Downloaded 66 times














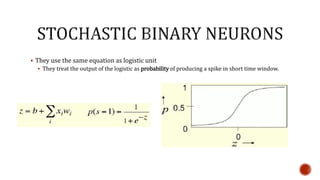




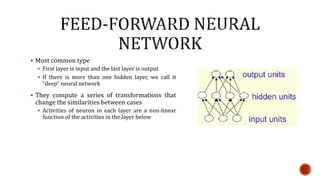




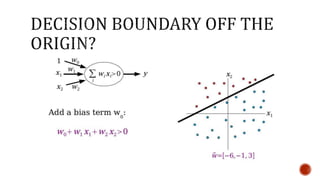
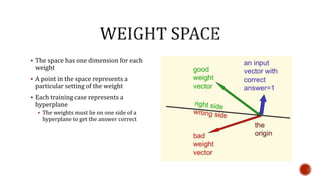
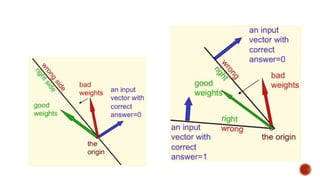


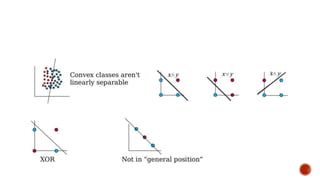





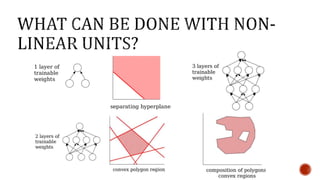
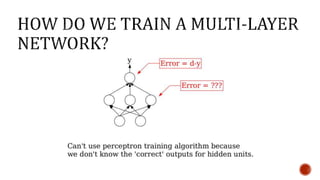







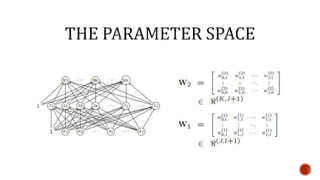




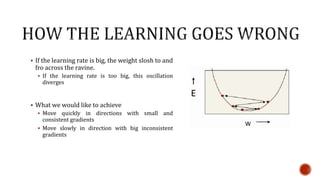




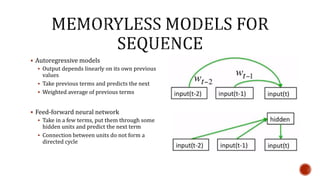
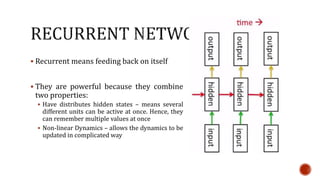


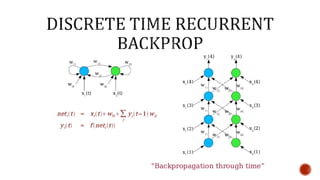
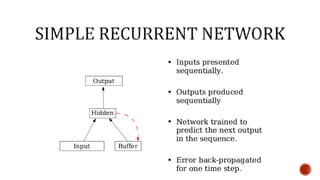
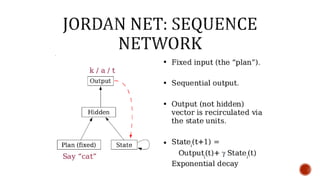
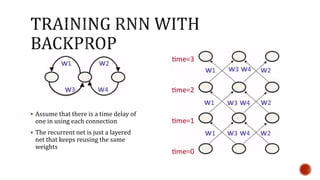
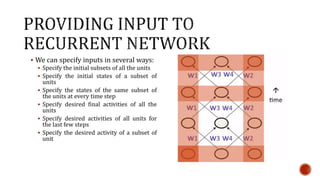

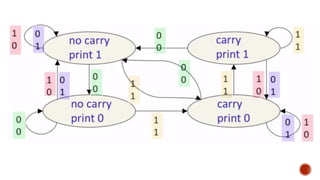

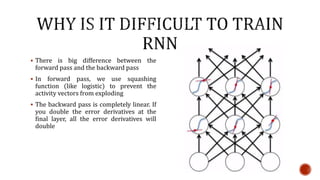




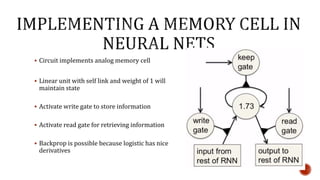
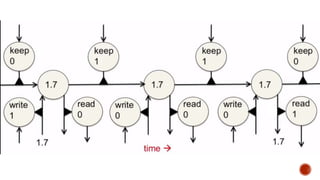

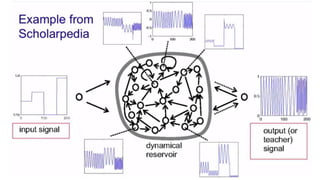


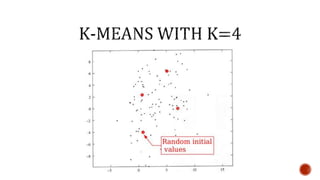





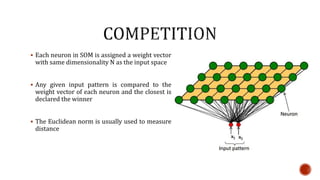
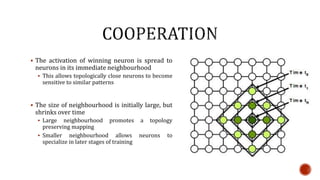
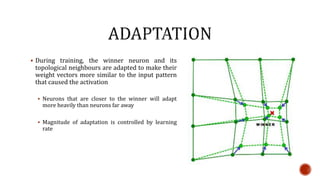






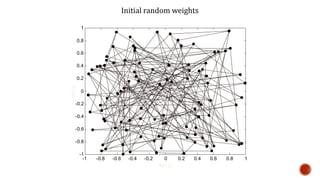


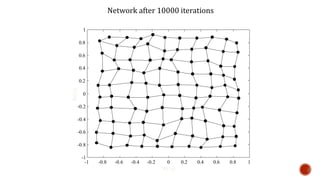





The document discusses machine learning and neural networks. It begins by explaining that machine learning algorithms take examples of input-output pairs and produce a program or model that can predict the correct output for new inputs. This is unlike traditional programming where humans write specific rules. The document then discusses different types of neural networks including feedforward, recurrent, convolutional and more. It explains concepts like supervised vs unsupervised learning, learning rules, gradient descent, long short term memory networks, and competitive learning.













































































