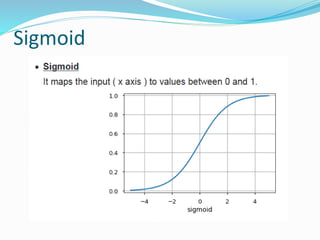
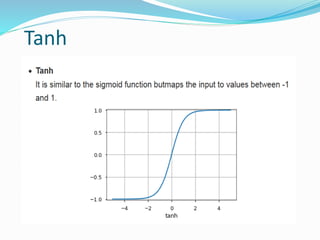
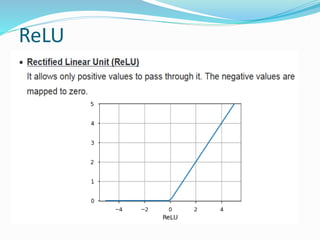
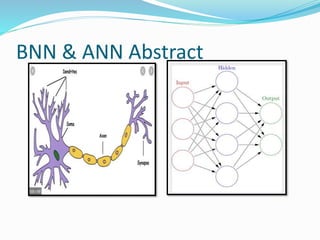
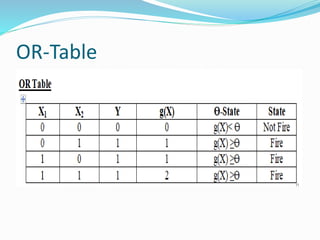
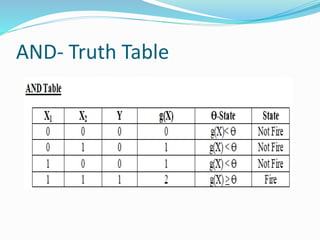
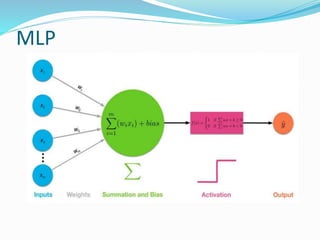
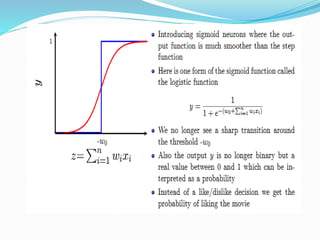
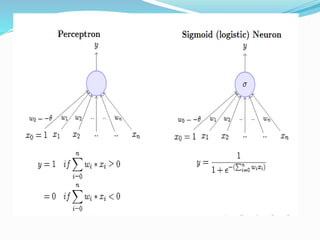
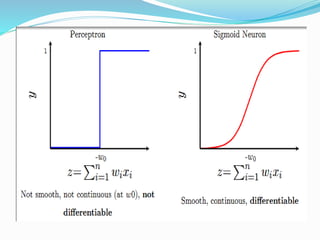
The document discusses the history and concepts of artificial intelligence and machine learning. It describes early models like the McCulloch-Pitts neuron and perceptron, and how they evolved with the introduction of backpropagation and multi-layer perceptrons using sigmoid activation functions. Key algorithms discussed include naive Bayes, k-means clustering, and decision trees. Deep learning concepts like convolutional neural networks are also covered at a high level.














































![Geometric Interpretation
Our main objective is to navigate through the error
surface inorder to reach a point where the error is less
or close to zero.
Let us assume θ = [w,b] where w & b are the weights
and the biases respectively. θ is an arbitrary point on
the error surface.To start with w & b are randomly
initialized and this is our starting point.
θ is a vector of parameters w and b such that θ ∈ R².](https://image.slidesharecdn.com/deeplearning-191024075306/85/Deep-learning-Mathematical-Perspective-53-320.jpg)
![ Let us assume Δθ = [Δw , Δb] where Δw & Δb are the
changes that we make to the weights and biases such
that we move in the direction of reduced loss and land
up at places where the error is less. Δθ is a vector in the
direction of reduced loss.
Δθ is a vector of parameters Δw and Δb such that Δθ ∈
R².
Now we need to move from θ to θ+Δθ such that we
move towards the direction of minimum loss](https://image.slidesharecdn.com/deeplearning-191024075306/85/Deep-learning-Mathematical-Perspective-54-320.jpg)