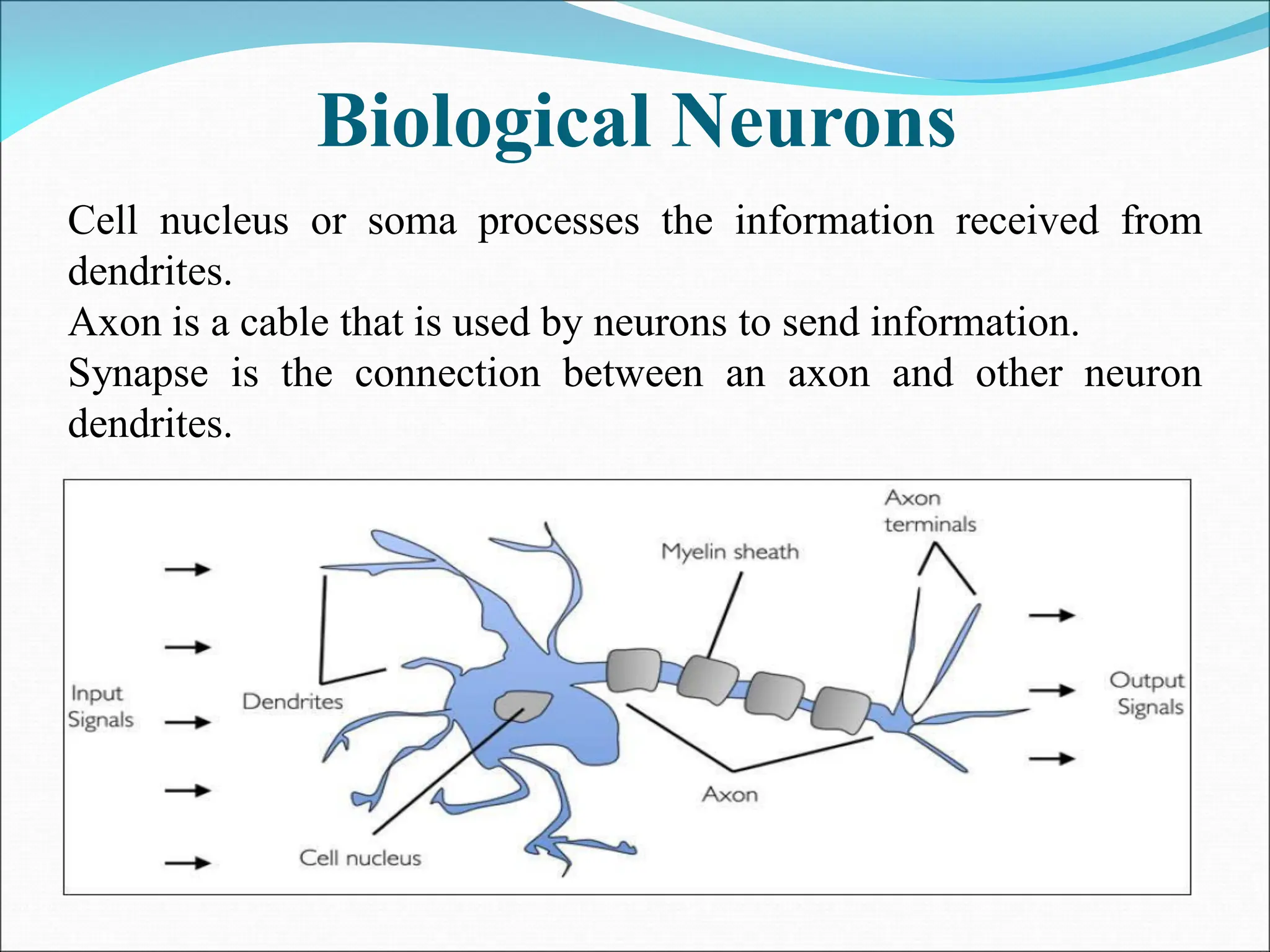
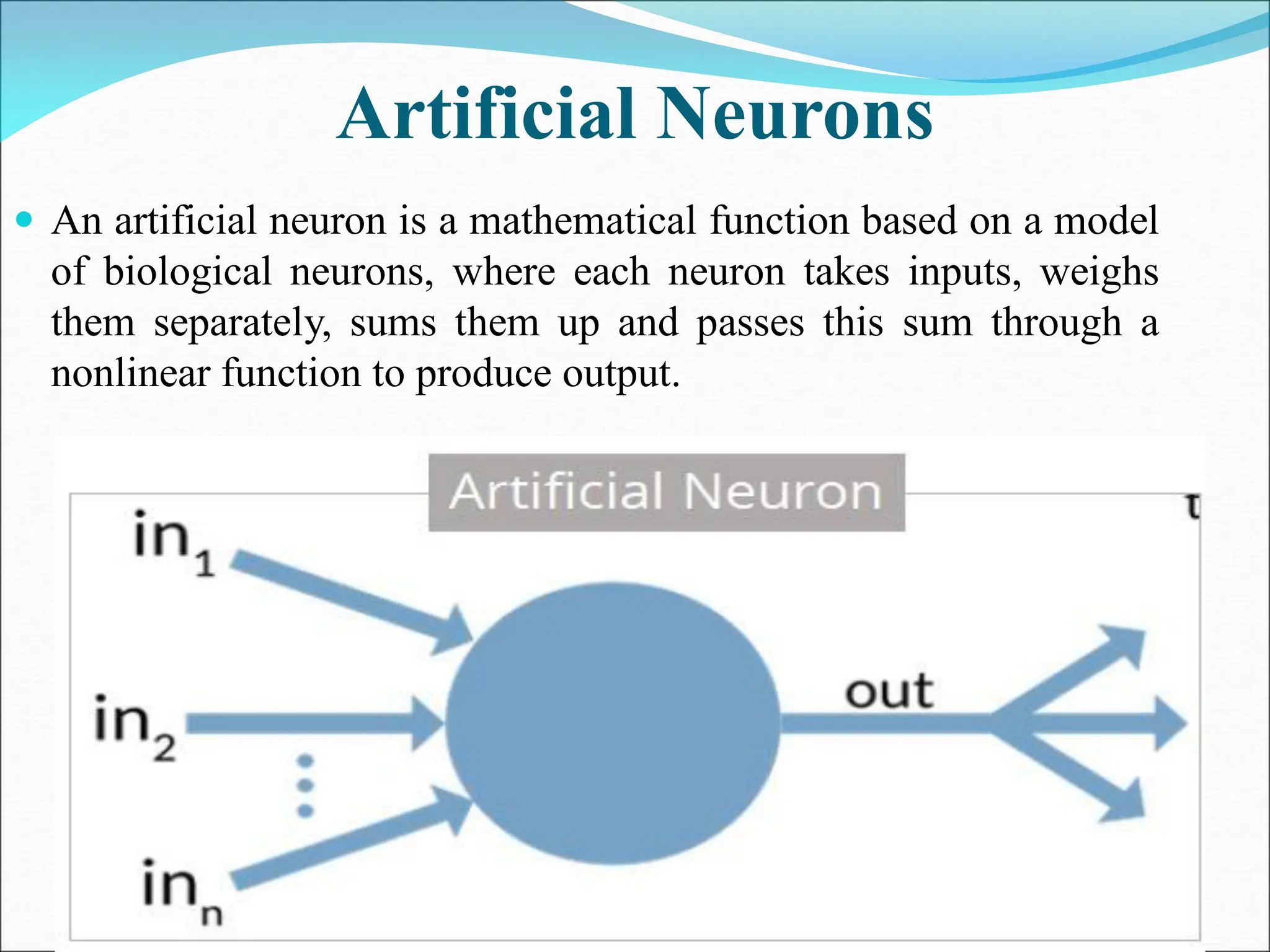
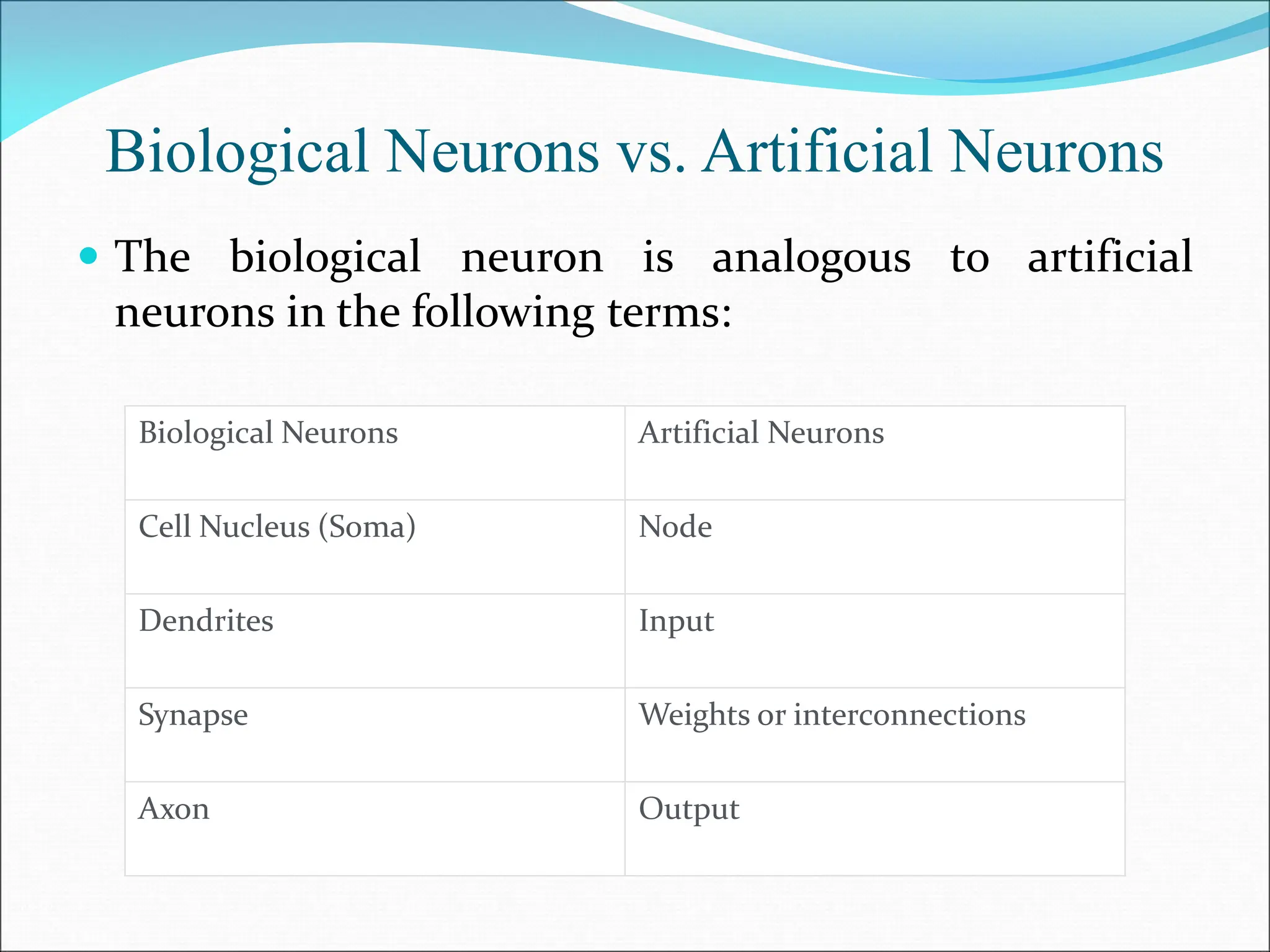
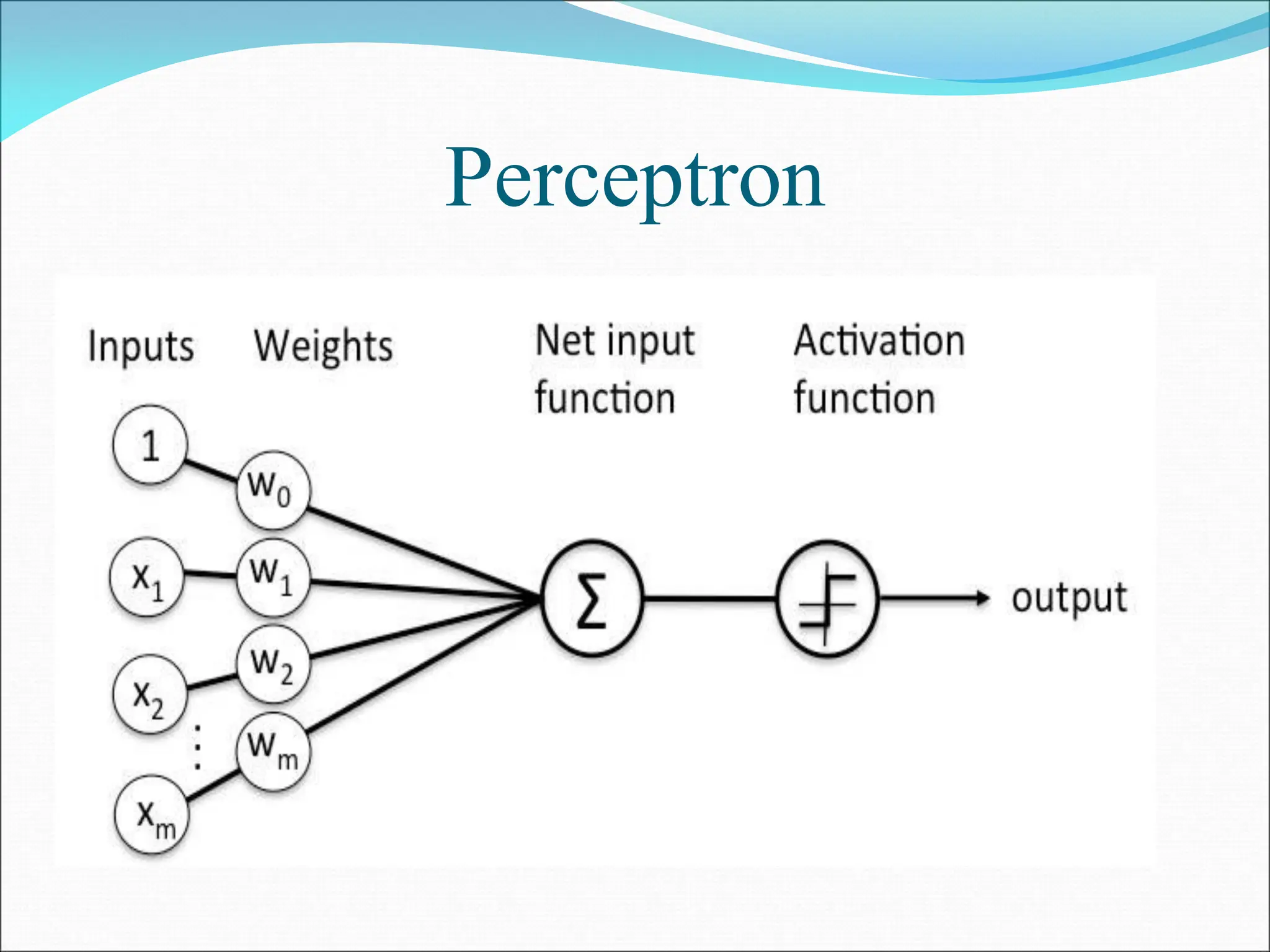
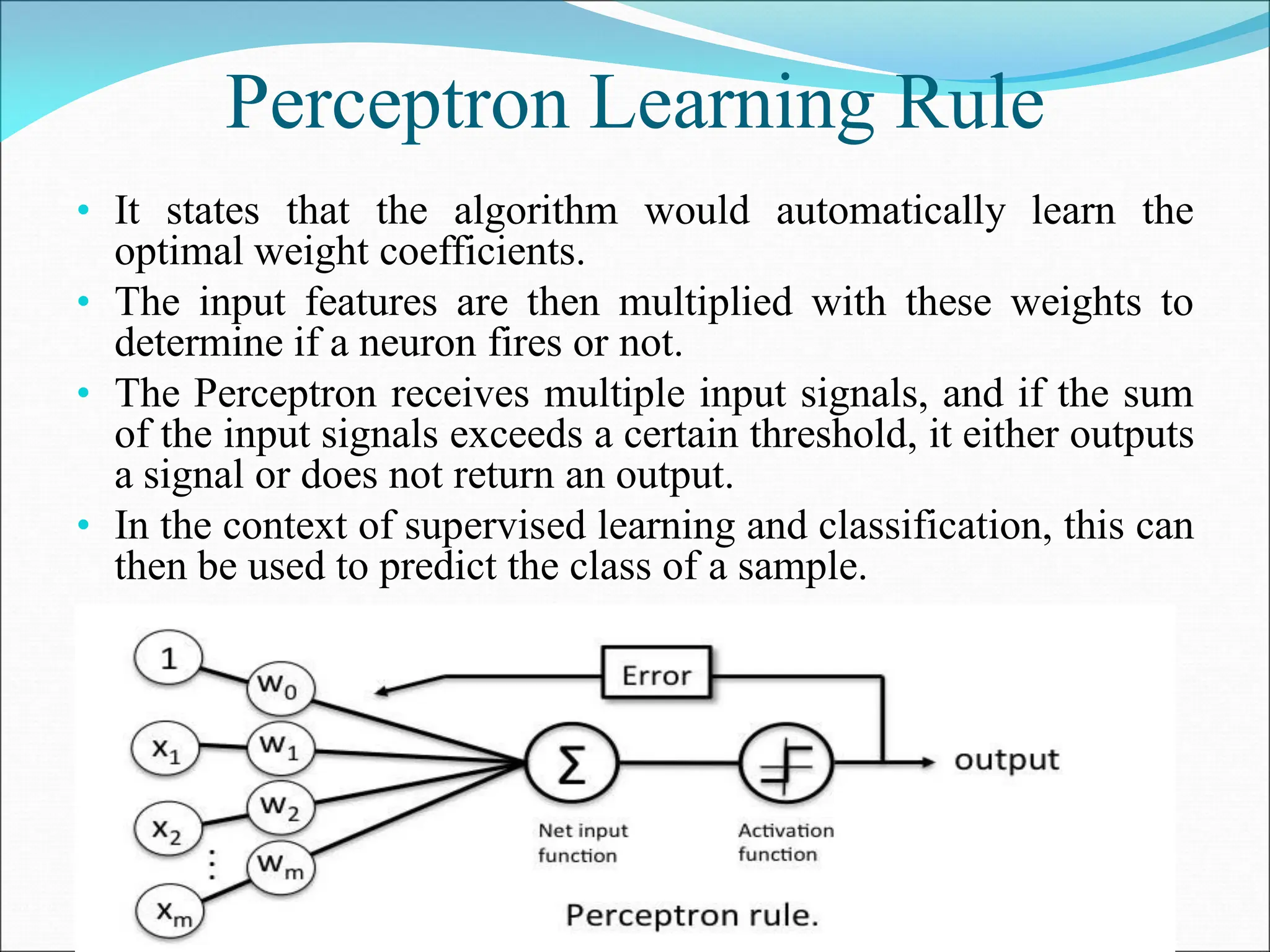
- A perceptron is a simple model of an artificial neuron that can be used for classification problems. It takes weighted inputs, sums them, and outputs 1 if the sum exceeds a threshold or 0 otherwise.
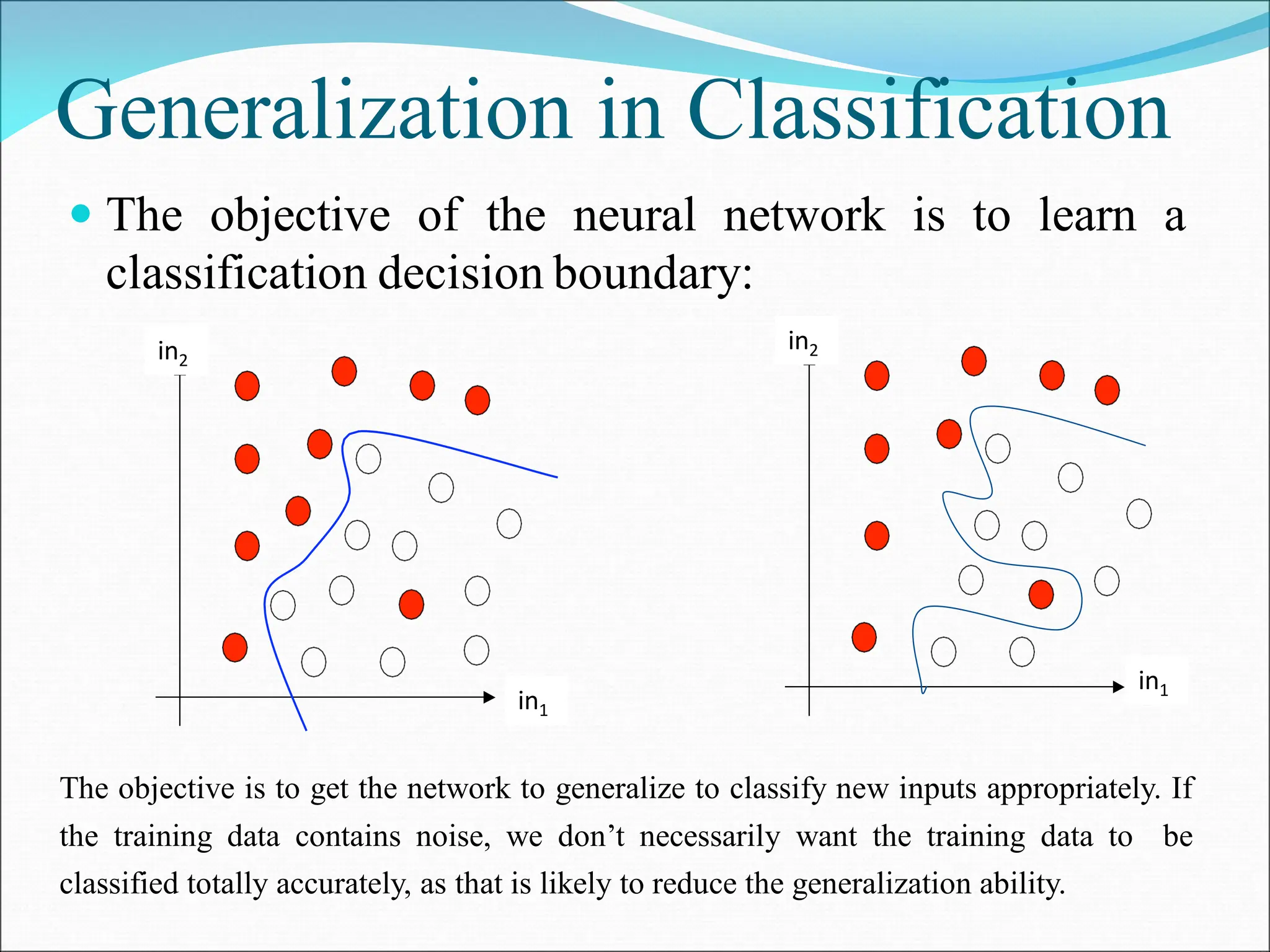
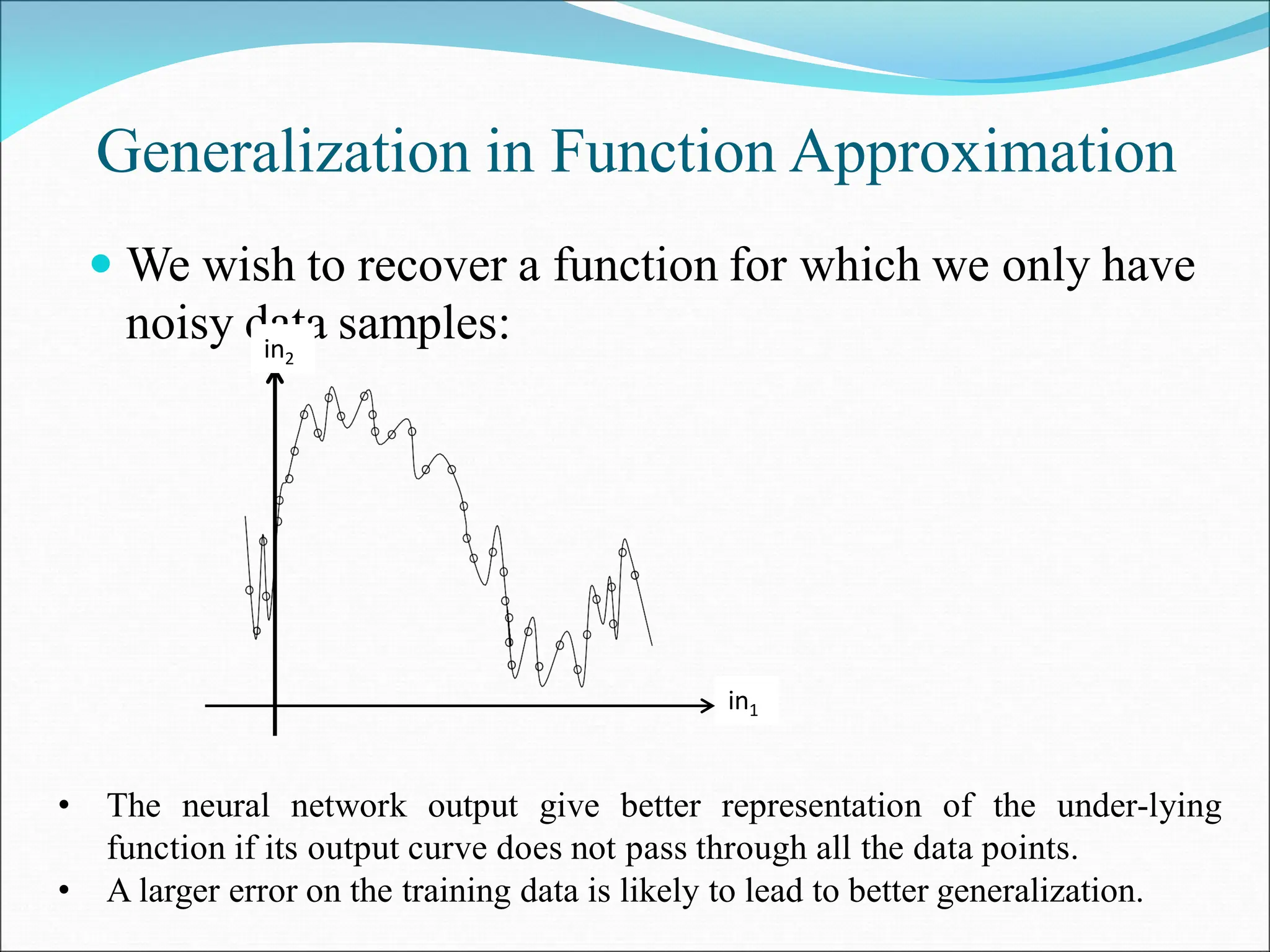
- Perceptrons can only learn linearly separable patterns. Multilayer perceptrons with more than one layer have greater processing power to learn nonlinear patterns.
- The perceptron learning rule adjusts the weights to correctly classify training examples by shifting the decision boundary in small steps. This allows the network to learn the optimal weights from data.