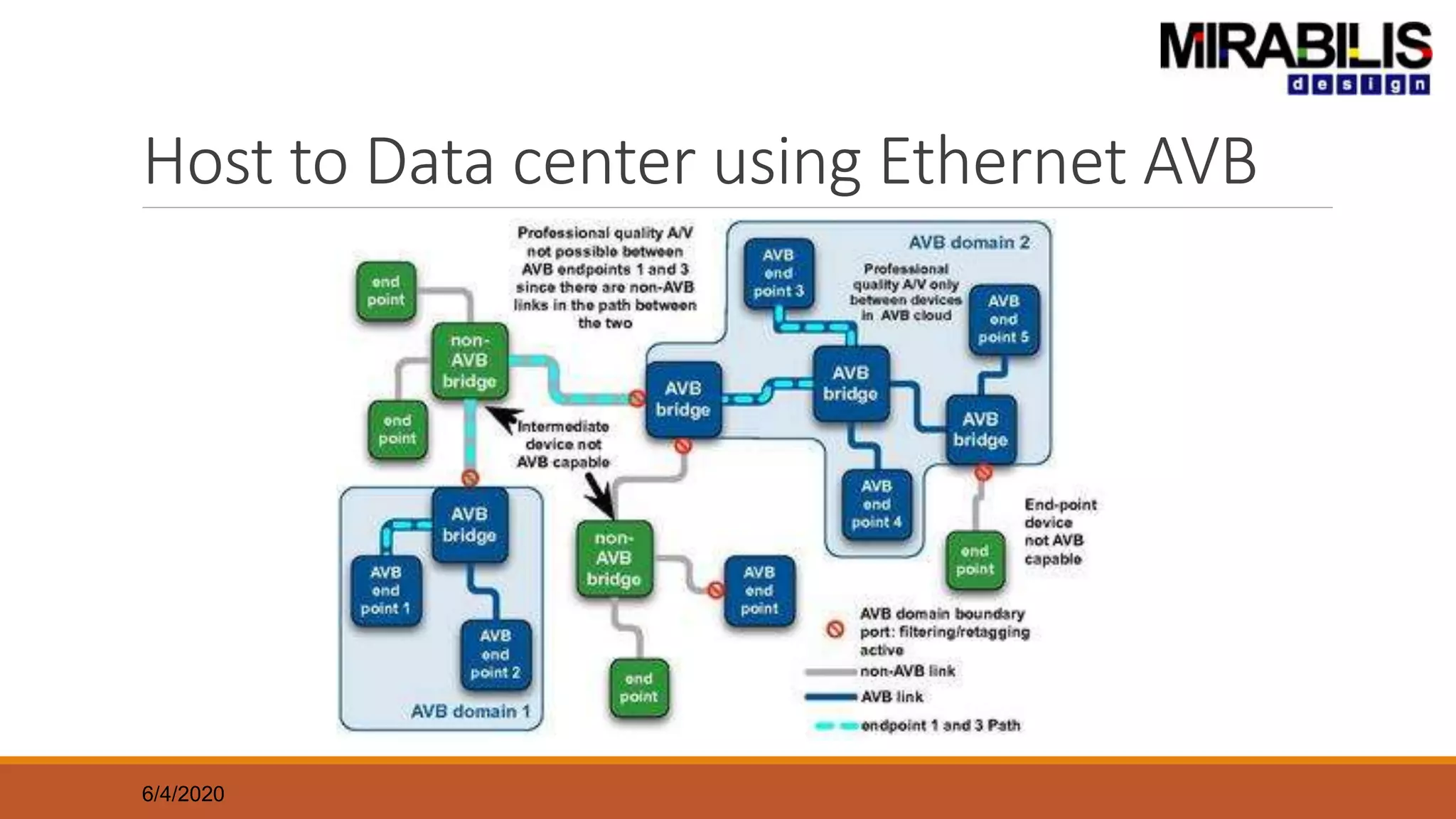
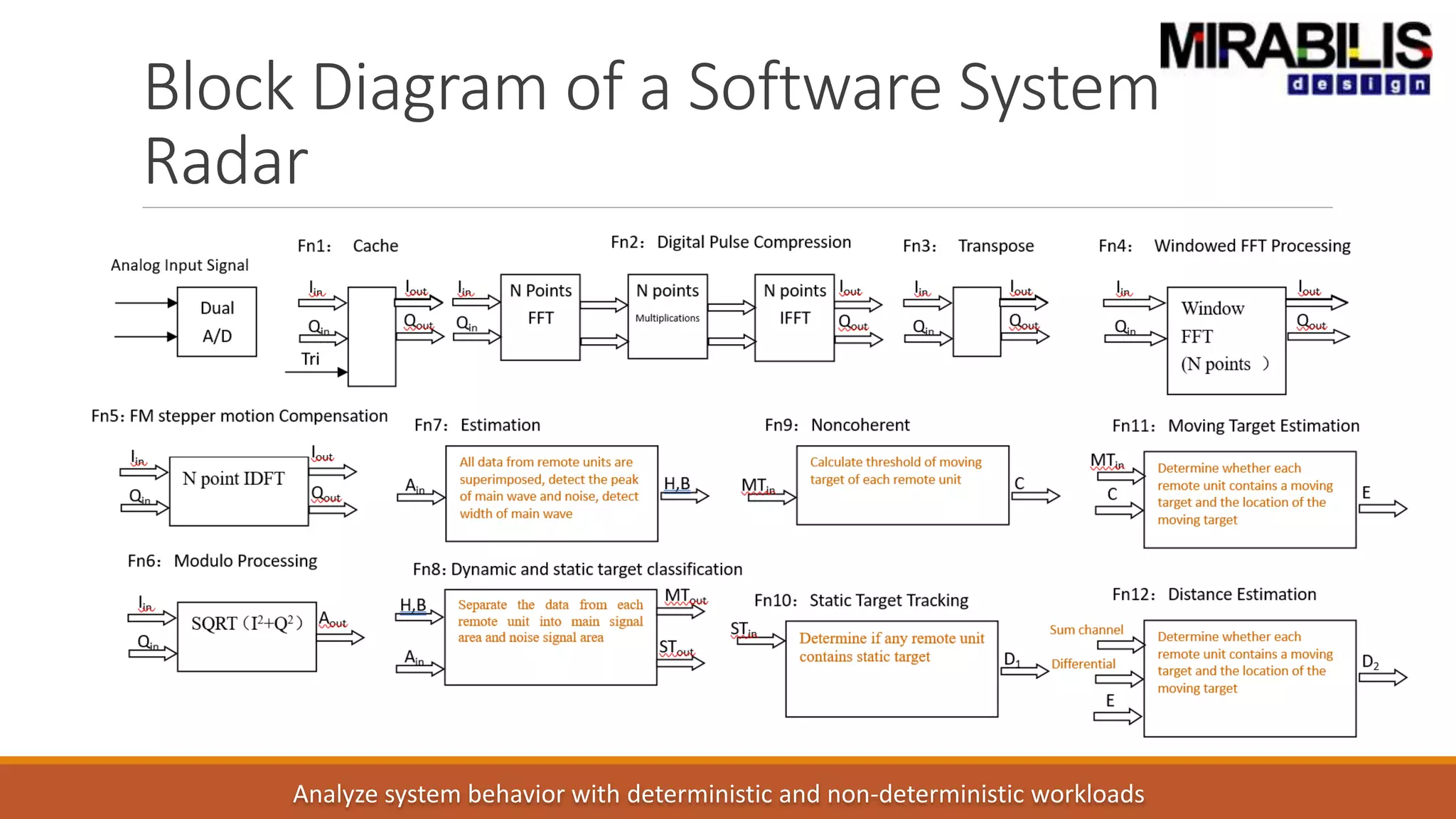
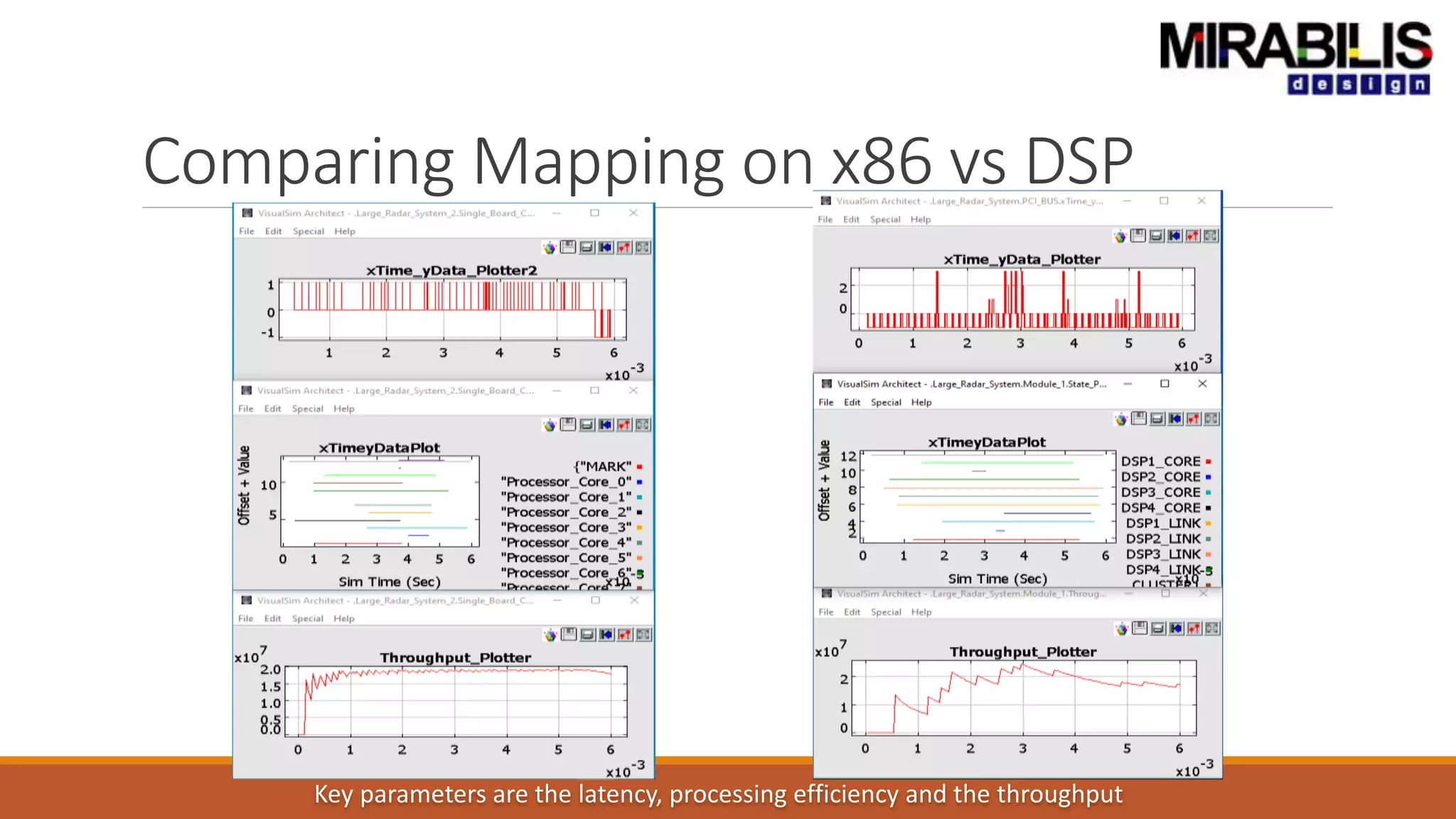
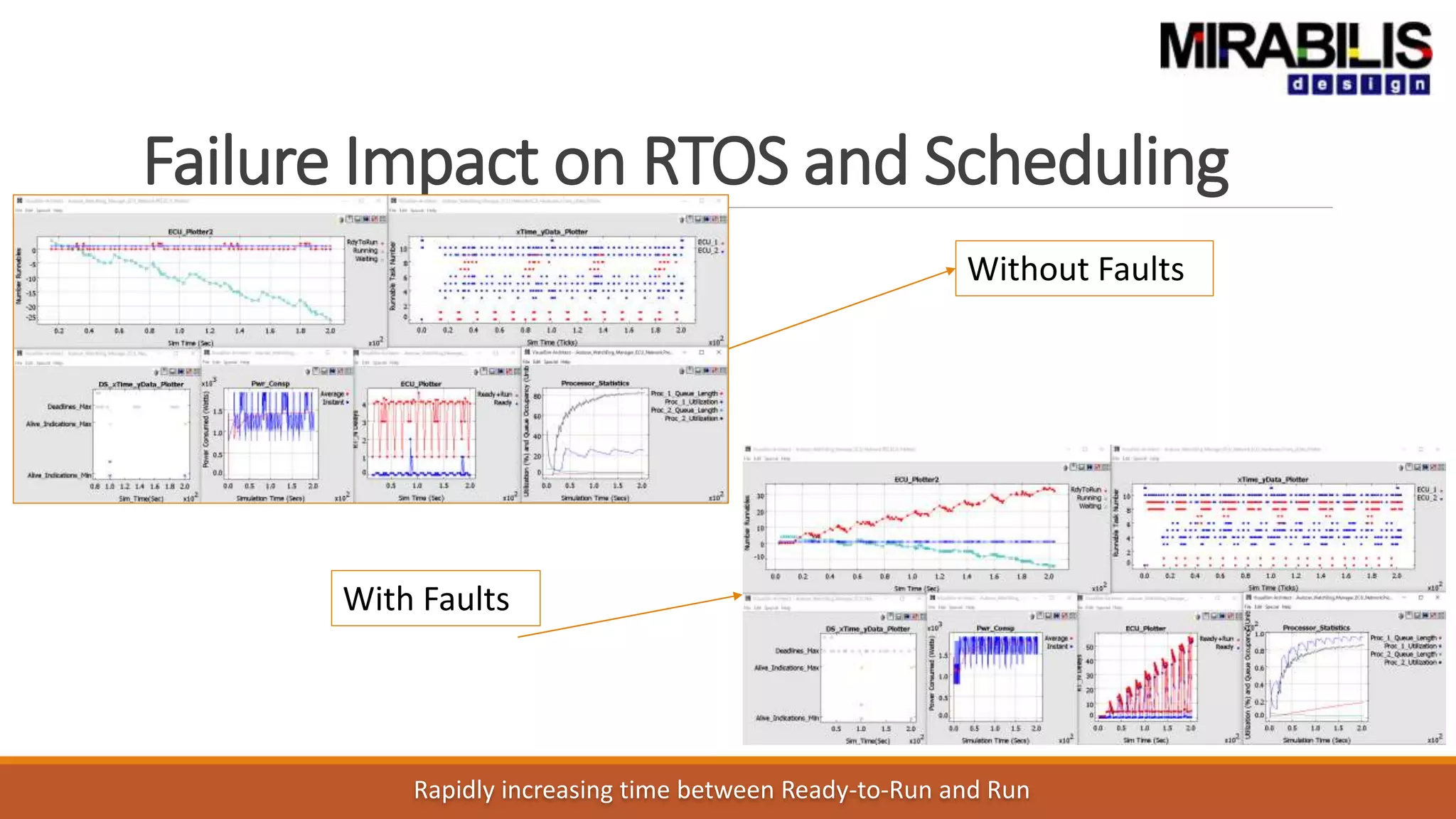
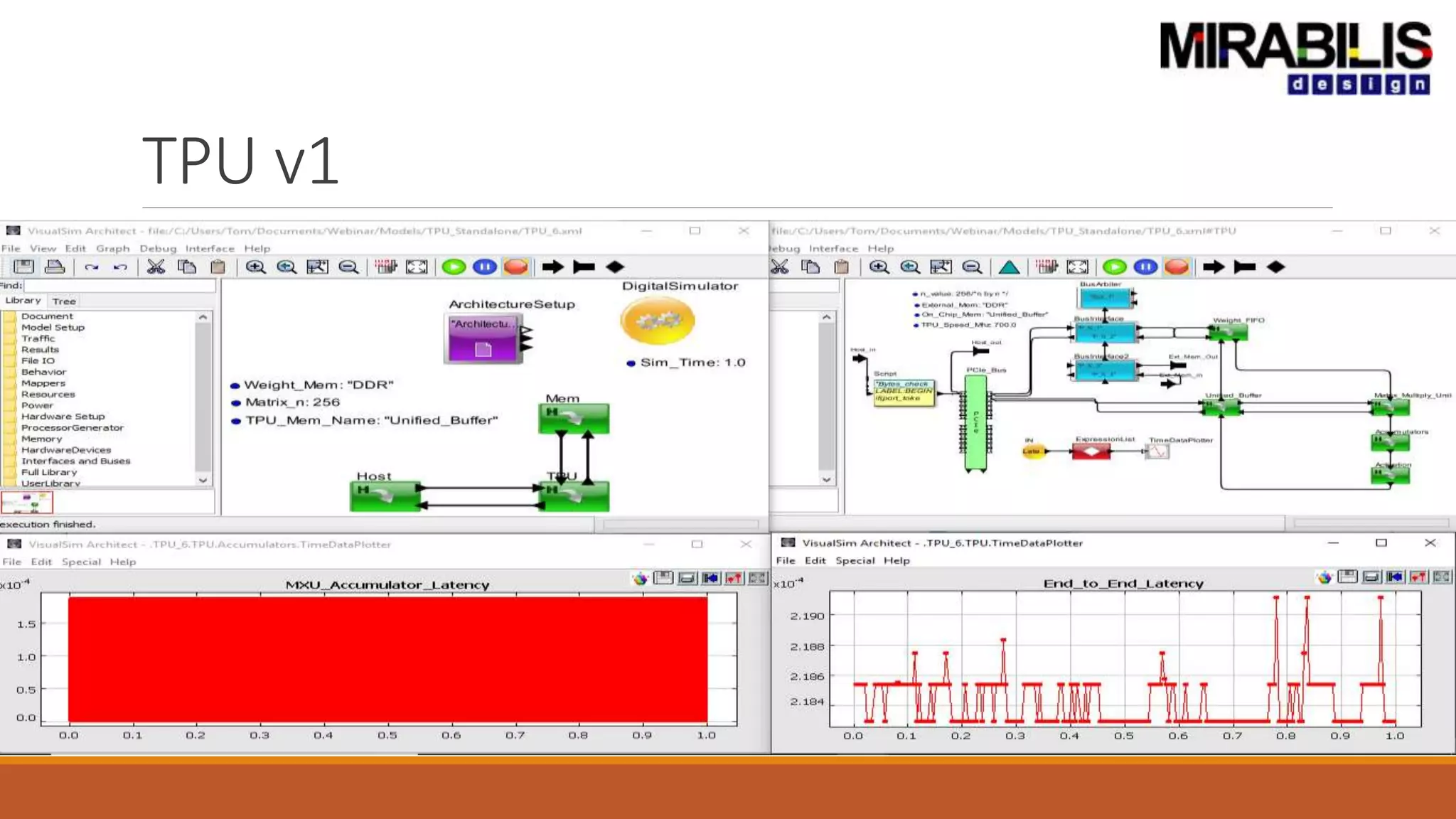
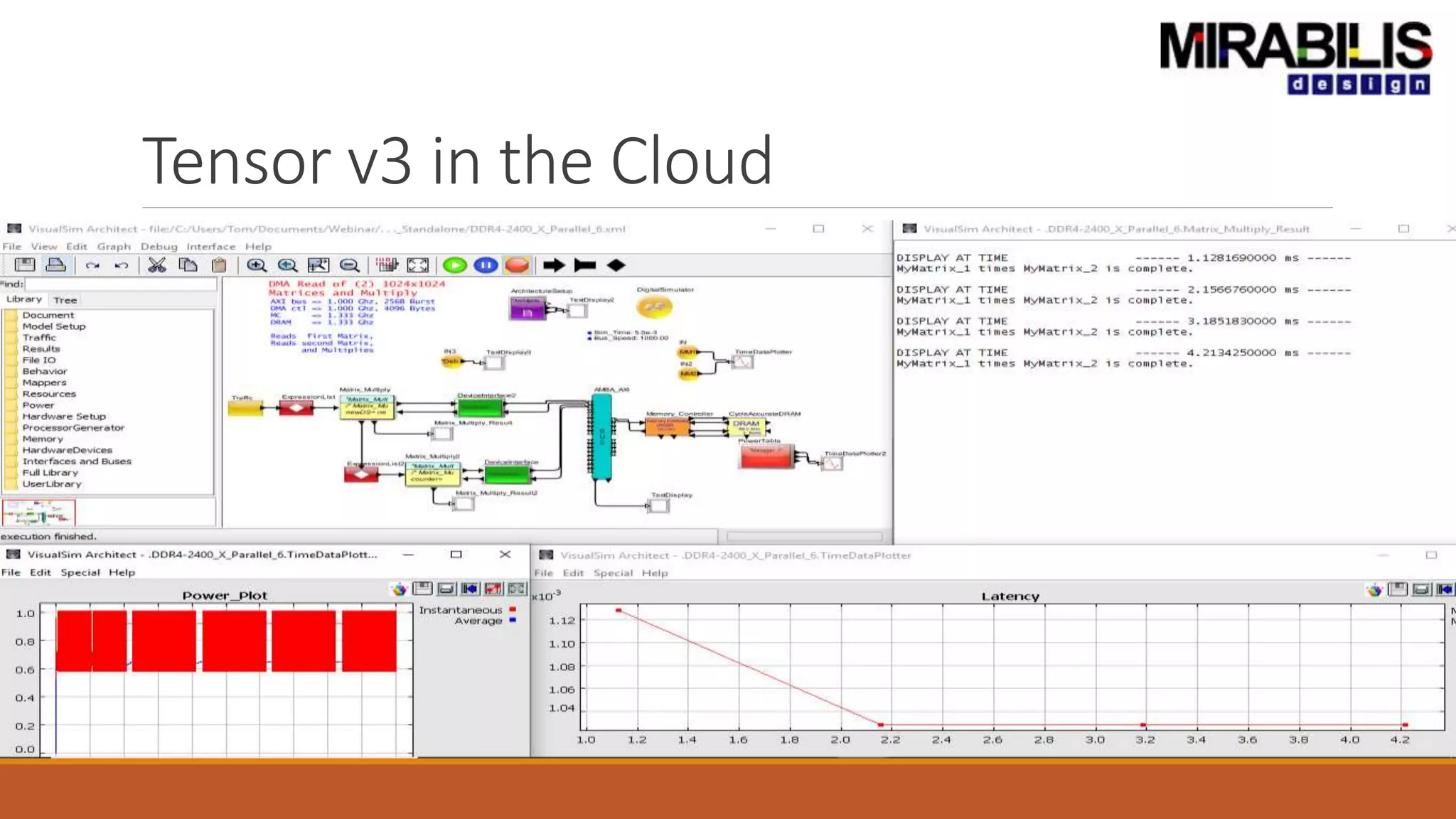
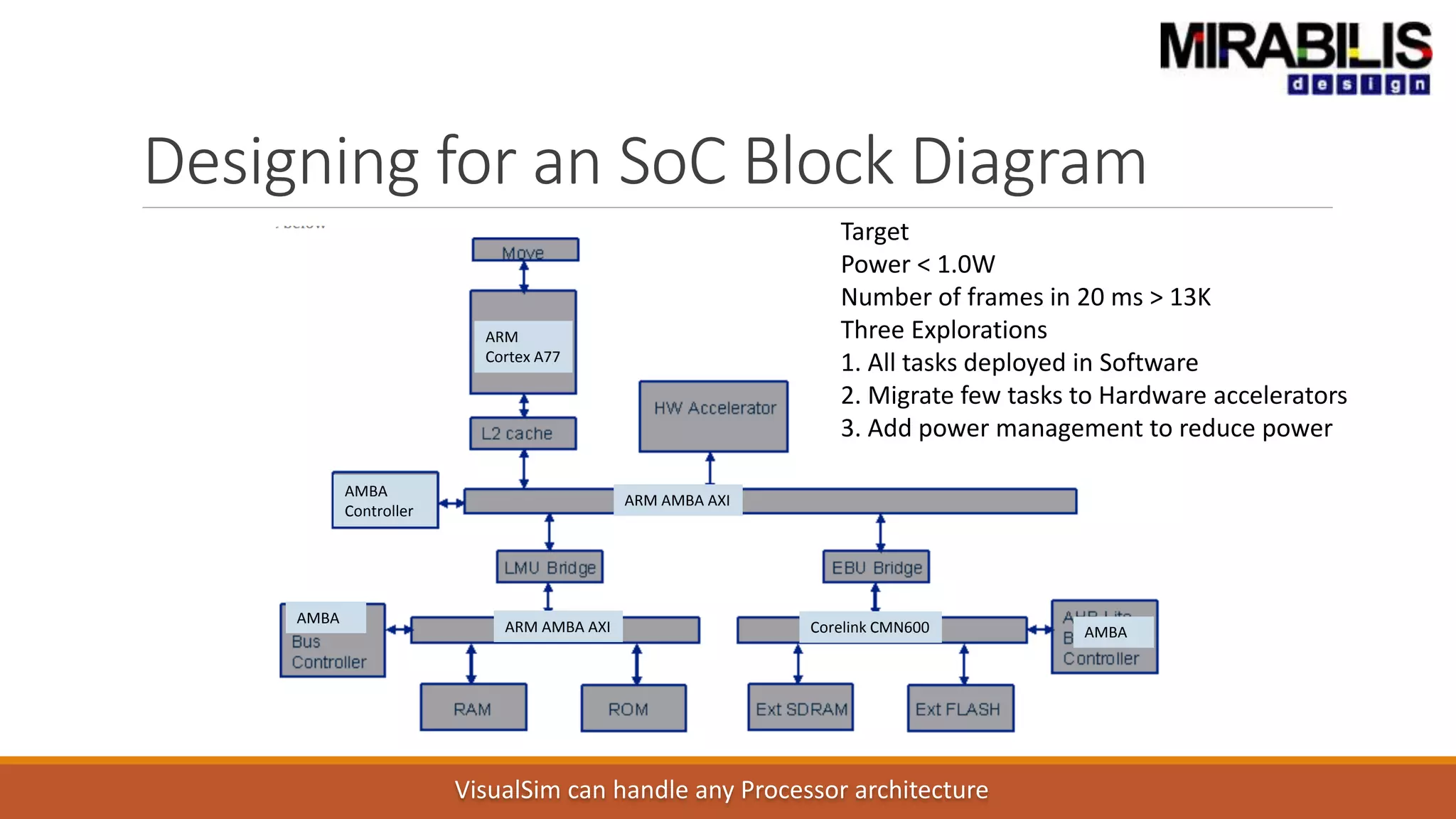
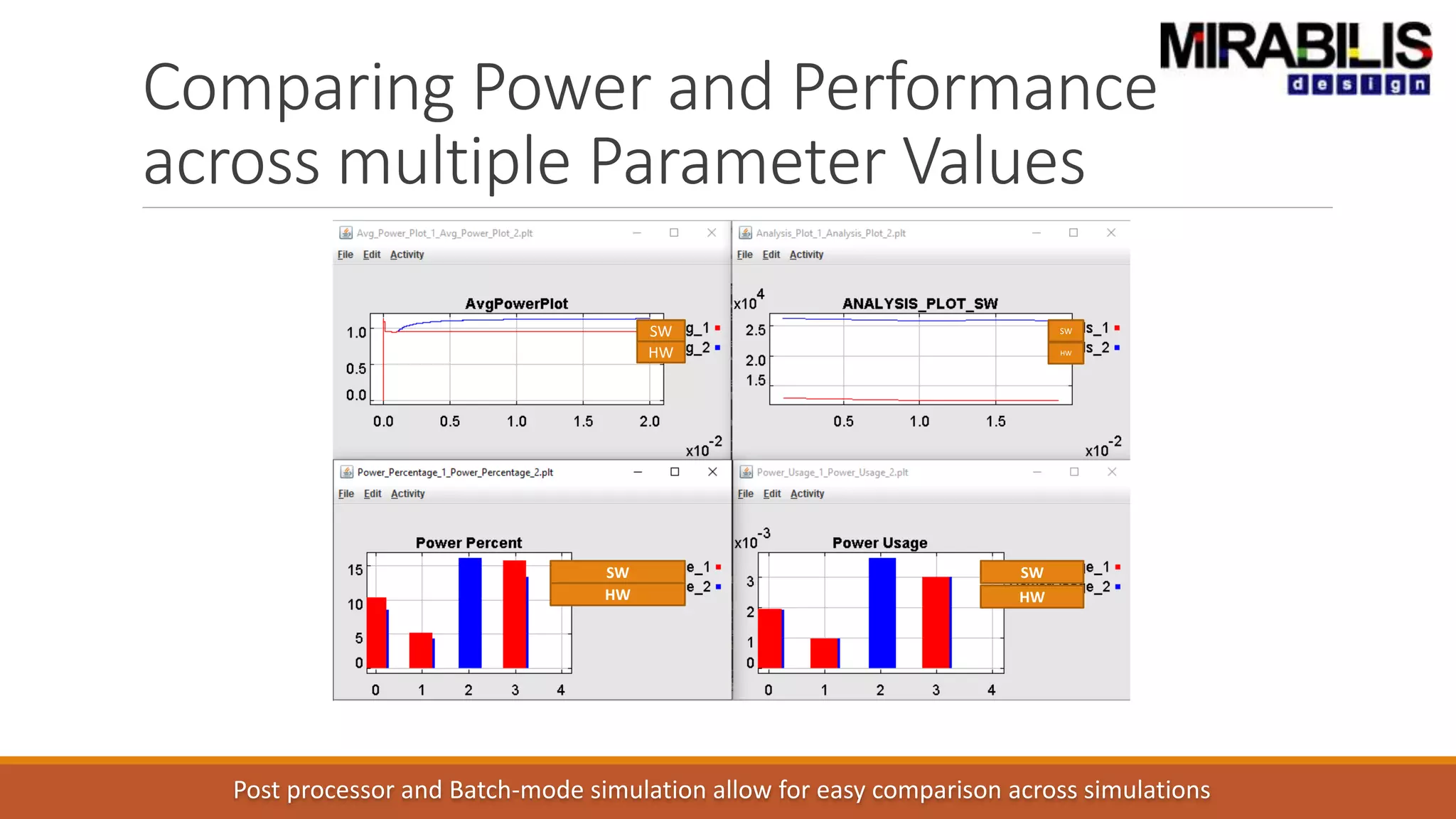
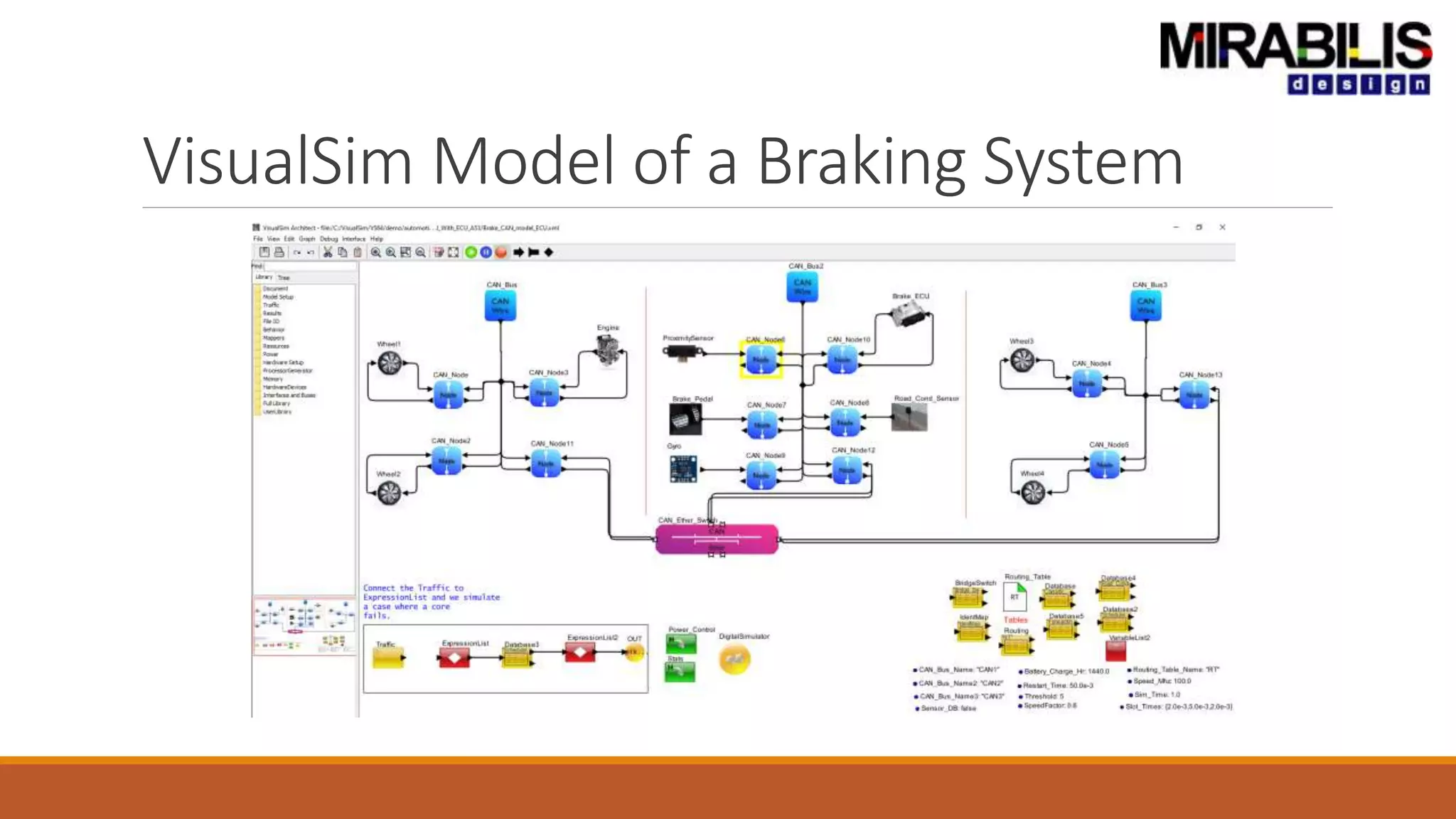
The document outlines a presentation by Deepak Shankar, the founder of Mirabilis Design Inc., focused on developing high-bandwidth and low-latency electronic systems for AI/ML applications. It covers traditional vs. proposed approaches to system modeling, emphasizing the use of virtual prototypes and early trade-off analysis to enhance design efficiency and accuracy. Additional topics include software performance profiling, hardware-software selection, and the capabilities of VisualSim modeling software in managing complex electronic system challenges.





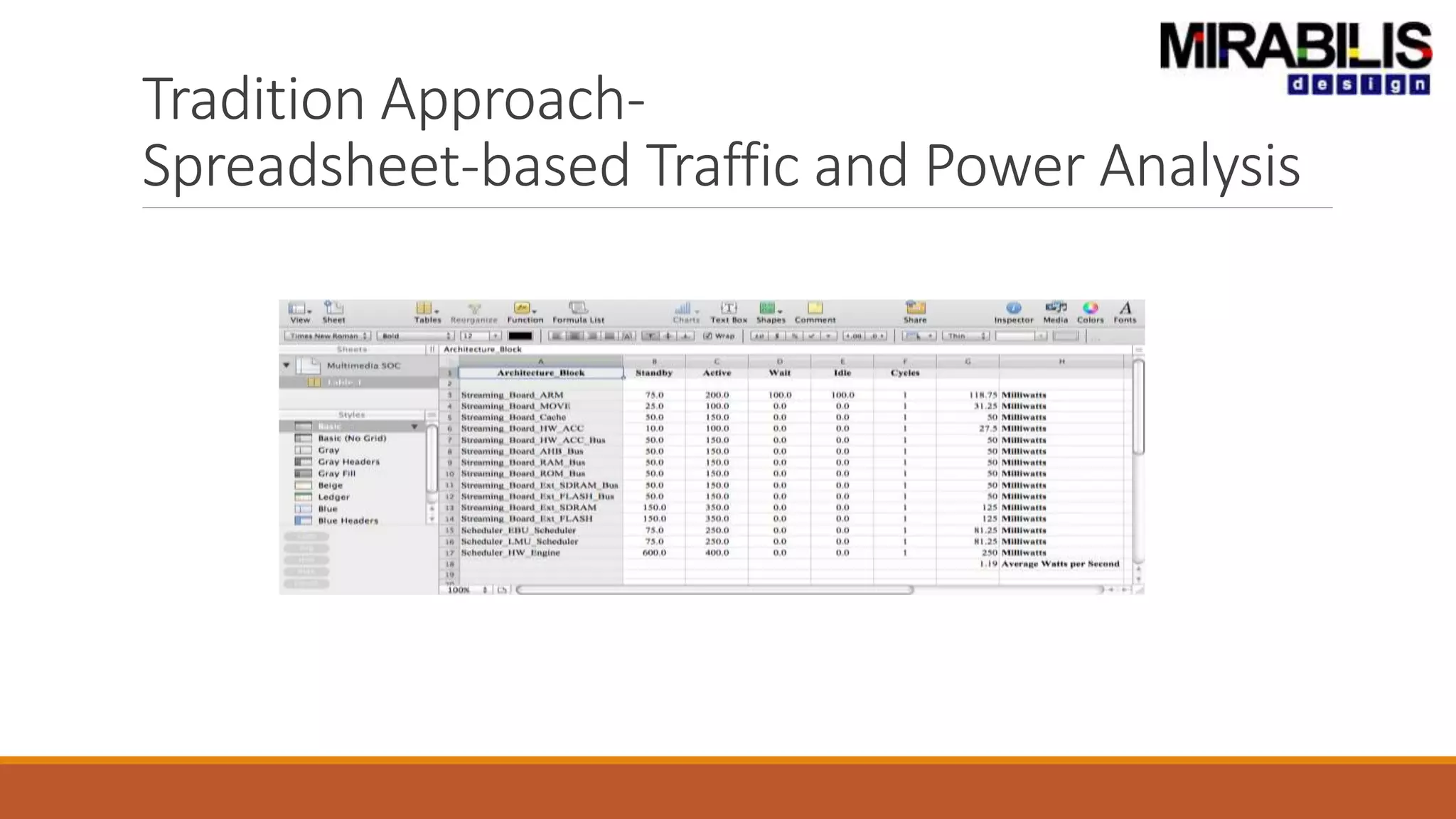
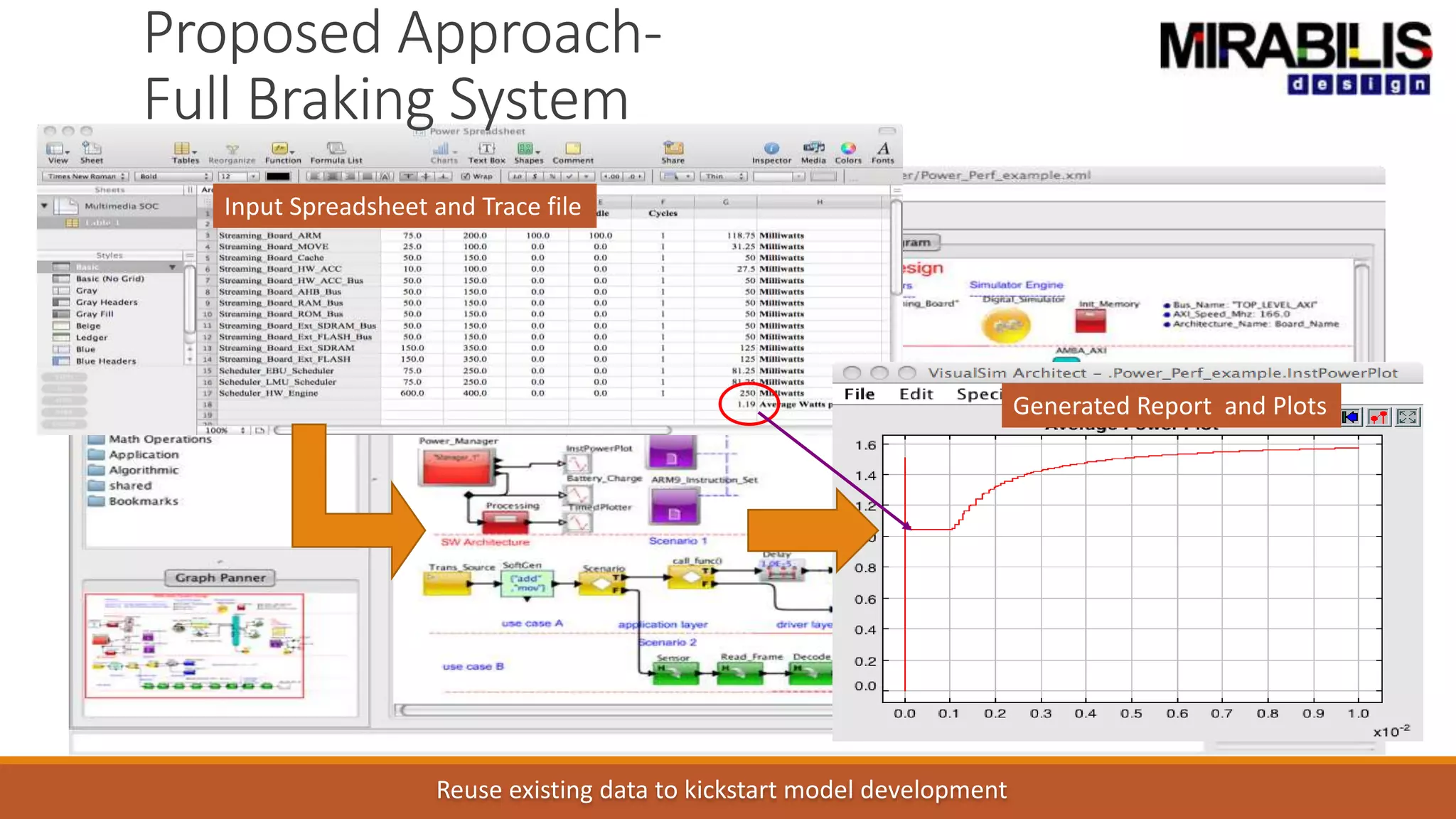




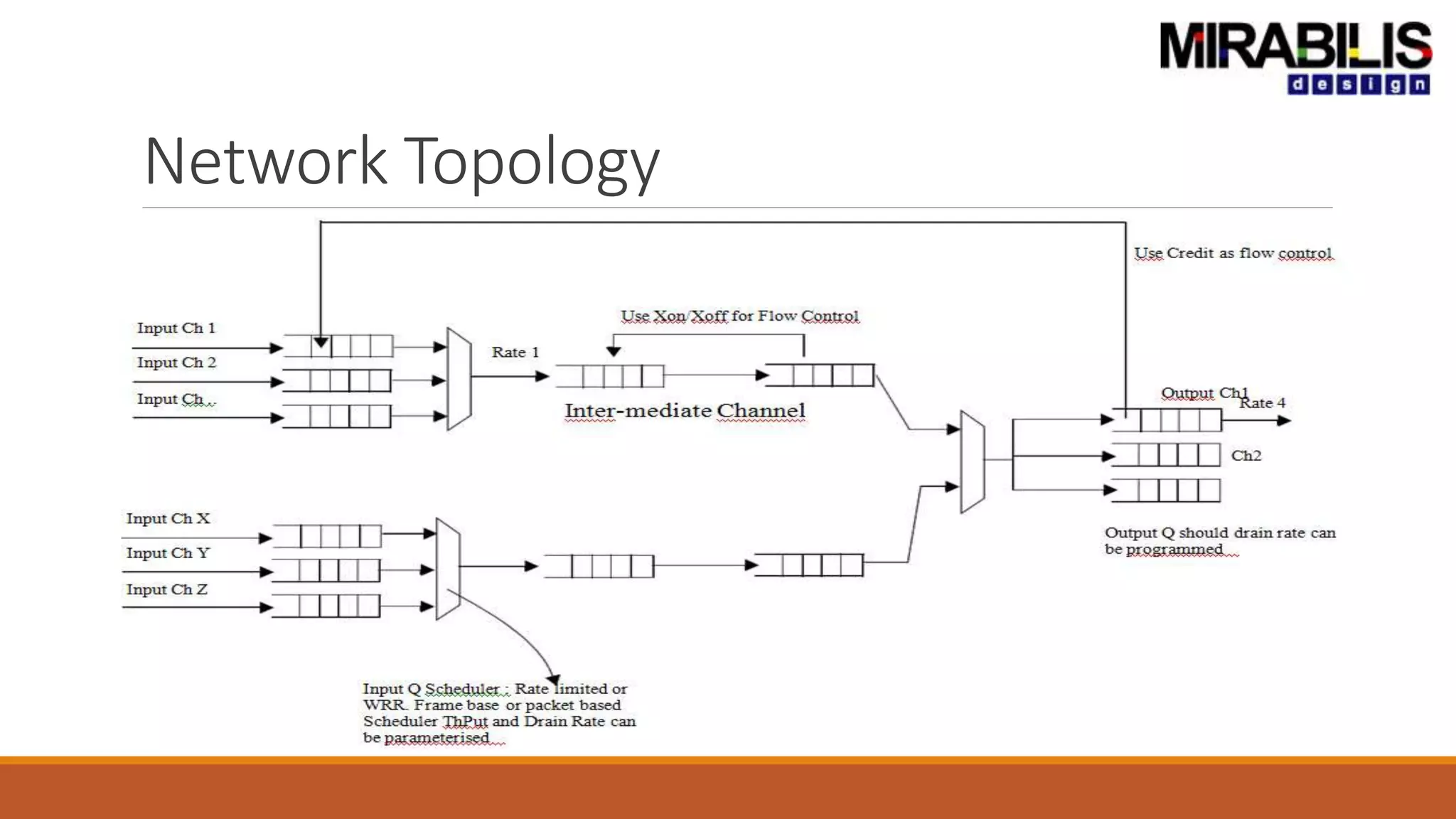
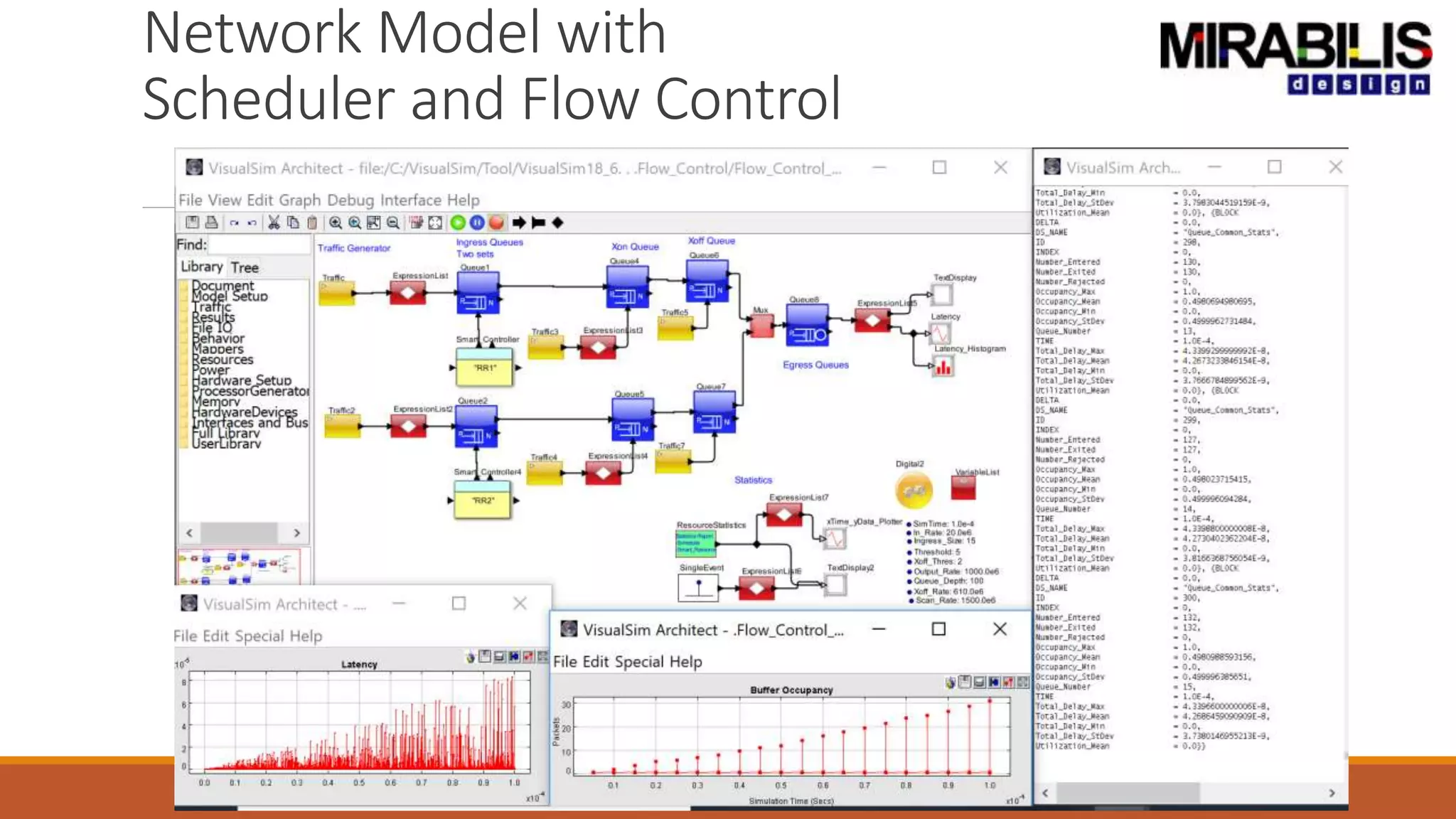



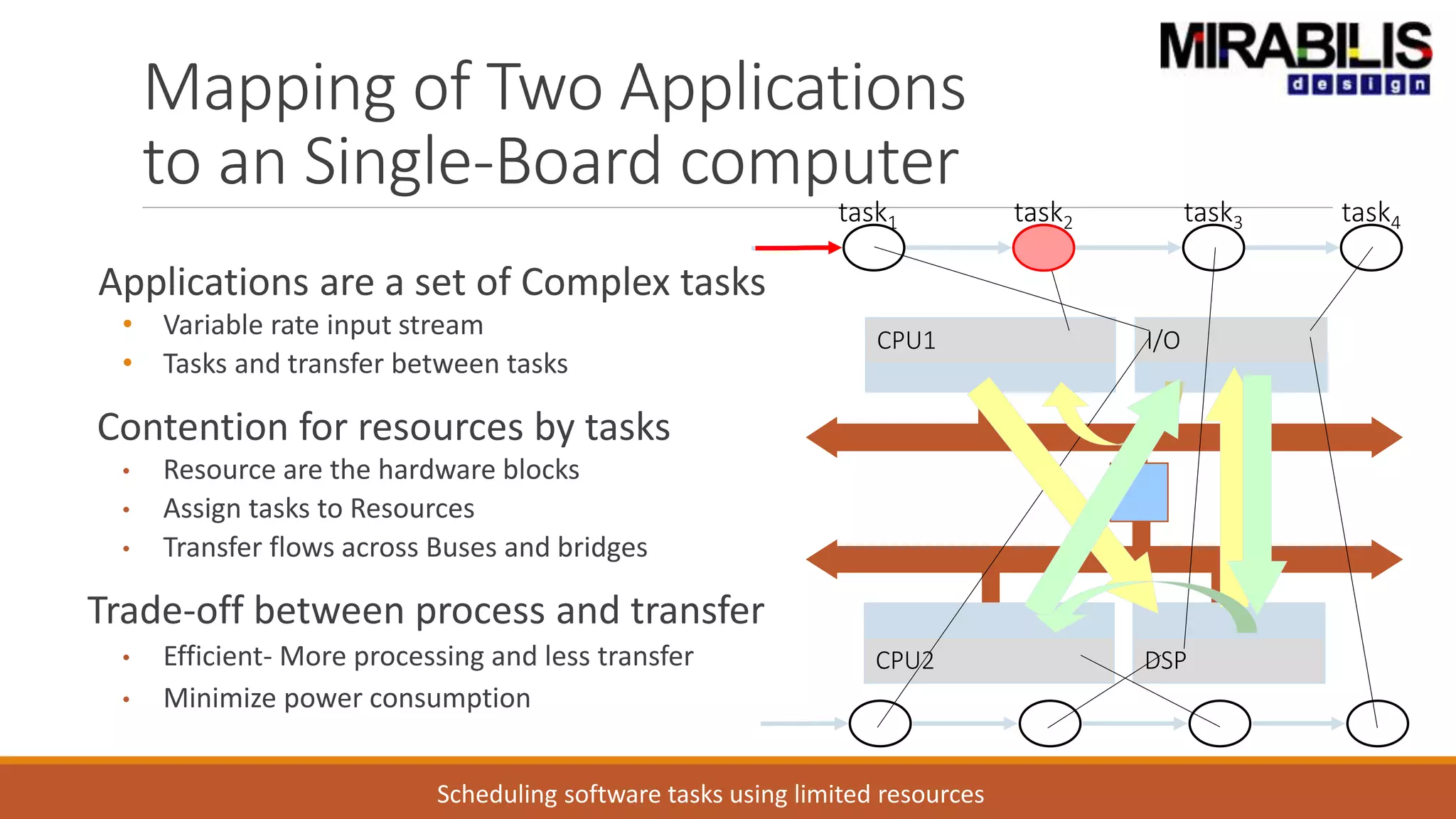
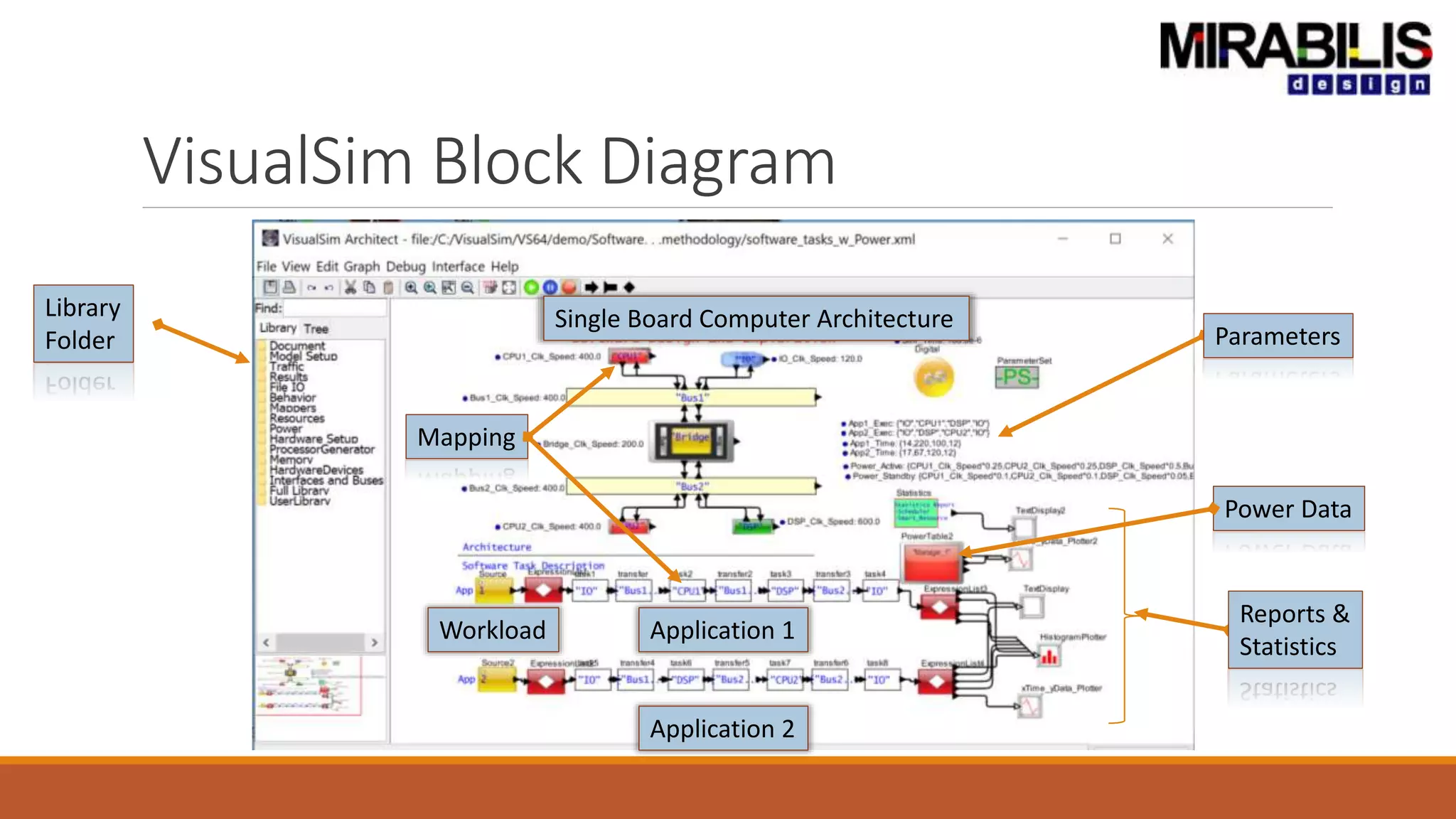
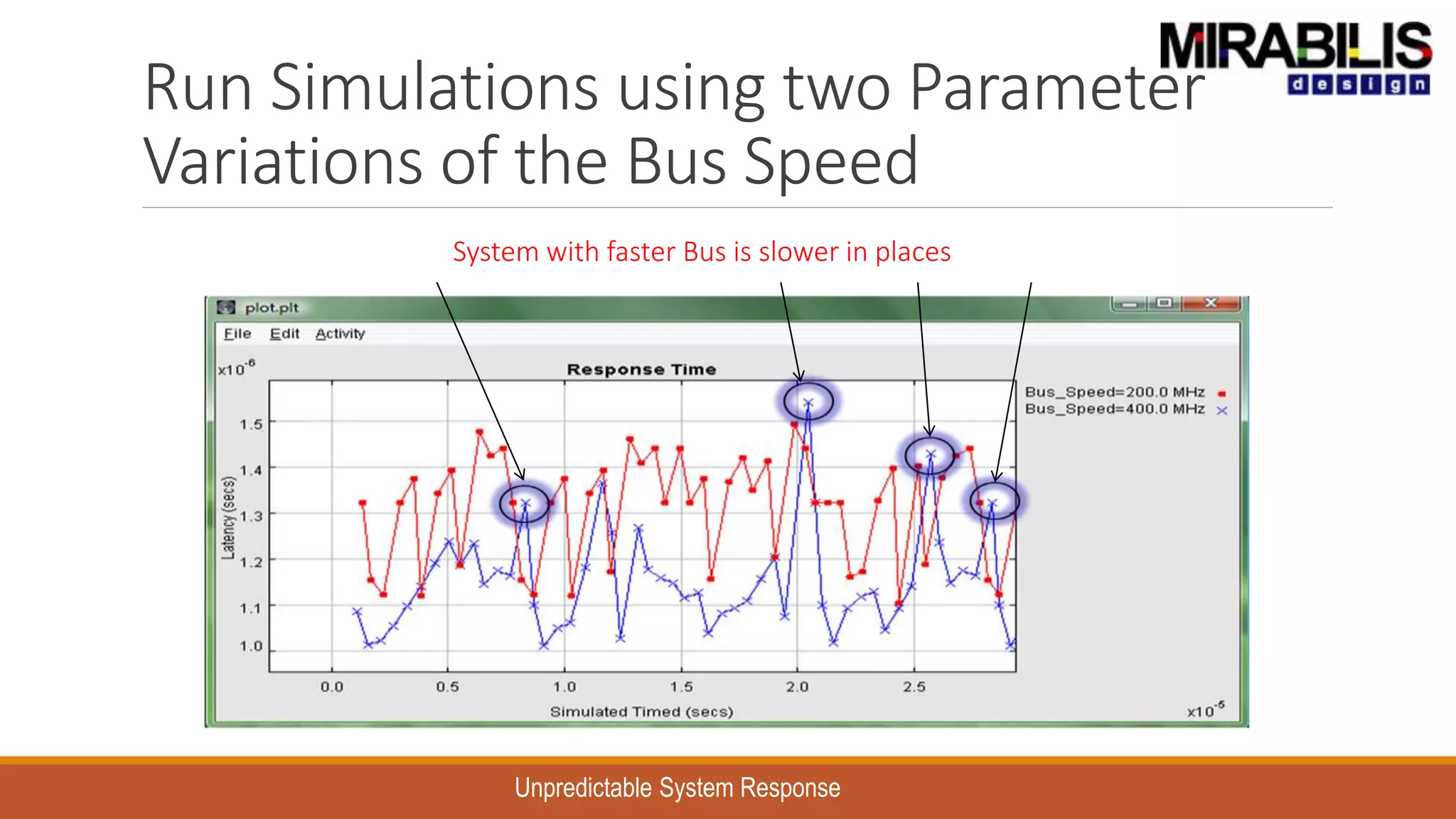















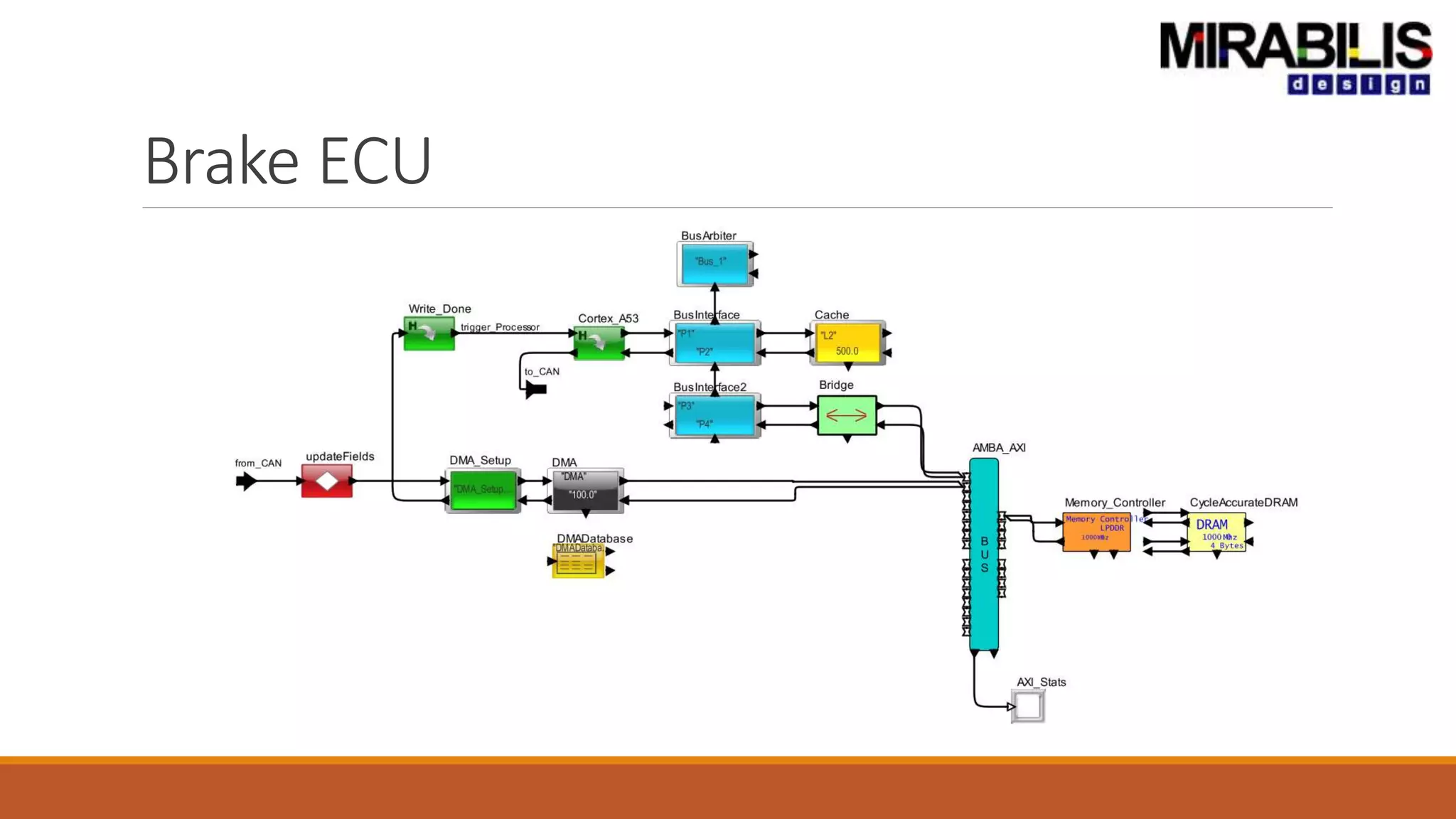
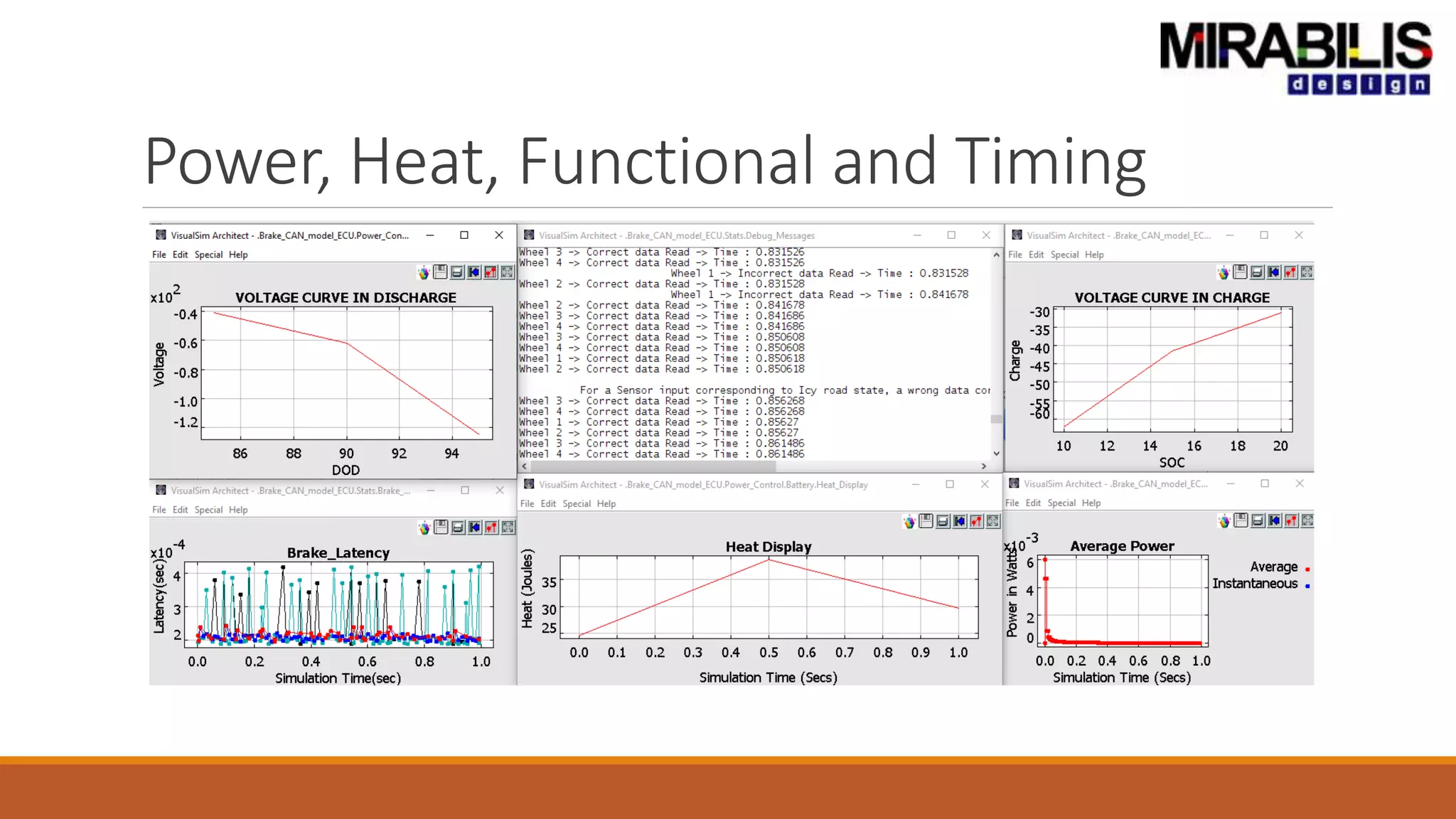

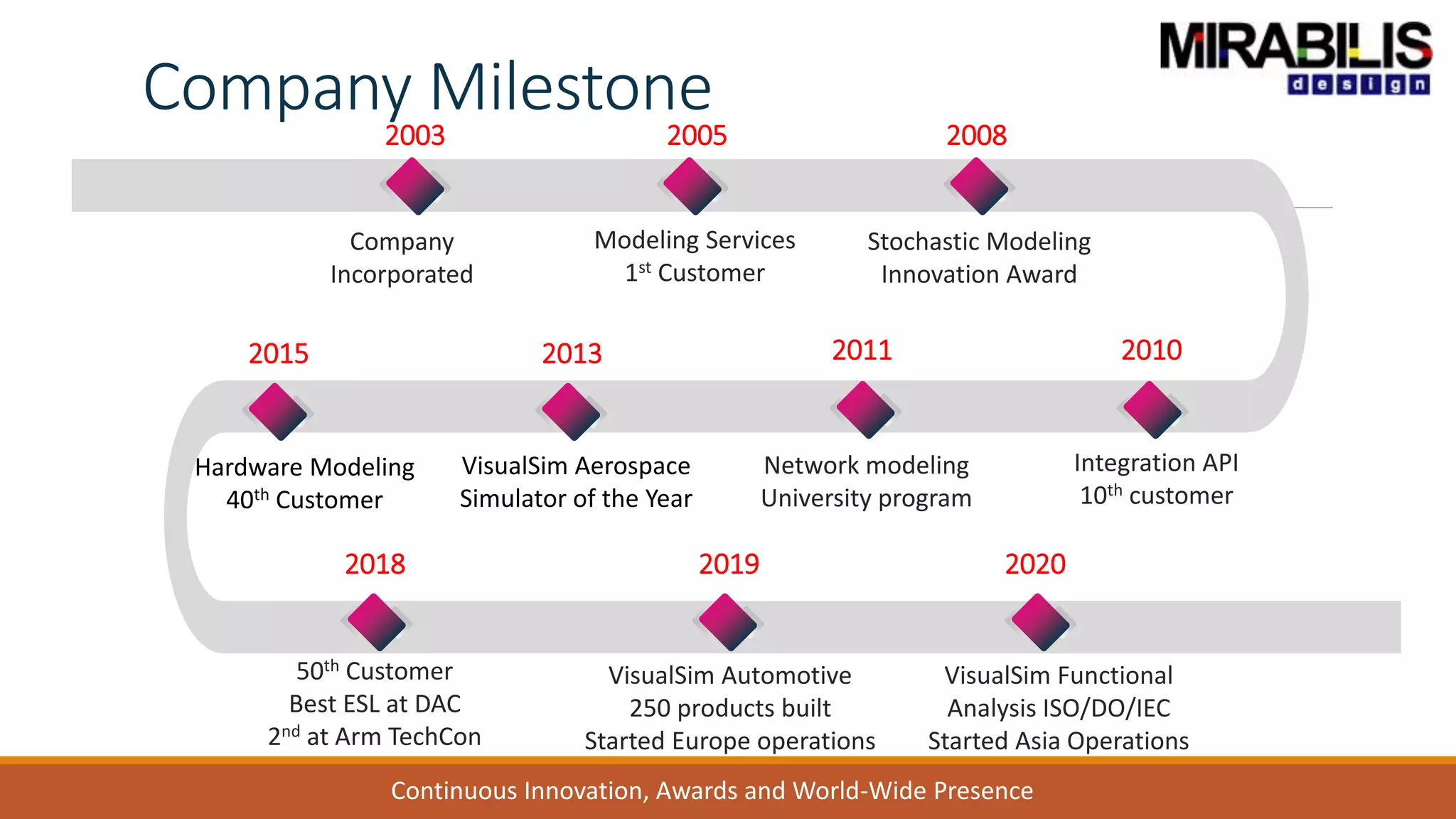
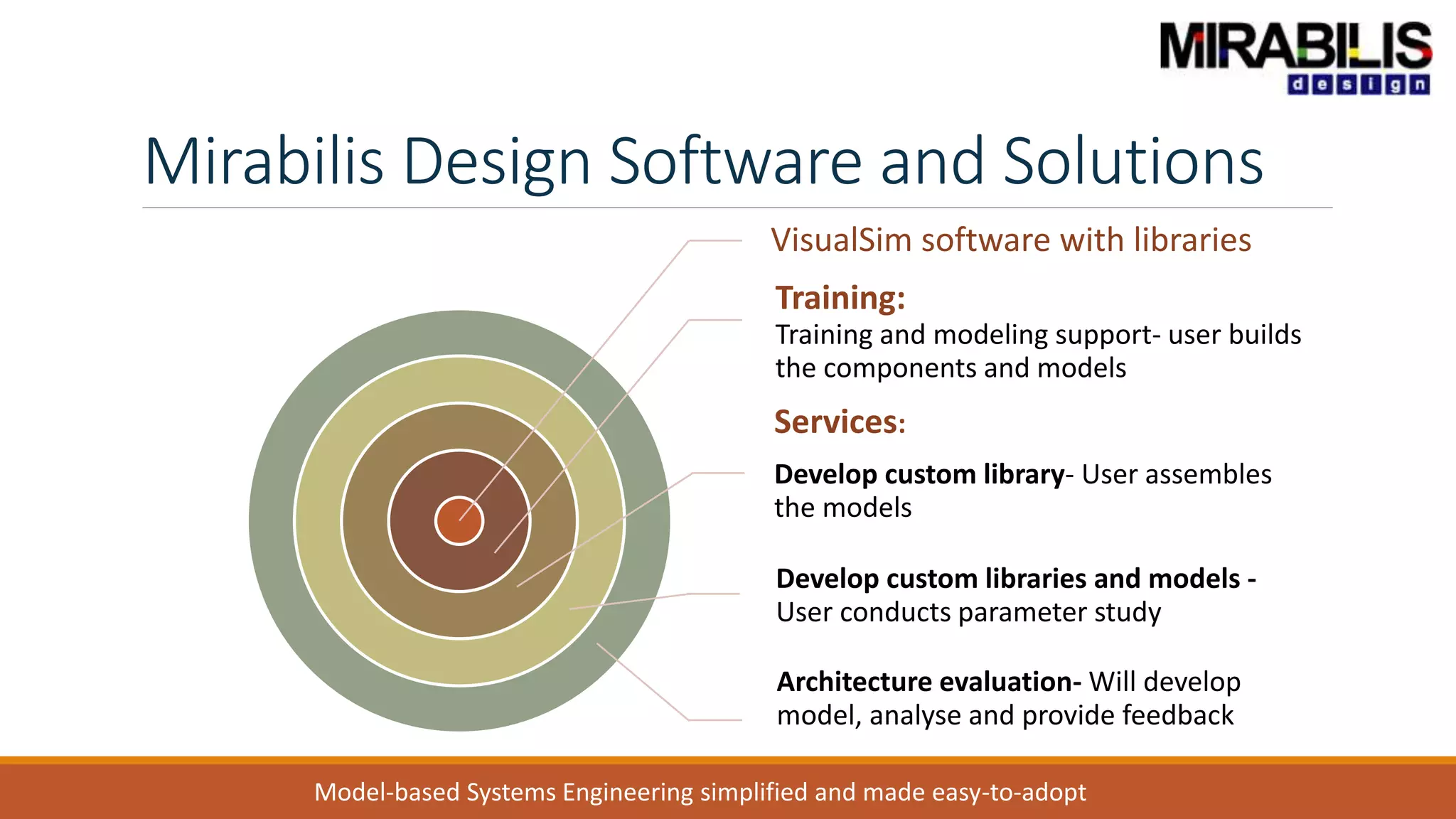








































































![ANPARA THERMAL POWER STATION[1] sangam.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/anparathermalpowerstation1sangam-251121115219-9261cde4-thumbnail.jpg?width=640&height=640&fit=bounds)





