Downloaded 18 times



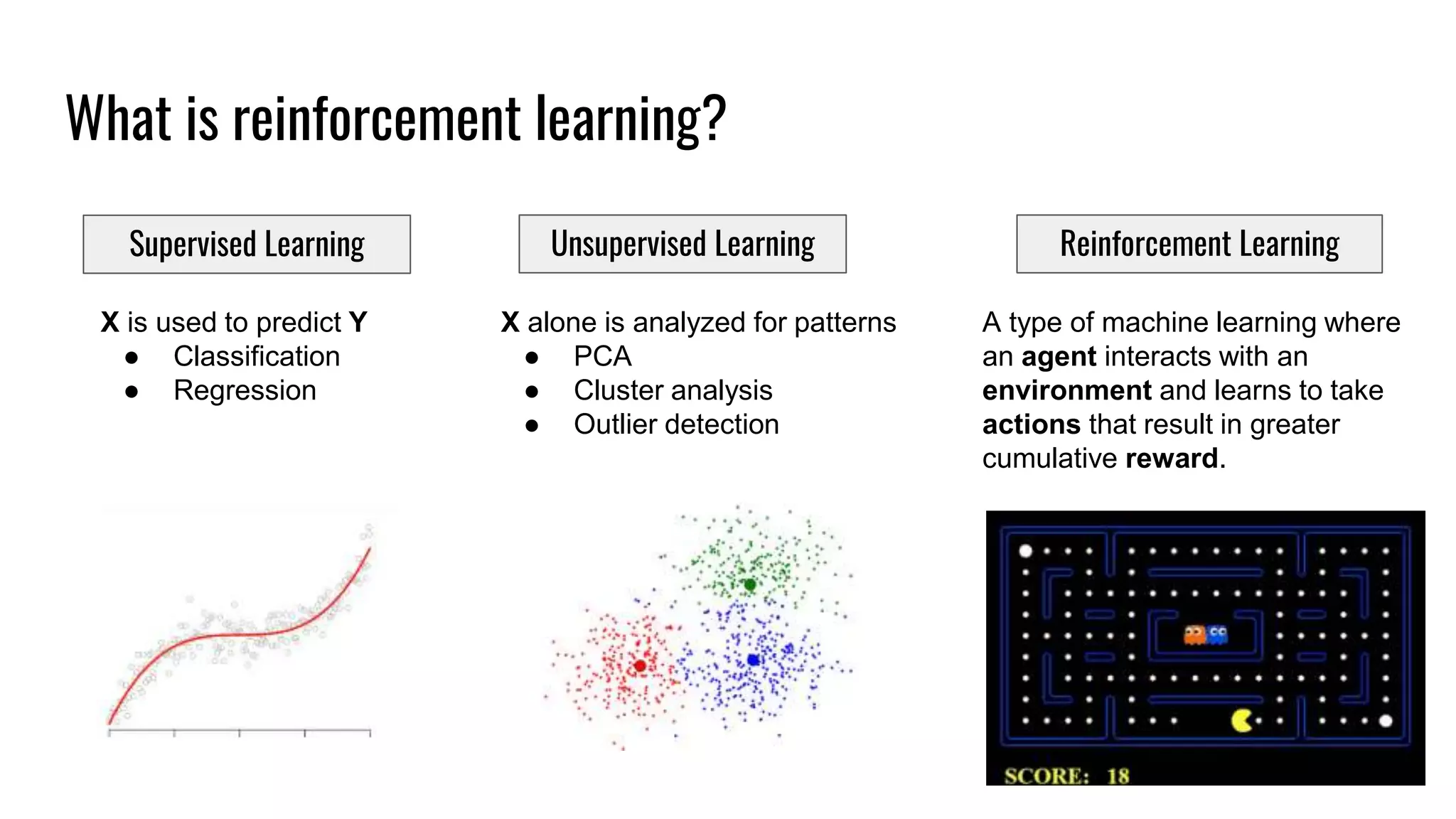
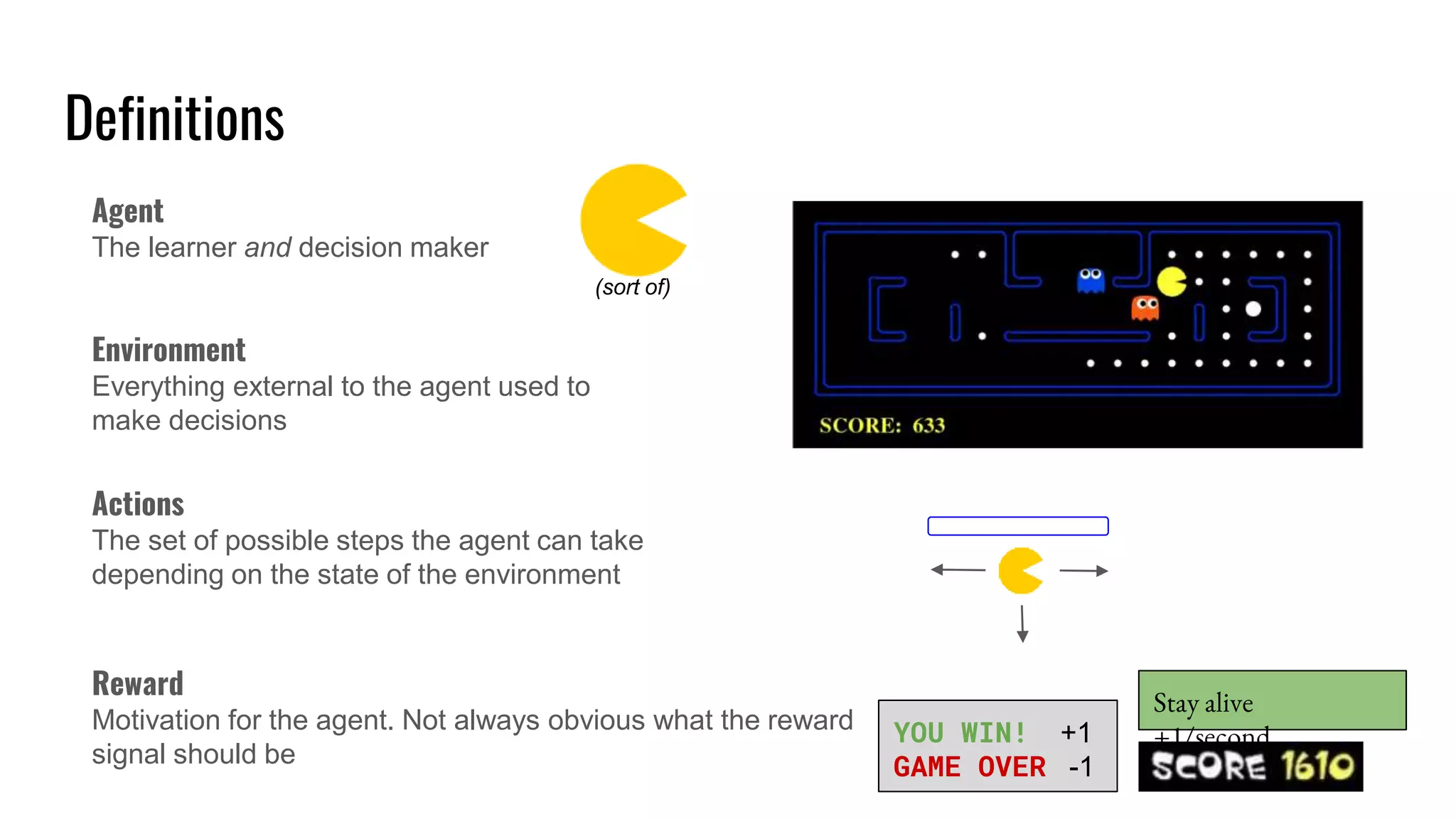

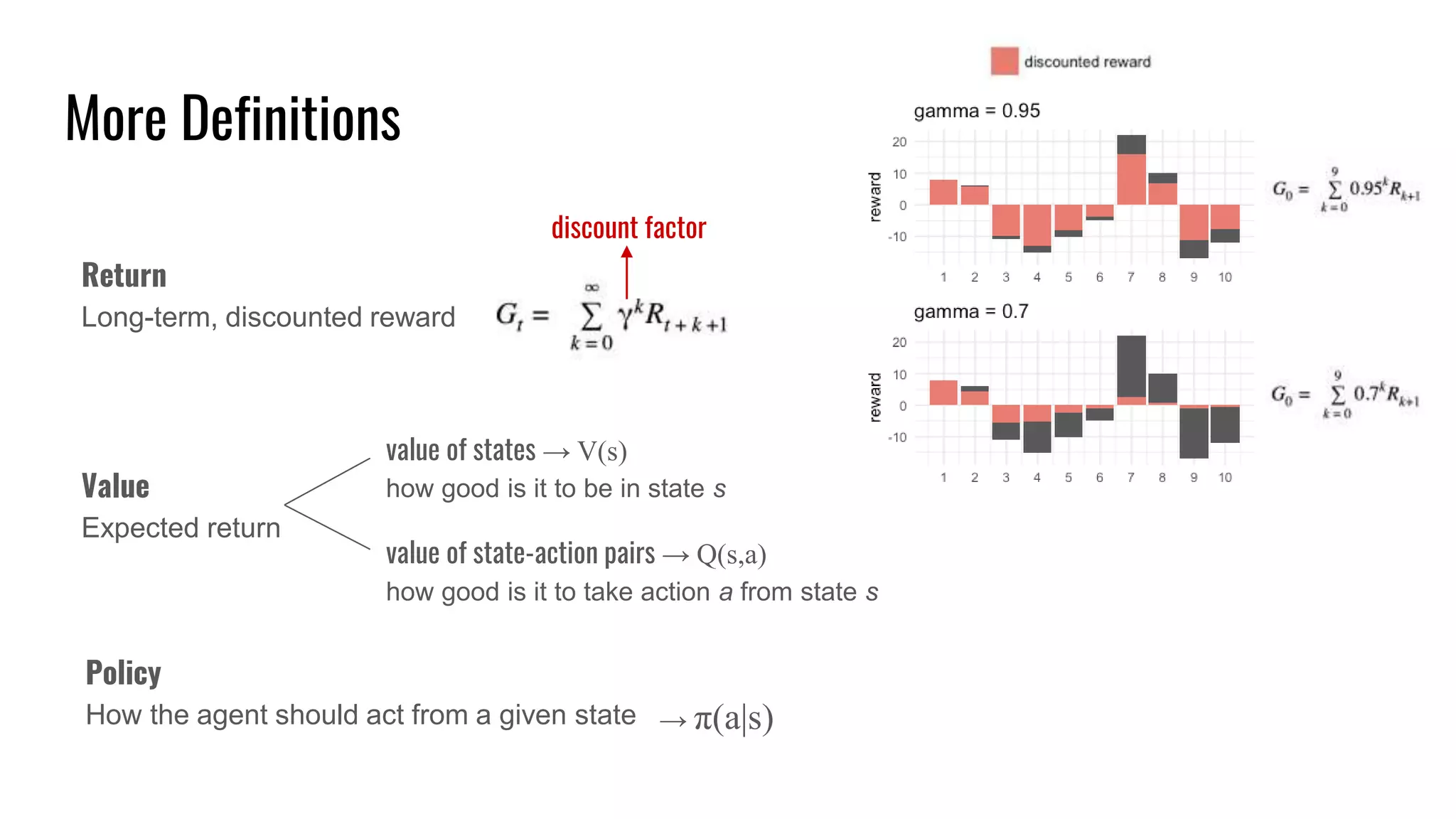
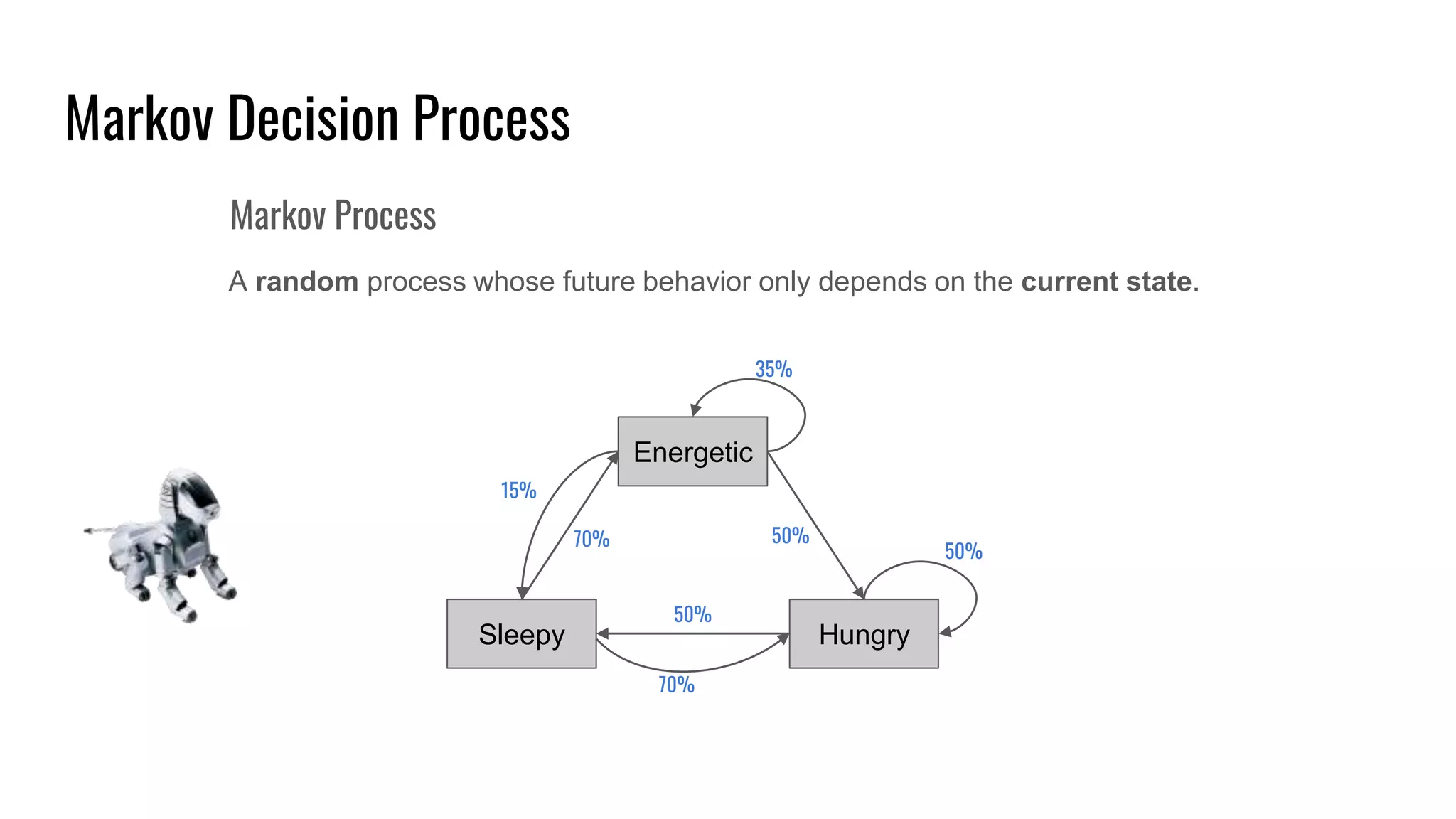
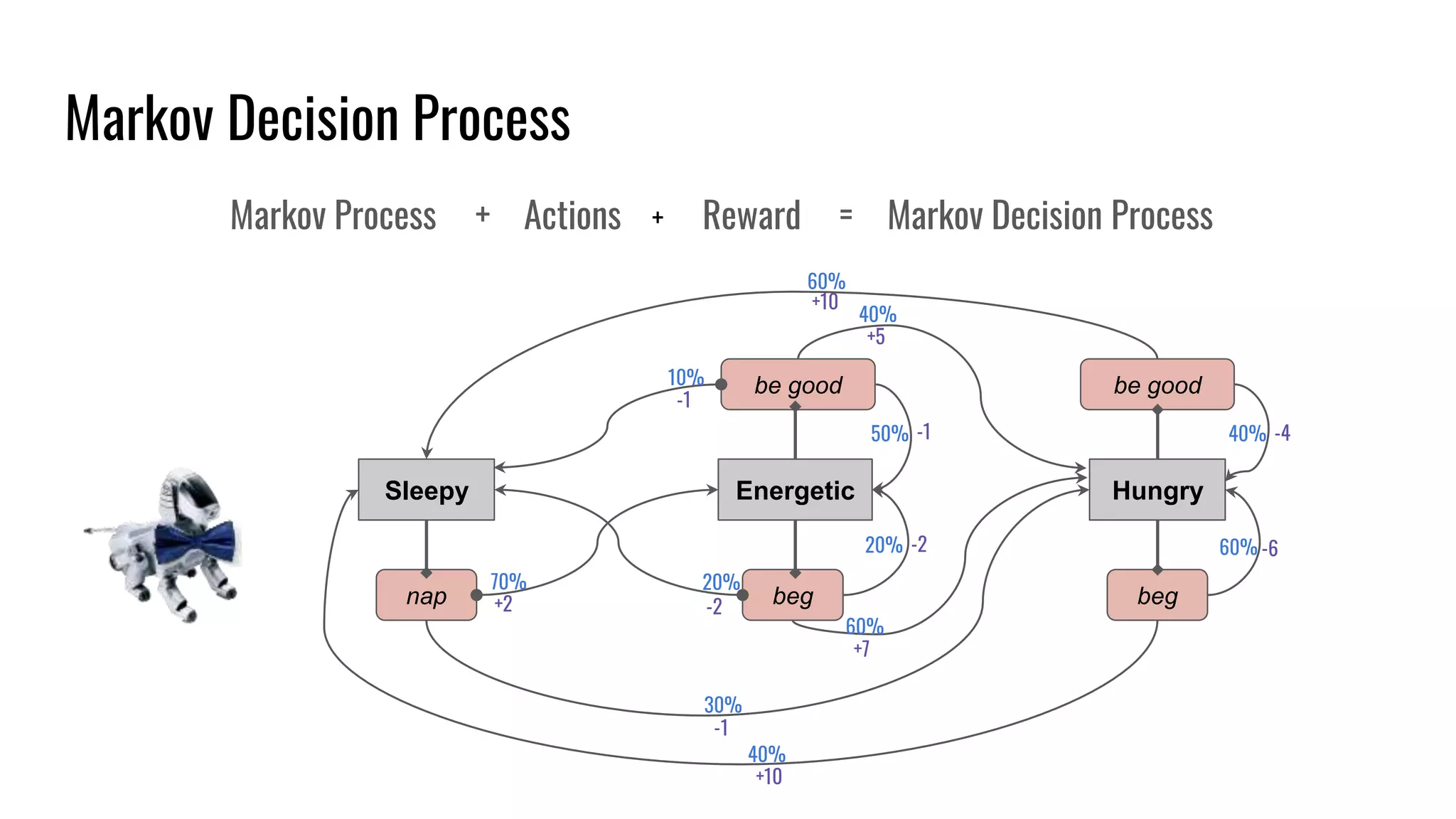

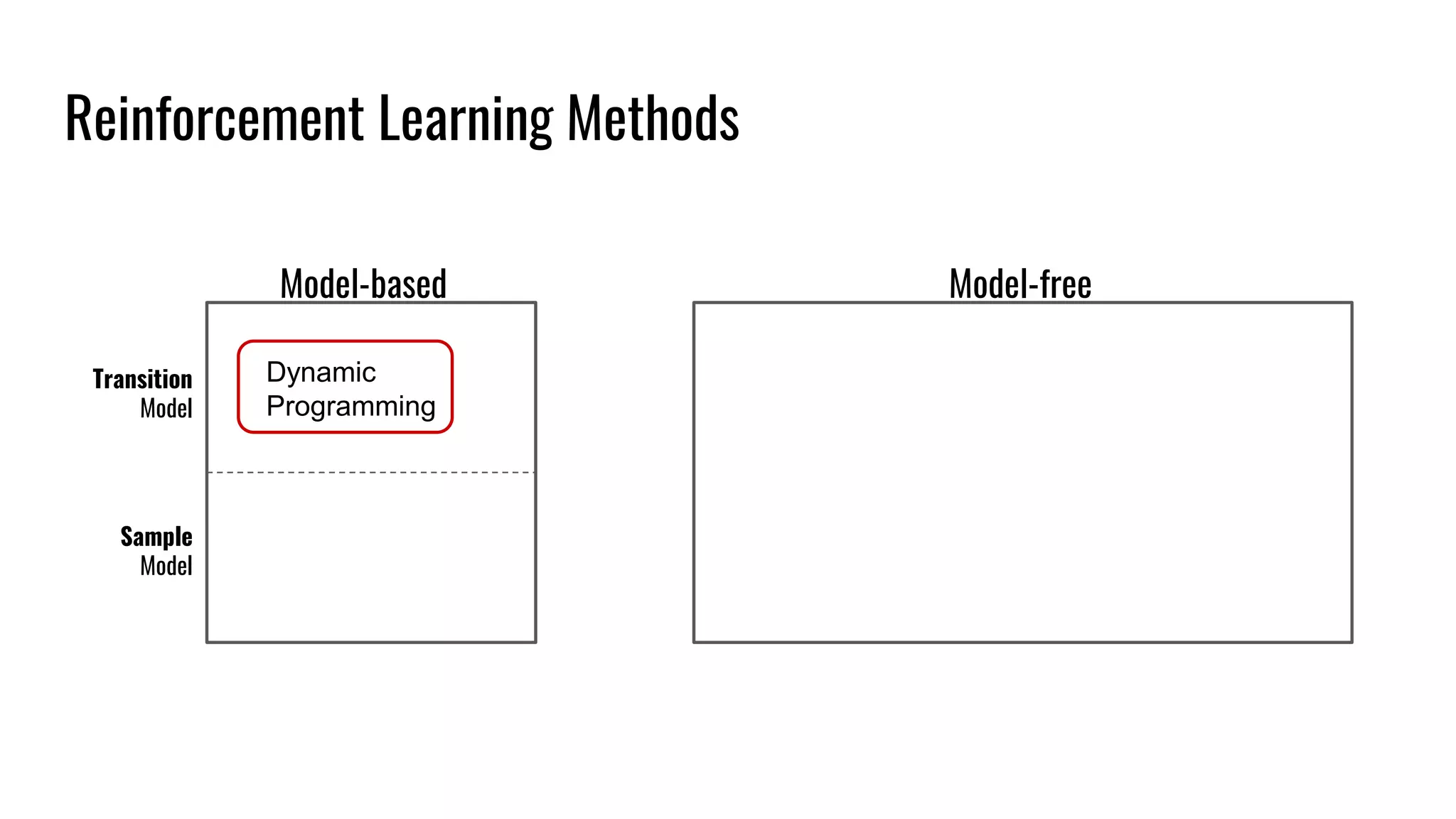

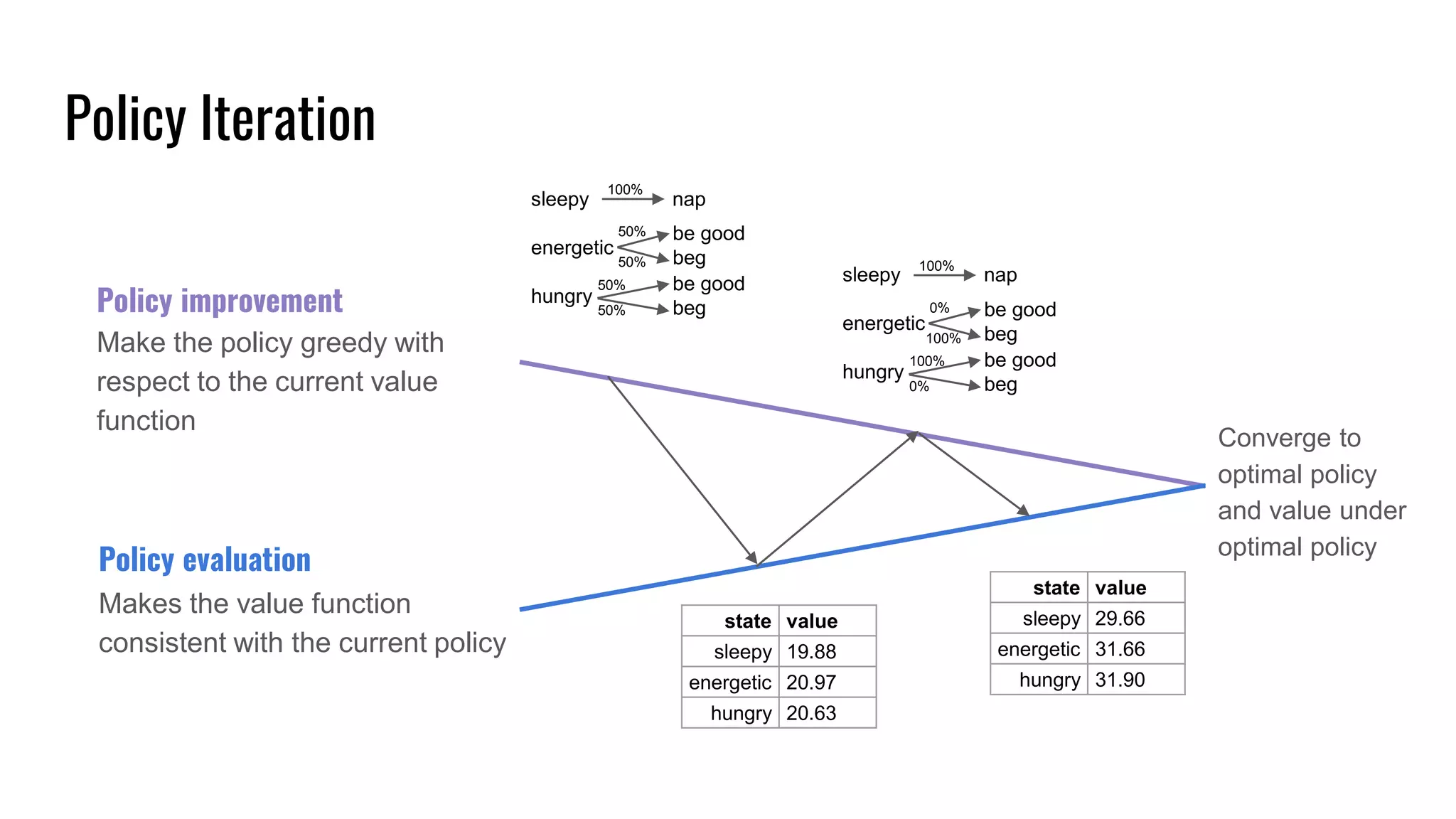
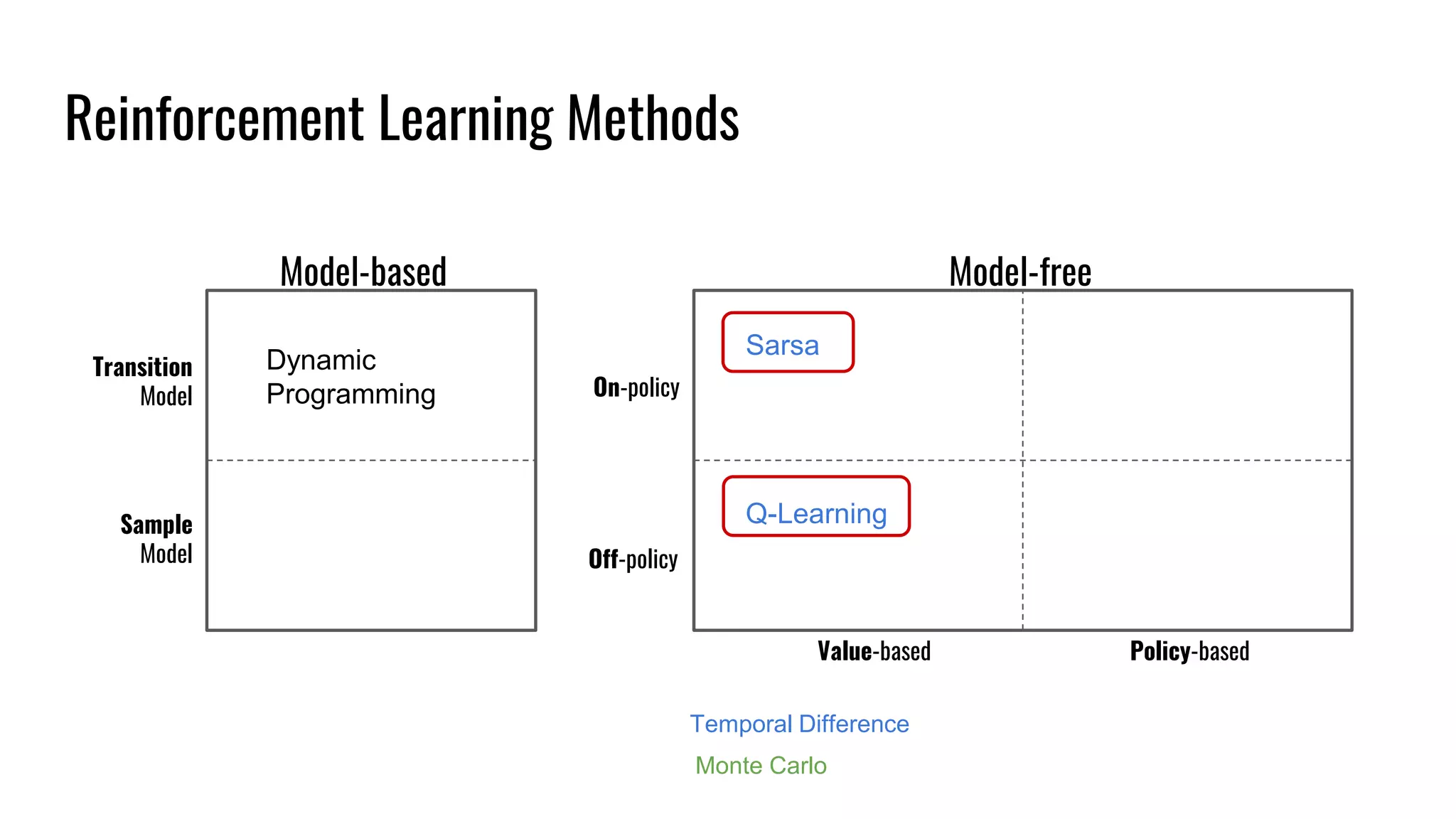
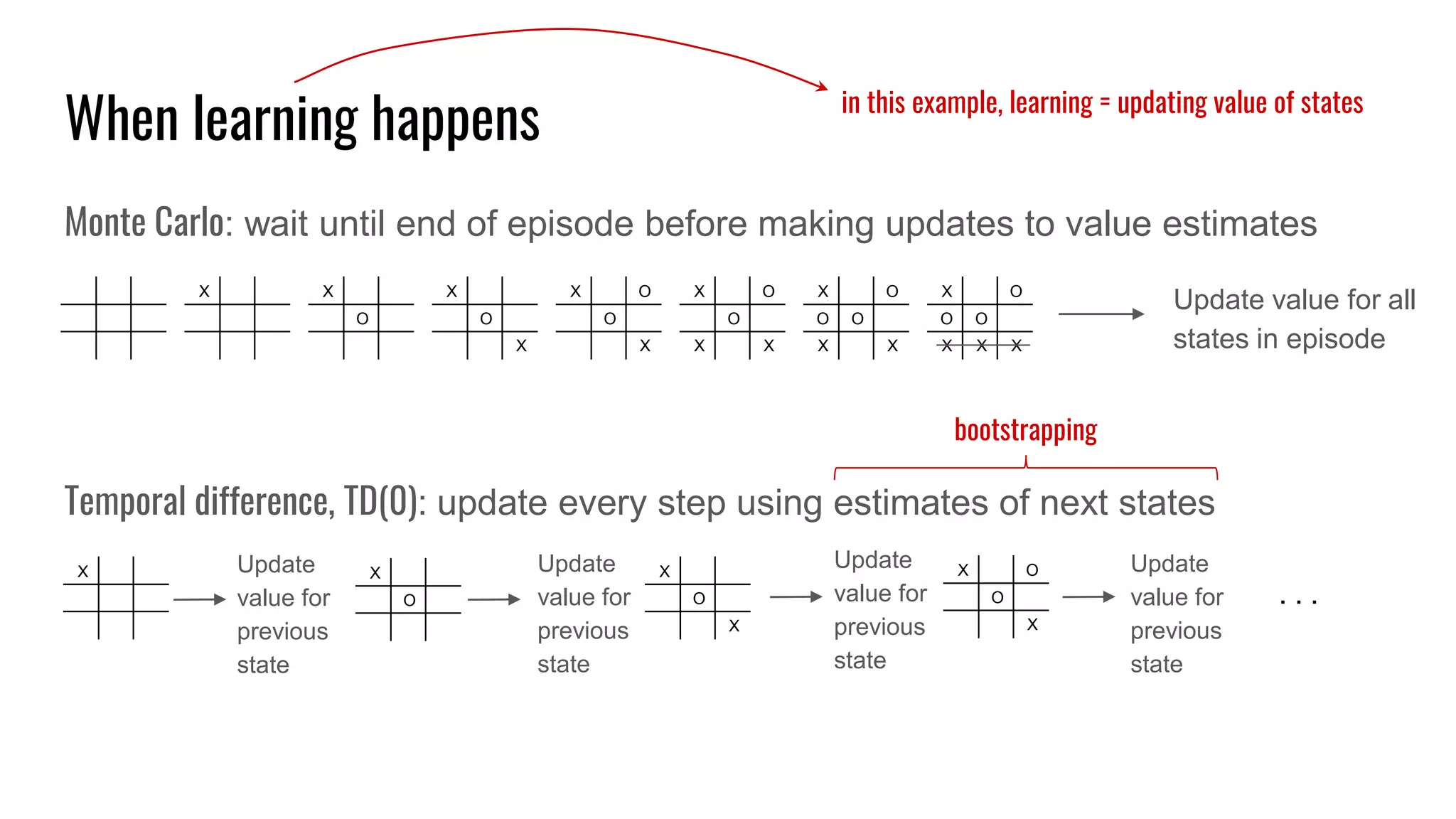




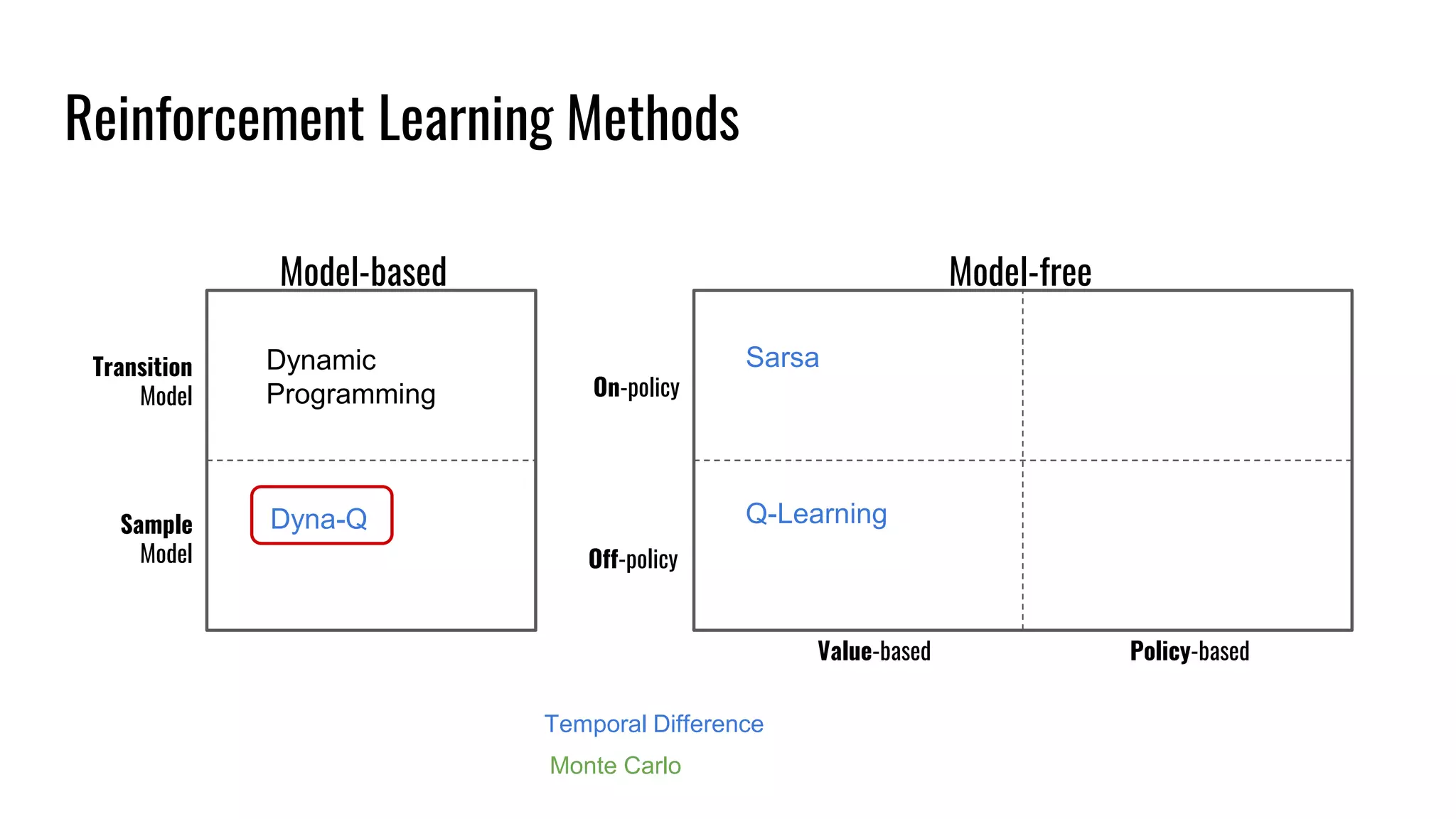

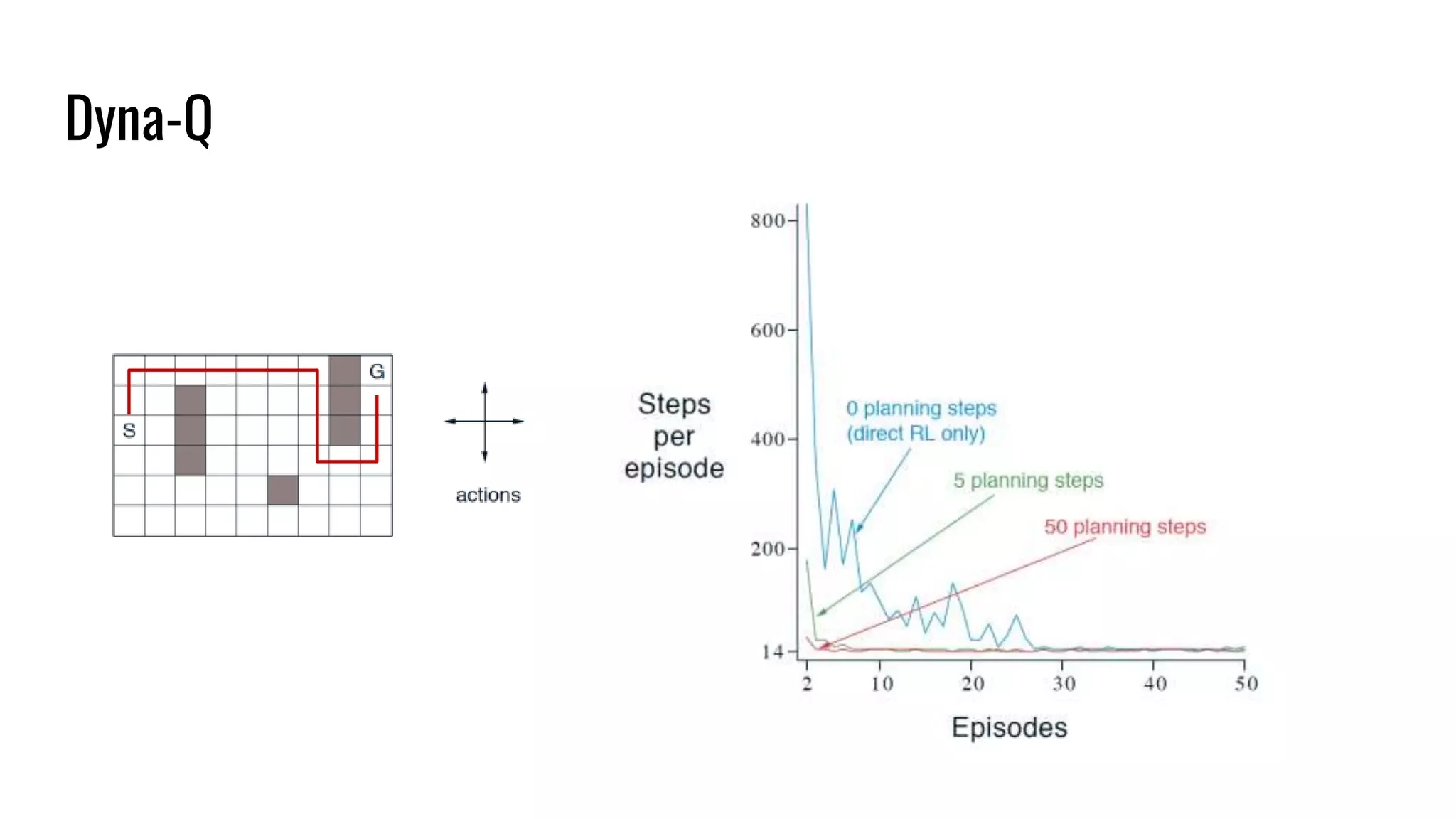
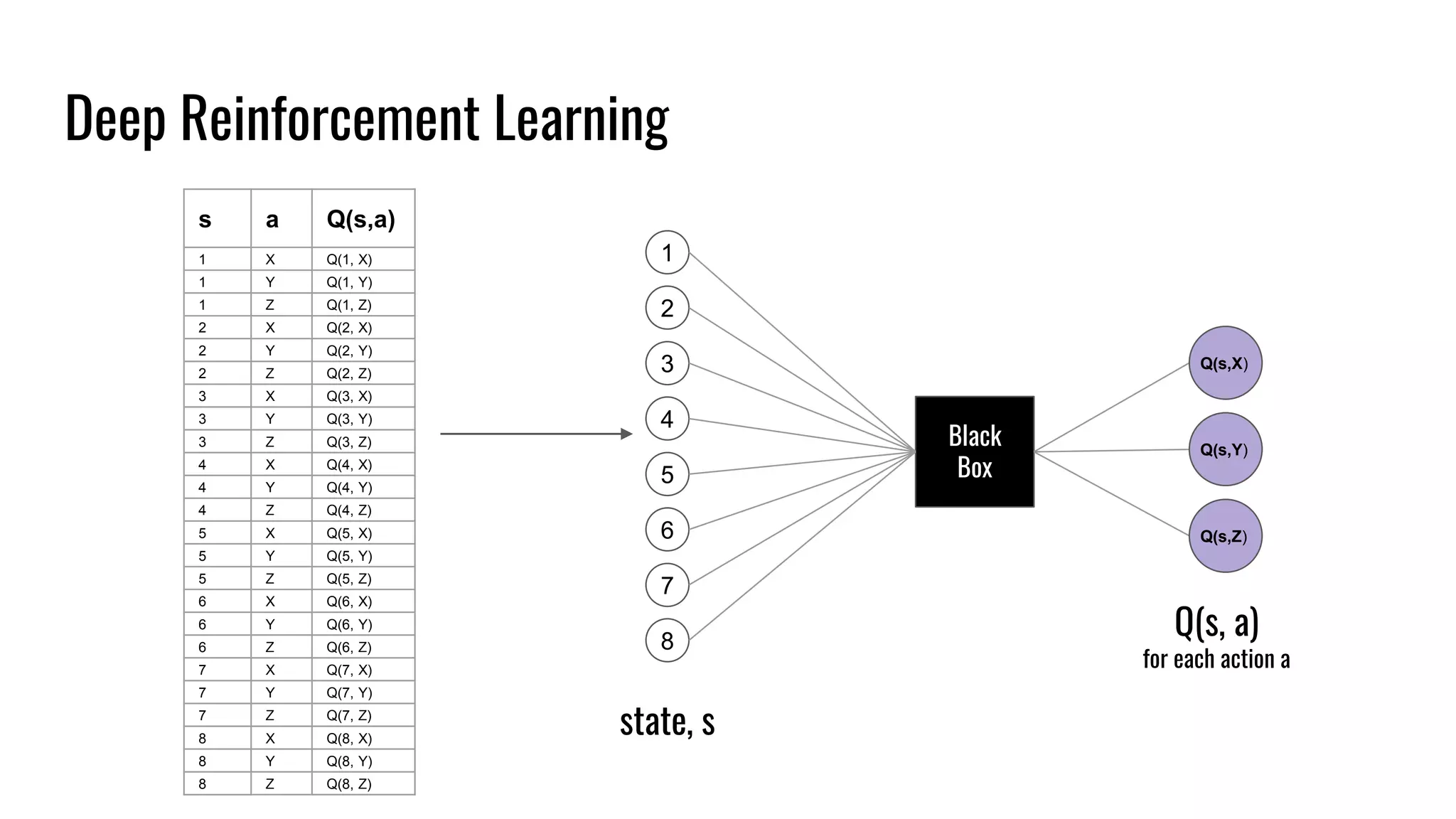
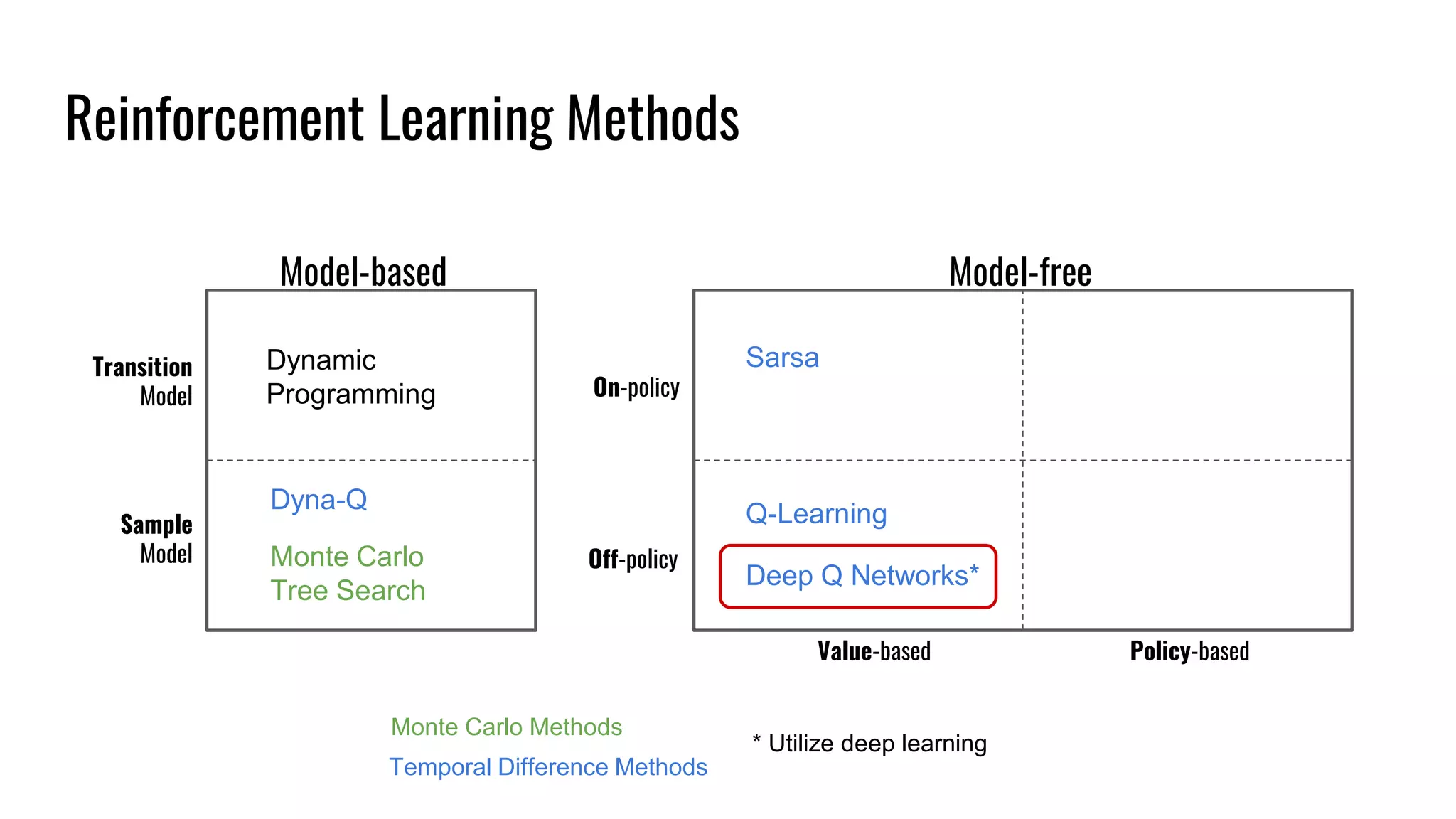
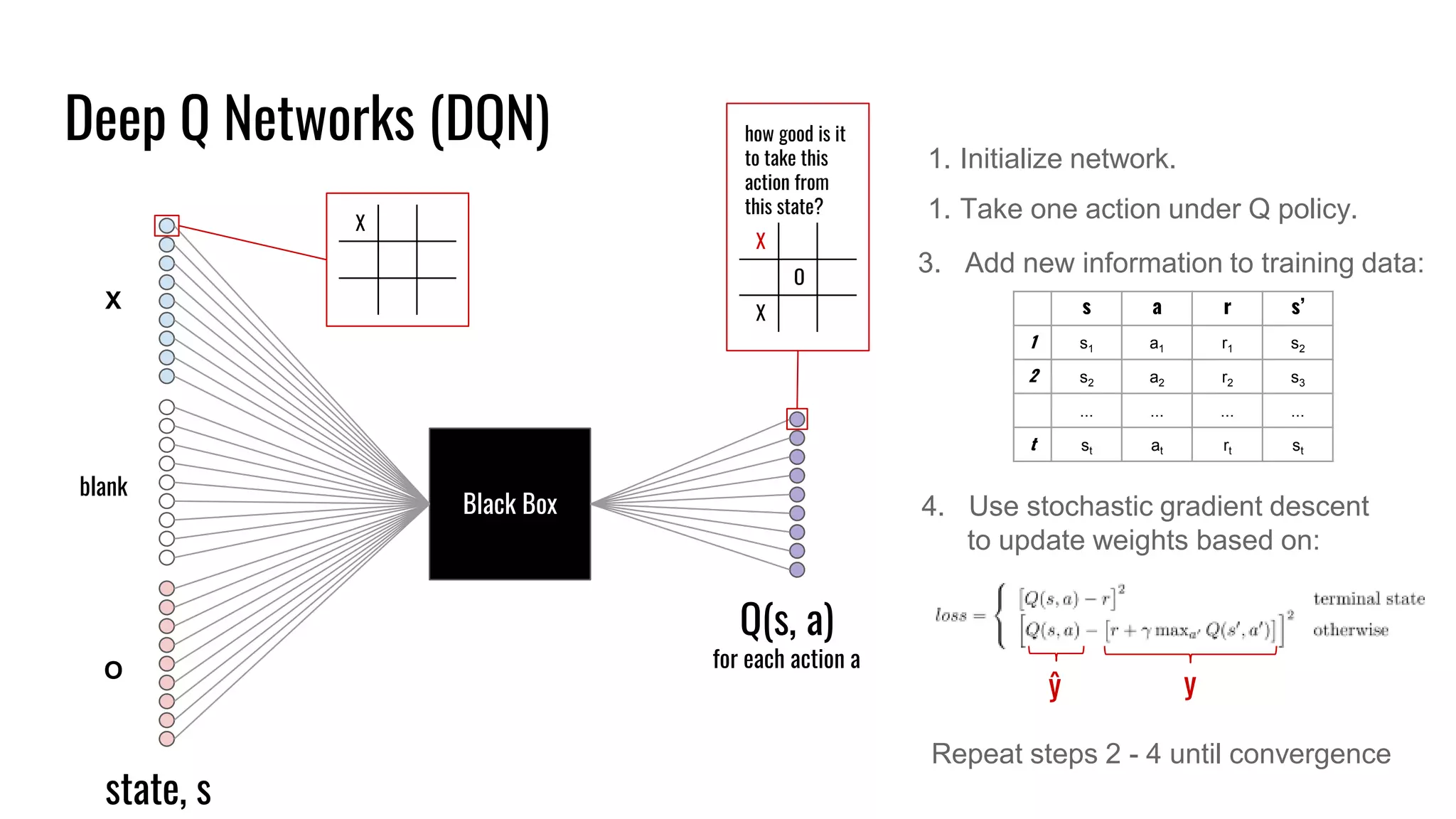

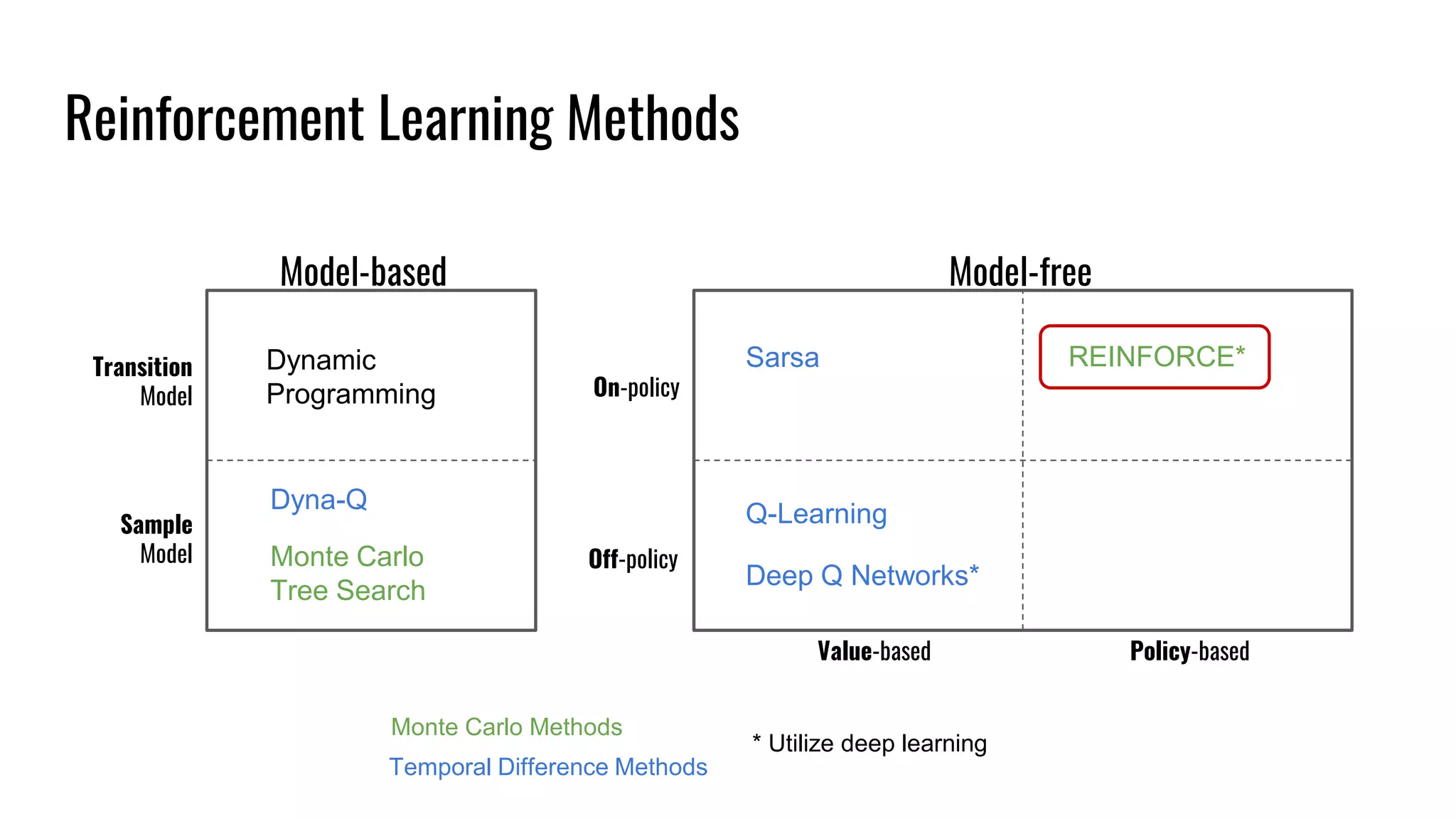
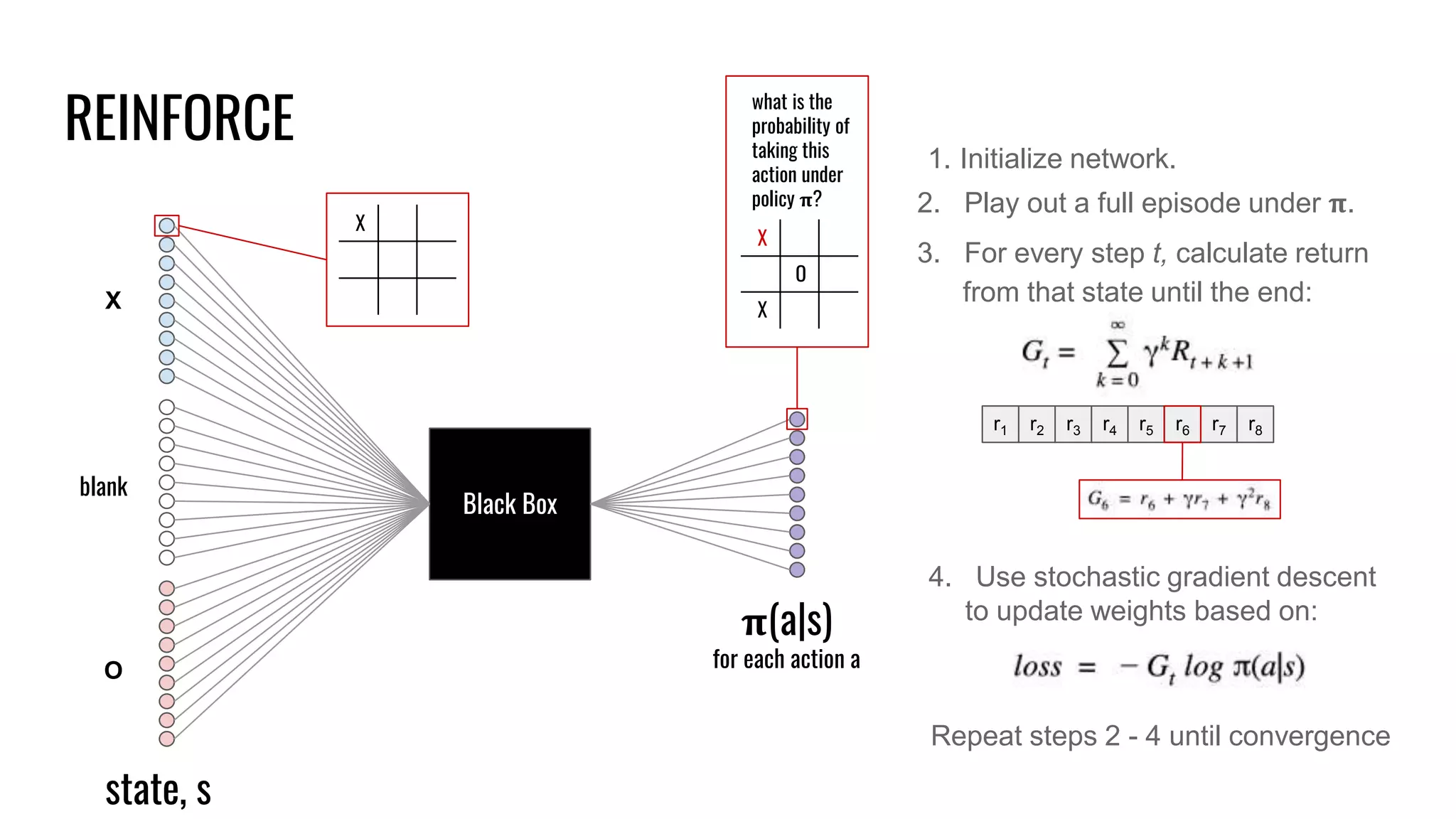
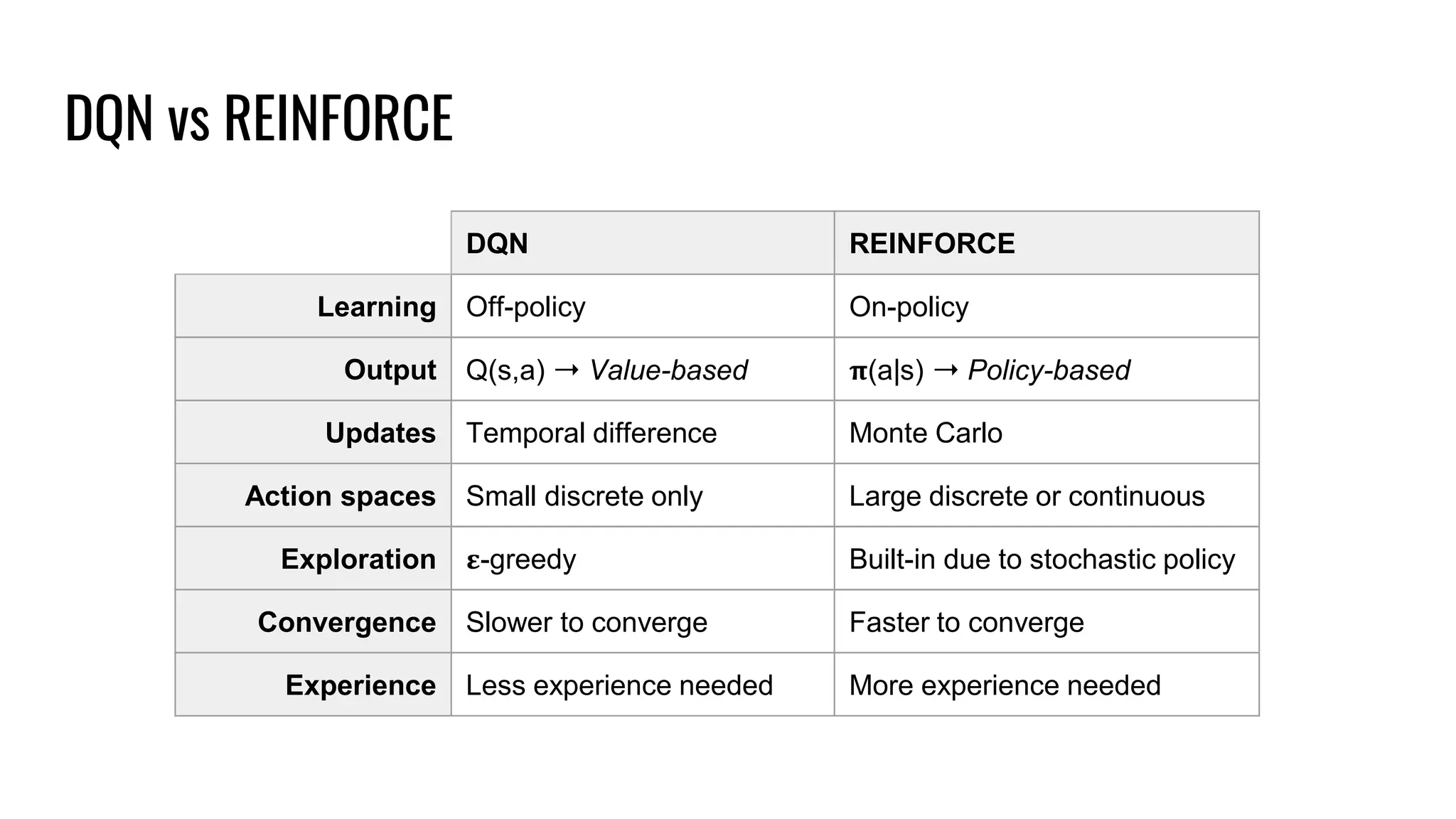
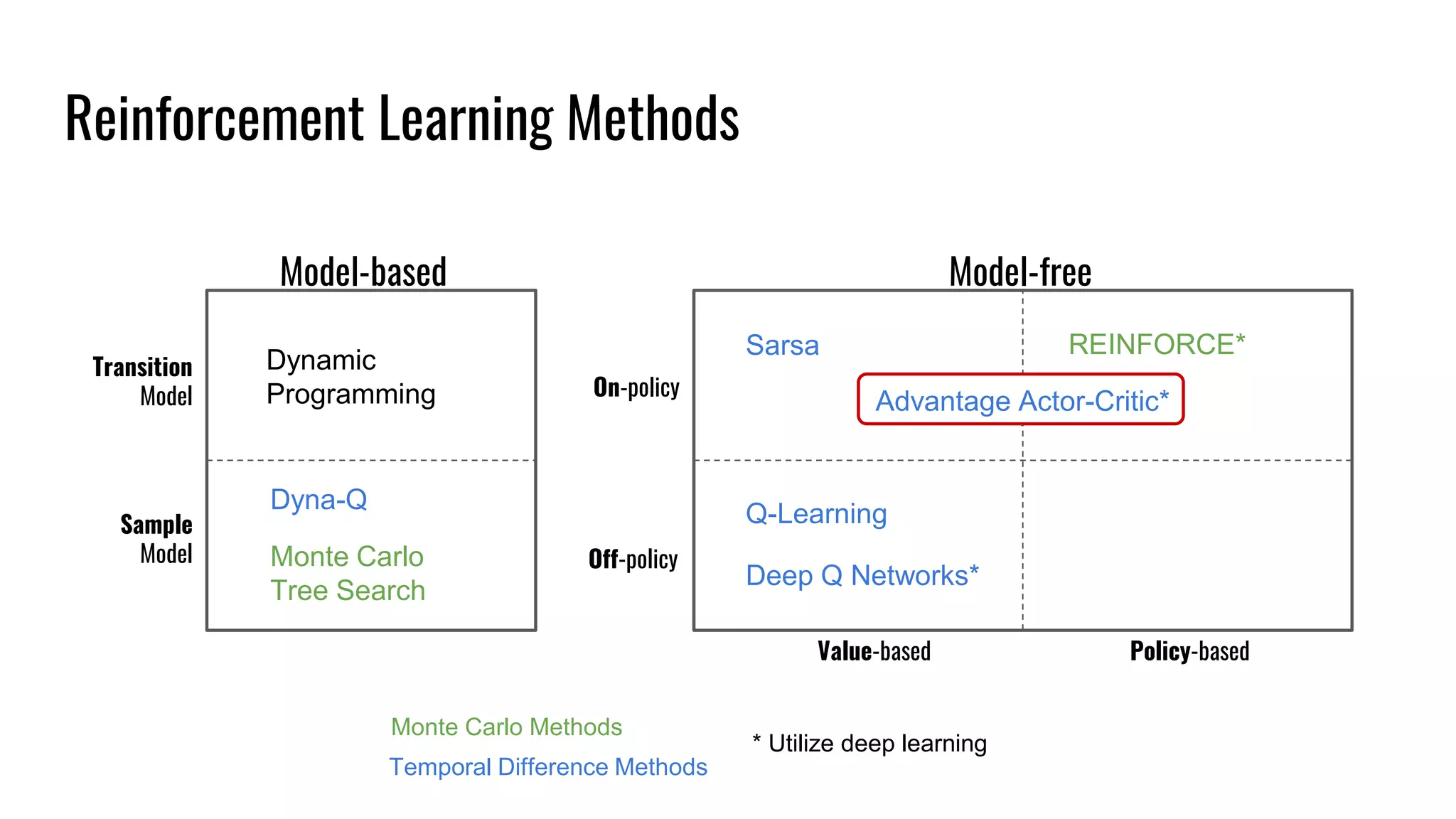
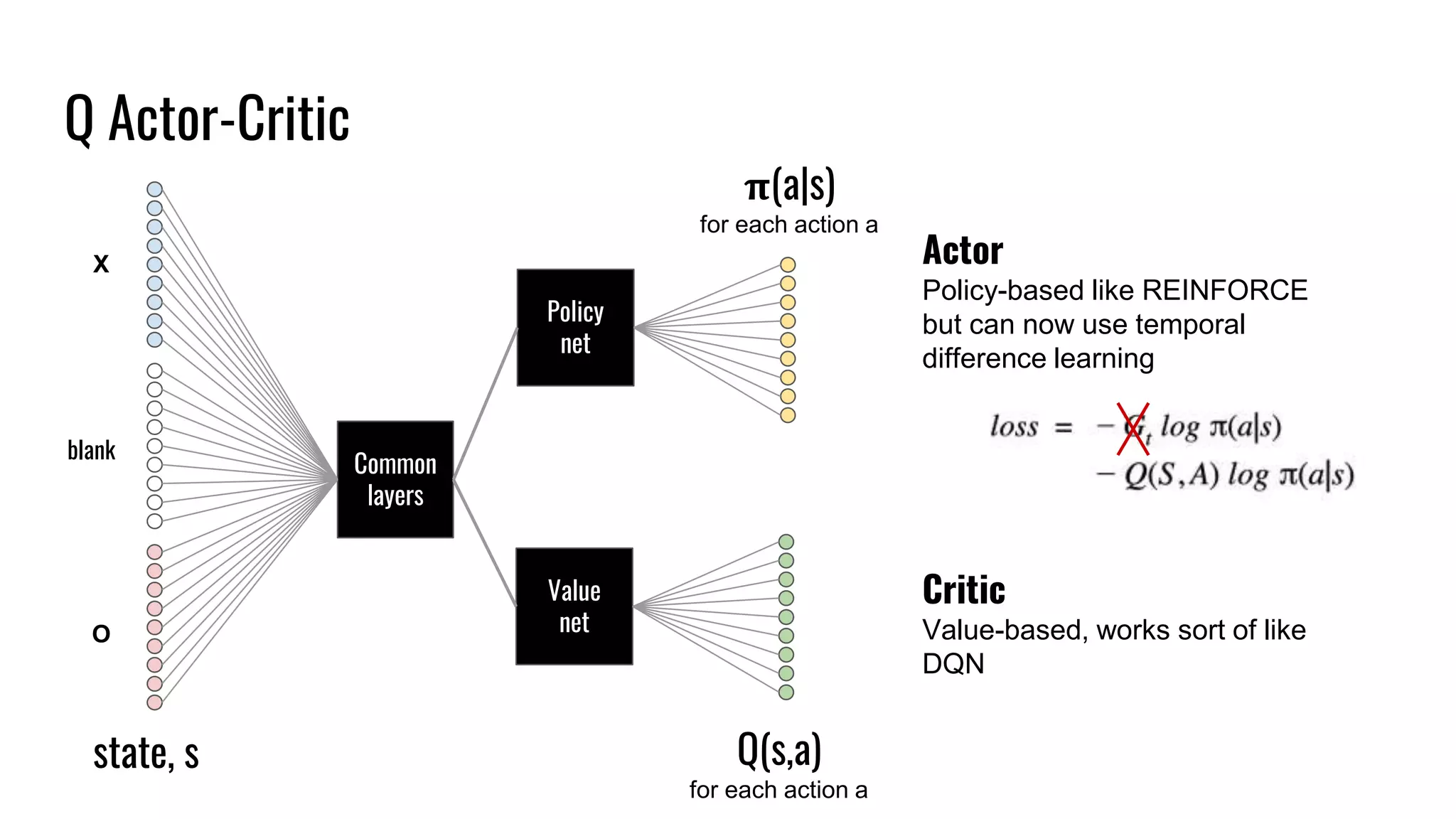
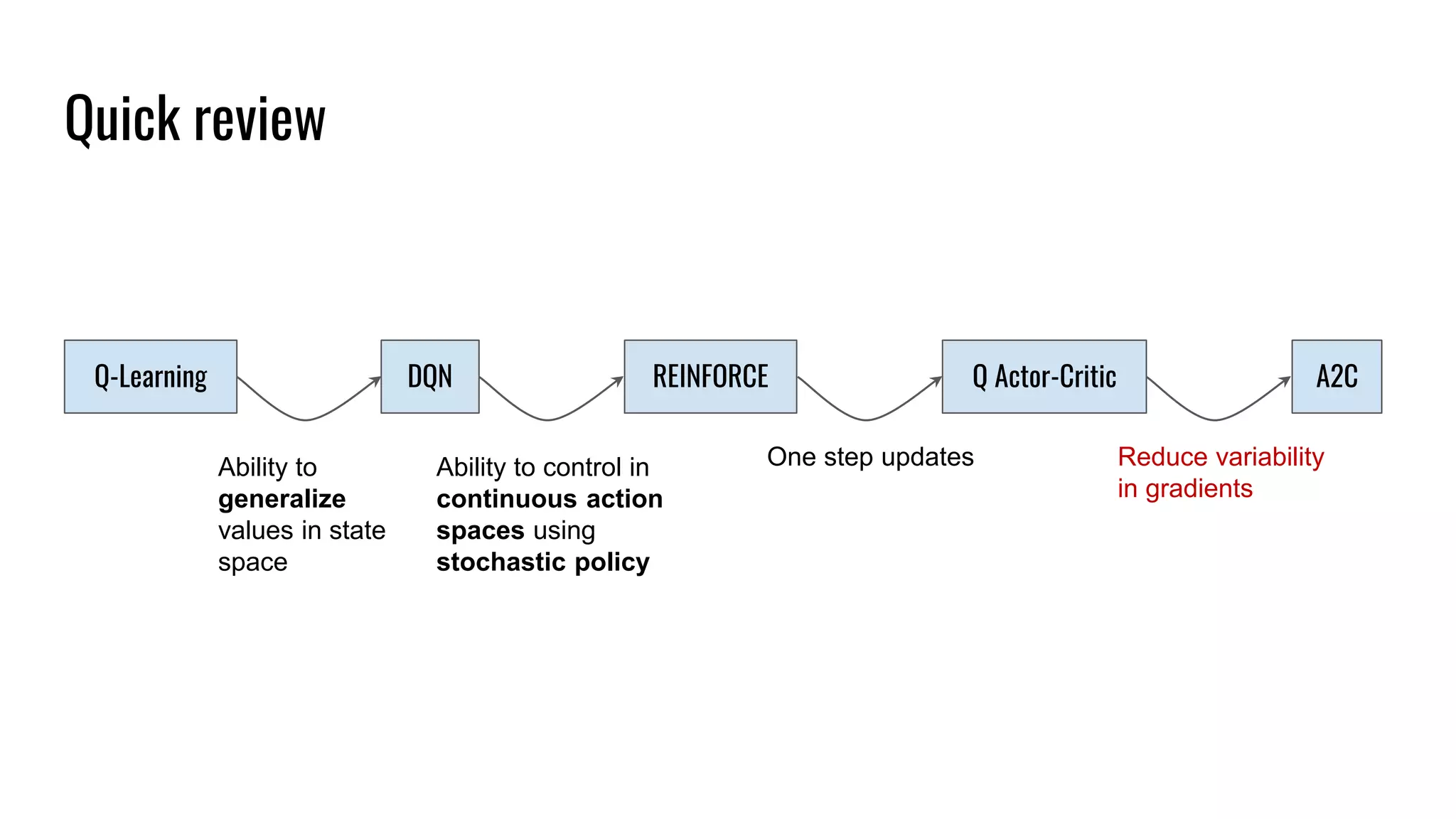
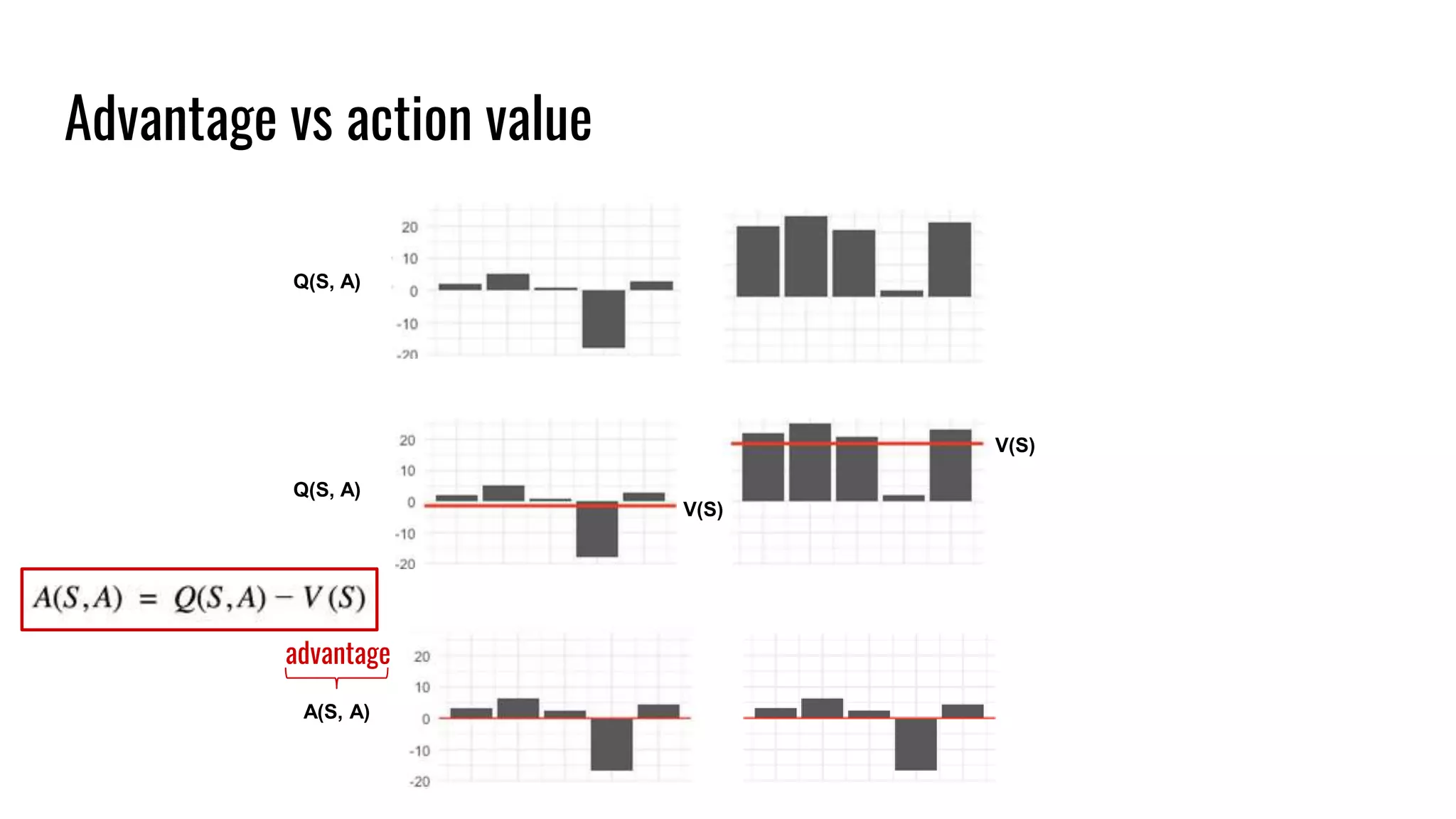
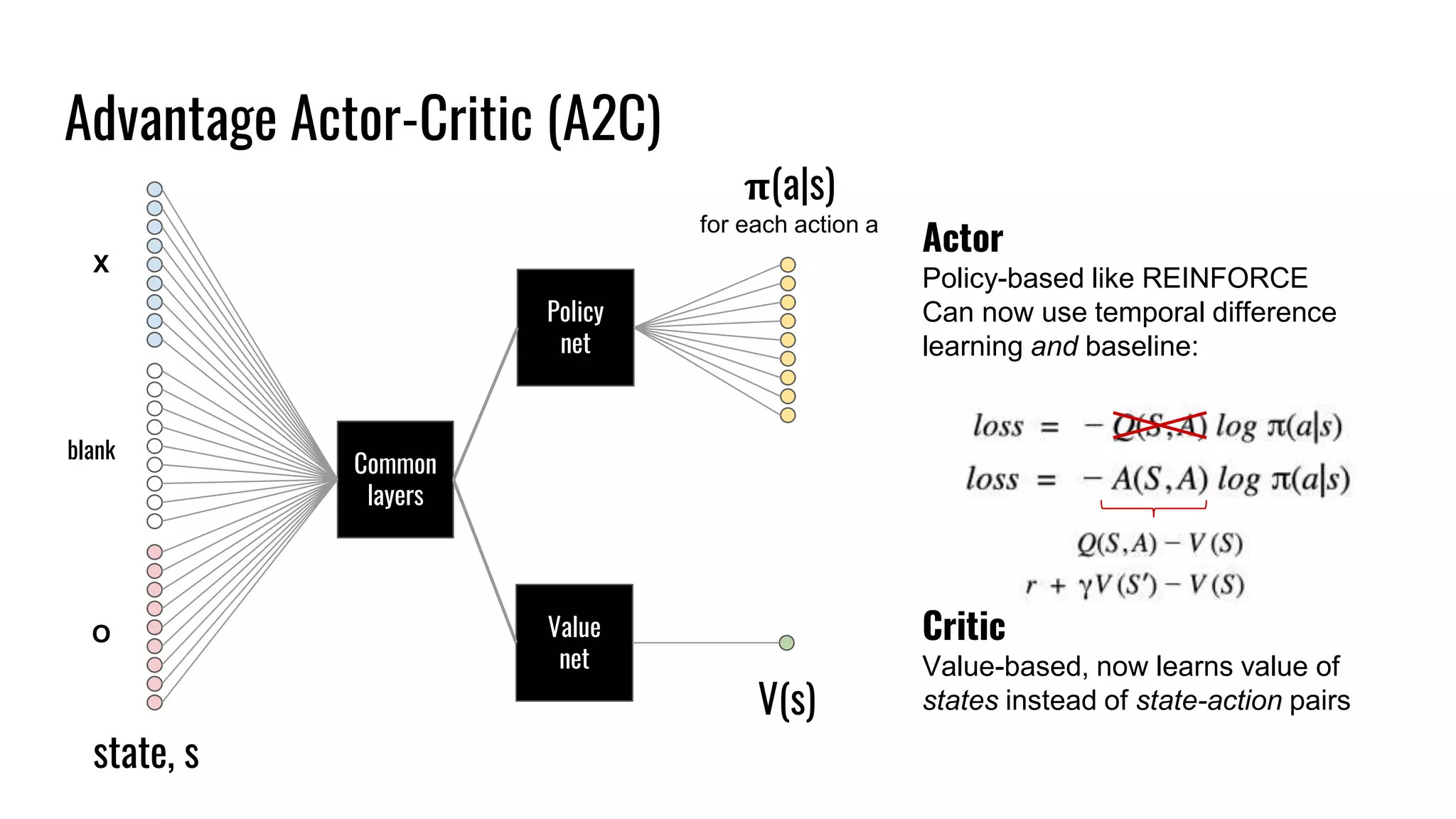


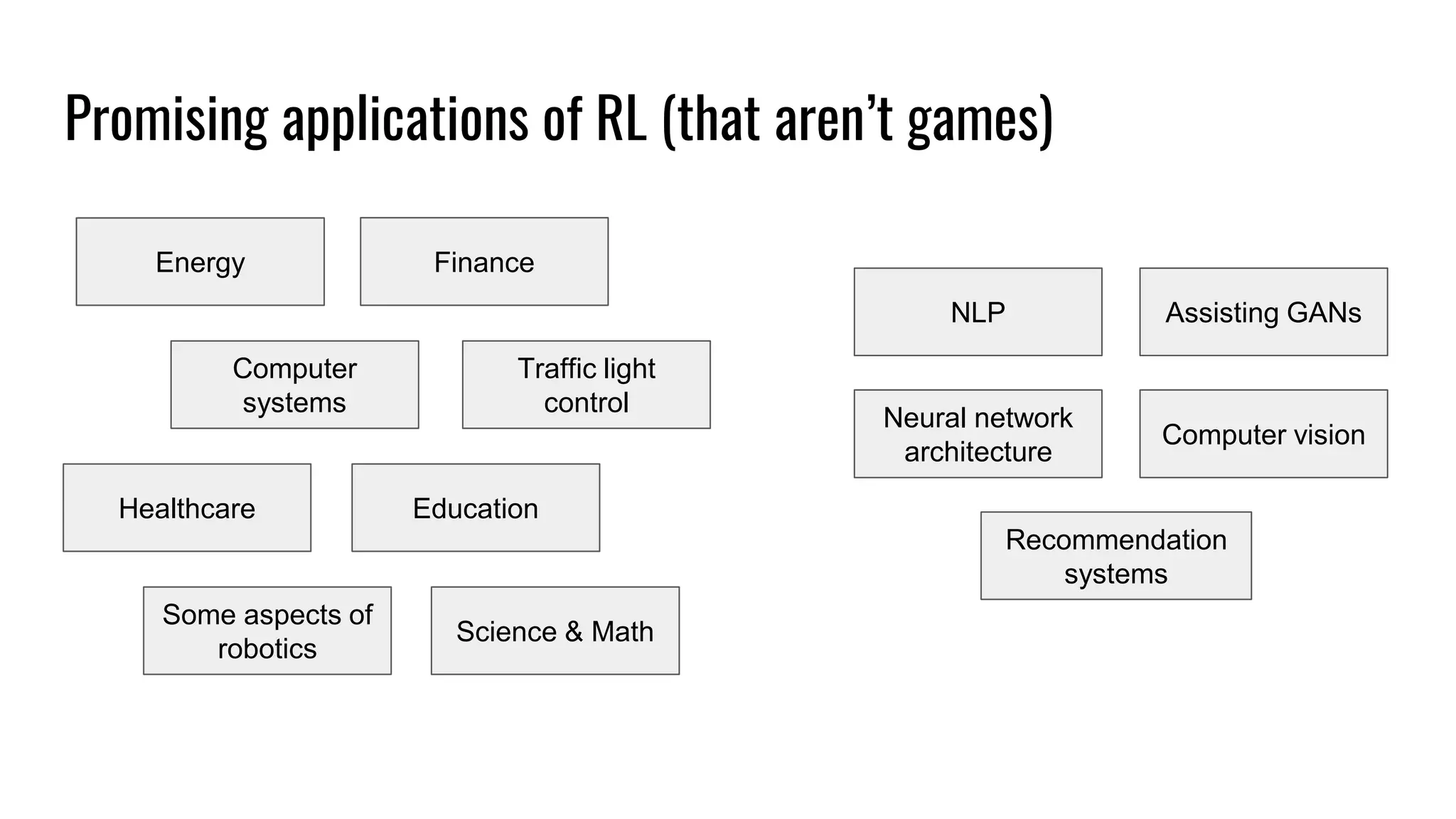


The document discusses the fundamentals and current state of reinforcement learning, outlining definitions, basic algorithms, and the complexities of reward design. It highlights the differences between model-based and model-free methods, along with various advanced techniques such as deep Q-networks and policy-based approaches. Despite ongoing advancements, reinforcement learning faces significant challenges in practical applications and requires extensive data for effective algorithm training.




























































