The document provides an overview of deep learning, covering fundamental concepts such as feedforward neural networks, gradient descent, and backpropagation. It discusses various types of neural networks including convolutional and recurrent networks, as well as advanced architectures like autoencoders and GANs. Key challenges such as unit saturation and the vanishing gradient problem are also addressed, with strategies for mitigation highlighted throughout.











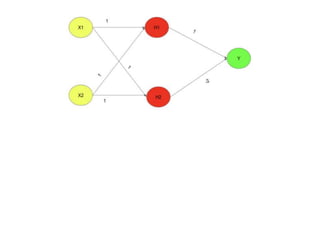
![We want our network to perform correctly on the four points X = {[0,
0], [0,1],[1,0], and [1,1]}.
We will train the network on all four of these points.
The only challenge is to fit the training set.
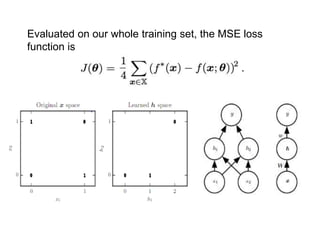
Evaluated on our whole training set, the MSE loss function is a
linear model, with θ consisting of w and b.
Our model is defined to be
f (x; w, b) = x T w + b.](https://image.slidesharecdn.com/unit-1introductionpart-1-240727050550-6d31eb84/85/deep-learning-UNIT-1-Introduction-Part-1-ppt-12-320.jpg)