This document is a final report for a CS799 course that explores using reinforcement learning to train an agent to play a chasing game. The author defines the game environment and mechanics, then uses Q-learning with an epsilon-greedy exploration strategy to train an agent to maximize its score by collecting vegetables while avoiding walls, minerals, and other players. The agent is trained in multiple phases to first avoid walls, then minerals, and finally other players while collecting vegetables. Results are presented comparing training with different exploration vs exploitation settings.
![CS799 Final Report
Reinforcement Learning to Train Agent
Abhanshu Gupta
Department of Computer Sciences
University of Wisconsin Madison
Email: abhanshu@cs.wisc.edu
Abstract—Reinforcement learning is the learning of a mapping
from situations to actions so as to maximize a scalar reward or
reinforcement signal. The learner is not told which action to
take, as in most forms of learning, but instead must discover
which actions yield the highest reward by trying them. In the
most interesting and challenging cases, actions affect not only
the immediate reward, but also the next situation, and through
that all subsequent rewards. These two characteristics trial-and-
error search and delayed reward are the two most important
distinguishing features of reinforcement learning. In this report,
a study about applying Reinforcement Learning to design a
automatic agent to play a chasing game on given Agent World
test-bed is presented. One of the challenge in the game is how to
handle the agent in the complex and dynamic game environment.
By abstracting the game environment into a state vector defined
by sensor readings and using Q learning an algorithm oblivious
to transitional probabilities I achieve tractable computation time
and fast convergence. In the initial phase-I train, my agent is
trained to avoid walls. After that in the next phase the agent is
trained to avoid minerals and to maximize its output by taking
vegetables. In the last phase of training, the agent is trained to
avoid other players, minerals and walls while maximizing the
score by taking vegetables. I also compared and analysed the
results for training agent with exploration v/s exploitation choice
keeping learning rate α and discount factor γ constant.
I. INTRODUCTION
Using artificial intelligence (AI) and machine learning
(ML) algorithms to play computer games has been widely
discussed and investigated, because valuable observations can
be made on the ML play pattern vs that of a human player, and
such observations provide knowledge on how to improve the
algorithms. Agent-World[1] provides the framework to play
the classic chasing game.
Reinforcement Learning (RL) [2] is one widely-studied and
promising ML method for implementing agents that can sim-
ulate the behaviour of a player. The reinforcement learning
problem is summarized in Figure 1. On some short time cycle,
a learning agent receives sensory information from its envi-
ronment and chooses an action to send to the environment. In
addition, the learning agent receives a special signal from the
environment called the reward. Unlike the sensory information,
which may be a large feature vector, or the action, which
may also have many components, the reward is a single real
valued scalar number. The goal of learning is the maximization
of the cumulative reward received over time. Reinforcement
learning systems can be defined as learning systems designed
for and that perform well on this problem. Informally, we
define reinforcement learning as learning by trial and error
from performance feedback i.e., from feedback that evaluates
Fig. 1: The Reinforcement Learning Problem. The goal is to
maximize cumulative reward [3]
the behaviour generated by the learning agent but does not
indicate correct behaviour.
In this project, I study how to construct an RL controller
agent, which can learn from the game environment. One of
the difficulties of using RL is how to define state, action, and
reward. In addition, playing the game within the framework
requires real-time response, therefore the state space cannot
be too large. I use a state representation sense by sensors,
that abstracts the whole environment description into several
discrete-valued key attributes. I used Q-Learning algorithm to
evolve the decision strategy that aims to maximize the reward.
The rest of this report is organized as follows: Section 2
provides a brief overview of the Agent-World Test-bed and
the Q-Learning algorithm; Section 3 explains how I define
the state, action, reward to be used in RL algorithm; Section 4
provides evaluation results; Section 5 concludes current results
and discusses continued future work on the project.
II. BACKGROUND
In this section, I briefly introduce the Agent-World frame-
work interface and the Q-learning algorithm I used.
A. Game Mechanics and Agent-World Test-bed
The goal of the game is to control the agent to maximize
the score while playing collecting vegetables and beating other
animals with minerals. An agent senses the environment using
his sensors and than makes an intelligent decision. In each
iteration agent moves a unit step in a particular direction to
maximize its score. These set of permissible directions are
aligned with directions of sensors. The game is over when the
allotted time for each game ends. At the end the player with
maximum score is designated as winner.
The provided test-bed Agent-World is conducive for testing
artificial intelligence techniques in a simplified universe. The](https://image.slidesharecdn.com/7d7b5349-1b34-4bbb-a7ac-1d9fd48ee1f1-161226185741/75/CS799_FinalReport-1-2048.jpg)
![Fig. 2: Agent-World Test-Bed Environment
universe of this test-bed consists of four types of entities: ani-
mals (also know as, ’agents’ or ’players’), minerals, vegetables,
and walls. One or more agents will be in a universe at a time.
For each action an agent takes, it receives a reward. Negative
rewards include running into walls, pushing minerals, bumping
into other agents, and running into sliding minerals. Positive
rewards include eating vegetables and pushing minerals into
other agents. During the game, when performing each step, the
Agent-World framework interface call could return the com-
plete observation of environment through sensor readings. The
number of sensors can be configured and has a fixed range. The
environment of this test-bed along with the sensor locations
are shown in Figure 2. These sensor readings are an array
containing the positions and types of enemies/items/platforms
within this range. The framework interface call can also
provide the reward for the agent for being in the current state.
This is the whole available information for my agent.
B. -Greedy Q-Learning
Q-learning treats the learning environment as a state ma-
chine, and performs value iteration to find the optimal policy. It
maintains a value of expected total (current and future) reward,
denoted by Q, for each pair of (state, action) in a table. It may
at first seem surprising that one can choose globally optimal
action sequences by reacting repeatedly to the local values
of Q for the current state. This means the agent can choose
the optimal action without ever conducting a lookahead search
to explicitly consider what state results from the action. Part
of the beauty of Q learning is that the evaluation function
is defined to have precisely this property-the value of Q for
the current state and action summarizes in a single number all
the information needed to determine the discounted cumulative
reward that will be gained in the future if action a is selected
in state s. Thus the Q value for each state-action transition
equals the reward value for this transition plus the maximum
value for the resulting state discounted by y. So for each action
in a particular state, a reward r will be given and the Q-value
is updated by the following rule for deterministic case:
Q(st, at) ← r + γMax(Q(st+1, at+1)) (1)
Above we considered Q learning in deterministic environ-
ments. But the gaming environment in most of the games
is non-deterministic and hence resulting state from st due
to action at is not known. Our earlier training rule derived
for the deterministic case (1) fails to converge in this non-
deterministic setting. A non-deterministic reward function r(s,
a) that produces different rewards each time the transition (s,
a) is repeated. In this case, the training rule will repeatedly
alter the values of Q(S, a), even if we initialize the Q table
values to the correct Q function. In brief, this training rule does
not converge. This difficulty can be overcome by modifying
the training rule so that it takes a decaying weighted average
of the current Q value and the revised estimate. Writing Q,
to denote the agent’s estimate on the nth iteration of the
algorithm, the following revised training rule is sufficient to
assure convergence of Q:
Q(st, at) ← (1−αs,a)Q(st, at)+αs,a(r+γMax(Q(st+1, at+1)))
(2)
In the Q-learning algorithm, there are four main factors: current
state, chosen action, reward and future state. In (2), Q(st,at)
denotes the Q-value of current state and Q(st+1, at+1) denotes
the Q-value of future state. α [0,1] is the learning rate, γ
[0,1] is the discount rate, and r is the reward. (2) shows that for
each current state, I update the Q-value as a combination of
current value, current rewards and max possible future value.
I chose Q-learning for two reasons:
1) Although I have modelled the game as approximate
Markov Model, the specific transitional probabilities
between the states is not known. Had I used the
normal reinforcement learning value iteration, I will
have to train the state transitional probabilities as
well. On the other hand, Q-learning can converge
without using state transitional probabilities (”model
free”). Therefore Q-learning suits my need well.
2) When updating value, normal value iteration needs
to calculate the expected future state value, which
requires reading the entire state table. In comparison,
Q learning only needs fetching two rows (values for
standst+1) in the Q table. With the dimension of
the Q table in thousands, Q learning update is a lot
faster, which also means given the computation time
and memory constraint, using Q table allows a larger
state space design.
The learning rate α affects how fast learning converges. I use a
decreasing learning rate αs,a different for different (s, a) pairs.
The value of α is given by:
αst,at
= 1/(1 + visted(st, at)) (3)
the equation is chosen based on the criteria proposed by
Watkins original Q-learning paper[4]. He shows the following
properties of α is sufficient for the Q values to converge.
1) α(st, at) → 0 as t → ∞.
2) α(st, at) monotonically decreases with t.
3)
∞
t=1 α(st, at) = ∞
One can easily verify the series (3) satisfy all the properties.
The discount factor γ denotes how much future state is taken
into account during optimization. I evaluated under several
values and chose 0.9 as the final value. When training my
agent, I used -greedy Q-learning to explore more states. The
algorithm is a small variation of Q-learning: each step the](https://image.slidesharecdn.com/7d7b5349-1b34-4bbb-a7ac-1d9fd48ee1f1-161226185741/75/CS799_FinalReport-2-2048.jpg)
![algorithm chooses the best action according to the Q table
with probability (1 - ). After performing the action, the Q
table is updated as in (2).
III. AGENT CONTROLLER DESIGN
In this section, I have described the design of the state,
action, and rewards used in the Q-learning algorithm.
A. Agent State
State of the agent at any point is the game is defined as the
combination vector of reading of each sensor.The state vector
is computed using one-of-k encoding on the sensed value of
each sensor. The magnitude of each entry of this vector is the
measure of proximity of the sensed object to the agent. This is
computed using distance between the agent and sensed object
after normalizing with the range of the sensor. In this project, I
have used 36 sensors with a uniform angular separation of 10o
.
These sensors are configured to sense 5 different possibilities
{nothing, animal,vegetable,mineral and wall}. Hence, each of
these sensors sense these five possibilities in a unique direction
to define agent’s environment at a particular state. This state
vector is necessary and sufficient to define the physical state
of the agent at any point of time. The Q function values for
each of the actions are then computed for the state using
a perceptron neural network model. The training for these
models is done using back-propagation rule using a back-
propagation learning rate η of 0.1. Thus I have initialized
a perceptron model for each of the actions which generate
different Q values for different state input vectors based on
the learning.
B. Action
In this game, an action is defined as a step taken by the
agent in a particular direction which leads to a transition in its
state from sttost+1. In this project I have considered 36 valid
actions, each corresponding to a step taken in the direction of
the 36 sensors.
C. Rewards
The reward function for this game has been provided by
the test-bed framework interface. For each action an agent
takes, it receives a reward. The reward r(st, at) for state st
is determined by the test-bed based on the new state st+1
that agent will be in after taking action at on the current
state. Negative rewards include running into walls (-1), pushing
minerals (-2), bumping into other agents (-3), and running
into sliding minerals (-25). Positive rewards include eating
vegetables (+5), and pushing minerals into other agents (+25).
If an agent does not run into any other object, it receives a
reward of zero.
IV. EVALUATION RESULTS
For training the -greedy Q-learning algorithm, I have used
perceptron with squared error objective function and ReLU
activation function to compute the Q values for each action.
The training of the agent is done in three phases with each
phase using the learned network of the previous phase as
starting point. For the first phase training, perceptron weights
Fig. 3: Learning Curve for Phase-I Training
for each action are initialized with a uniform distribution [-
0.1,0.1]. Each training game was defined as the set of 5000
iterations. Each game of training was done with 36 perceptrons
for parameter values of η = 0.1, = 0.2 and γ = 0.9. The
training terrain used for each phase along with its motivation
is described below:
A. Phase I
The goal of this phase of training is to train the agent
to avoid walls and hence training is done on barren field for
around 50 games using a constant α value of 1.0. The learning
curve for this training is shown in Figure 3. This curve is
generate by using the learned network weights after 10 games
each and than testing those networks with α = 0 for 5 games
and taking the average score. This phase trained the agent to
avoid walls.
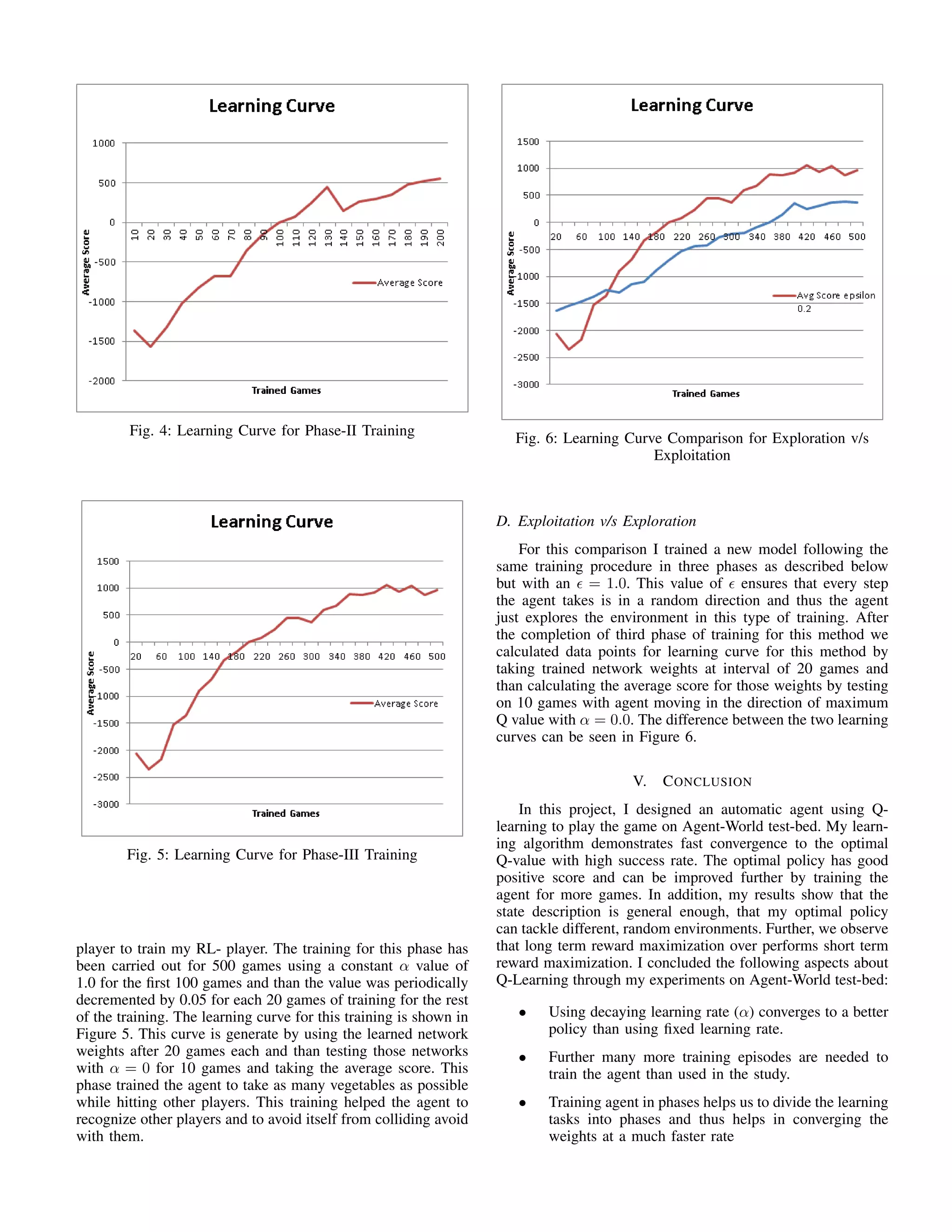
B. Phase II
The goal of this phase of training is to train the agent
to avoid walls and minerals while maximizing the score by
taking vegetables and hence training is done on sparse field
with 50 minerals and 50 vegetables for around 200 games
using a constant α value of 0.8 for the first 100 games and
value of 0.4 for the last 100 games. The learning curve for this
training is shown in Figure 4. This curve is generate by using
the learned network weights after 10 games each and than
testing those networks with α = 0 for 5 games and taking the
average score. This phase trained the agent to take as many
vegetables as possible while avoiding minerals and walls.
C. Phase III
The goal of this phase of training is to train the agent to
maximize the score generated by taking vegetables and hitting
other players while avoiding a collision with walls, minerals
and other players. For this training I have selected a topography
with 100 minerals and 100 vegetables along with few players. I
have used 2 anonymous players, 1 random walker and a smart](https://image.slidesharecdn.com/7d7b5349-1b34-4bbb-a7ac-1d9fd48ee1f1-161226185741/75/CS799_FinalReport-3-2048.jpg)
![• Exploration is a good option for training in initial
stages but will not be beneficial later on due to very
slow convergence compared to Exploitation scheme.
I believe that my work provides a good introduction to this
problem and will benefit the people with interests in using re-
inforcement learning to play computer games. Some continued
future work on the project includes:
• Further training the agent for more training episodes
to get a more detailed view of the learning curve
• Using hidden layers in neural nets instead of percep-
trons for Q value functions computation and compare
the effect.
• Introducing other types of smart players and RL-
players in the training process and notice their effect
on the agents training.
REFERENCES
[1] Framework:http://pages.cs.wisc.edu/˜shavlik/cs540/html/agent-world.html
[2] Tom M. Mitchell, Machine Learning, McGraw-Hill Science,1997.
[3] Richard S. Sutton, Reinforcement Learning Architectures, GTE Labora-
tories Incorporated, Waltham, MA.
[4] Watkins and Dayan, Q-learning.Machine Learning, 1992.
[5] J. Shavlik lecture notes, CS 760 - Machine Learning, Univ of Wisconsin
- Madison, 2010.
[6] David Page lecture notes, CS 760 - Machine Learning, Univ of Wisconsin
- Madison, 2015.
[7] Mark Craven lecture notes, CS 760 - Machine Learning, Univ of
Wisconsin - Madison, 2016.](https://image.slidesharecdn.com/7d7b5349-1b34-4bbb-a7ac-1d9fd48ee1f1-161226185741/75/CS799_FinalReport-5-2048.jpg)

































![Q-Learning Algorithm: A Concise Introduction [Shakeeb A.]](https://cdn.slidesharecdn.com/ss_thumbnails/q-learningshakeebabuzarmustafasneha-200921155609-thumbnail.jpg?width=640&height=640&fit=bounds)











