Download as PDF, PPTX



















![CQL List
• Ordered by insertion
• Use with caution
list_example list<text>
Collection name Collection type
INSERT INTO collections_example (id, list_example)
VALUES(1, ['1-one', '2-two']);
CQLType](https://image.slidesharecdn.com/datamodeling101-150323173336-conversion-gate01/75/Cassandra-Day-Atlanta-2015-Data-Modeling-101-20-2048.jpg)
![CQL List Operations
• Adding an element to the end of a list
• Adding an element to the beginning of a list
• Deleting an element from a list
UPDATE collections_example
SET list_example = list_example + ['3-three']
WHERE id = 1;
UPDATE collections_example
SET list_example = ['0-zero'] + list_example
WHERE id = 1;
UPDATE collections_example
SET list_example = list_example - ['3-three'] WHERE id = 1;](https://image.slidesharecdn.com/datamodeling101-150323173336-conversion-gate01/75/Cassandra-Day-Atlanta-2015-Data-Modeling-101-21-2048.jpg)

![CQL Map Operations
• Add an element to the map
• Update an existing element in the map
• Delete an element in the map
UPDATE collections_example
SET map_example[3] = 'three'
WHERE id = 1;
UPDATE collections_example
SET map_example[3] = 'tres'
WHERE id = 1;
DELETE map_example[3]
FROM collections_example
WHERE id = 1;](https://image.slidesharecdn.com/datamodeling101-150323173336-conversion-gate01/75/Cassandra-Day-Atlanta-2015-Data-Modeling-101-23-2048.jpg)





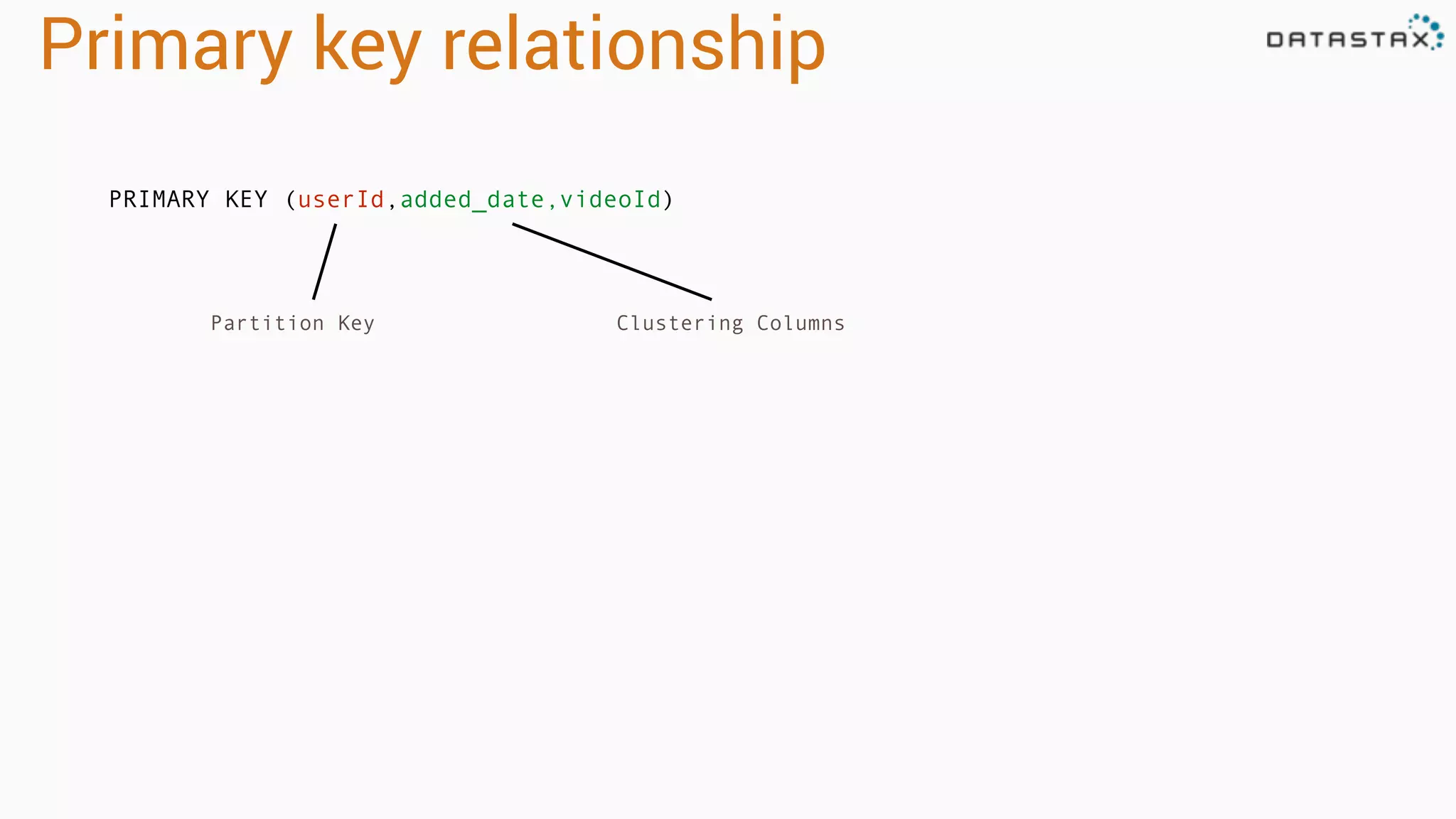
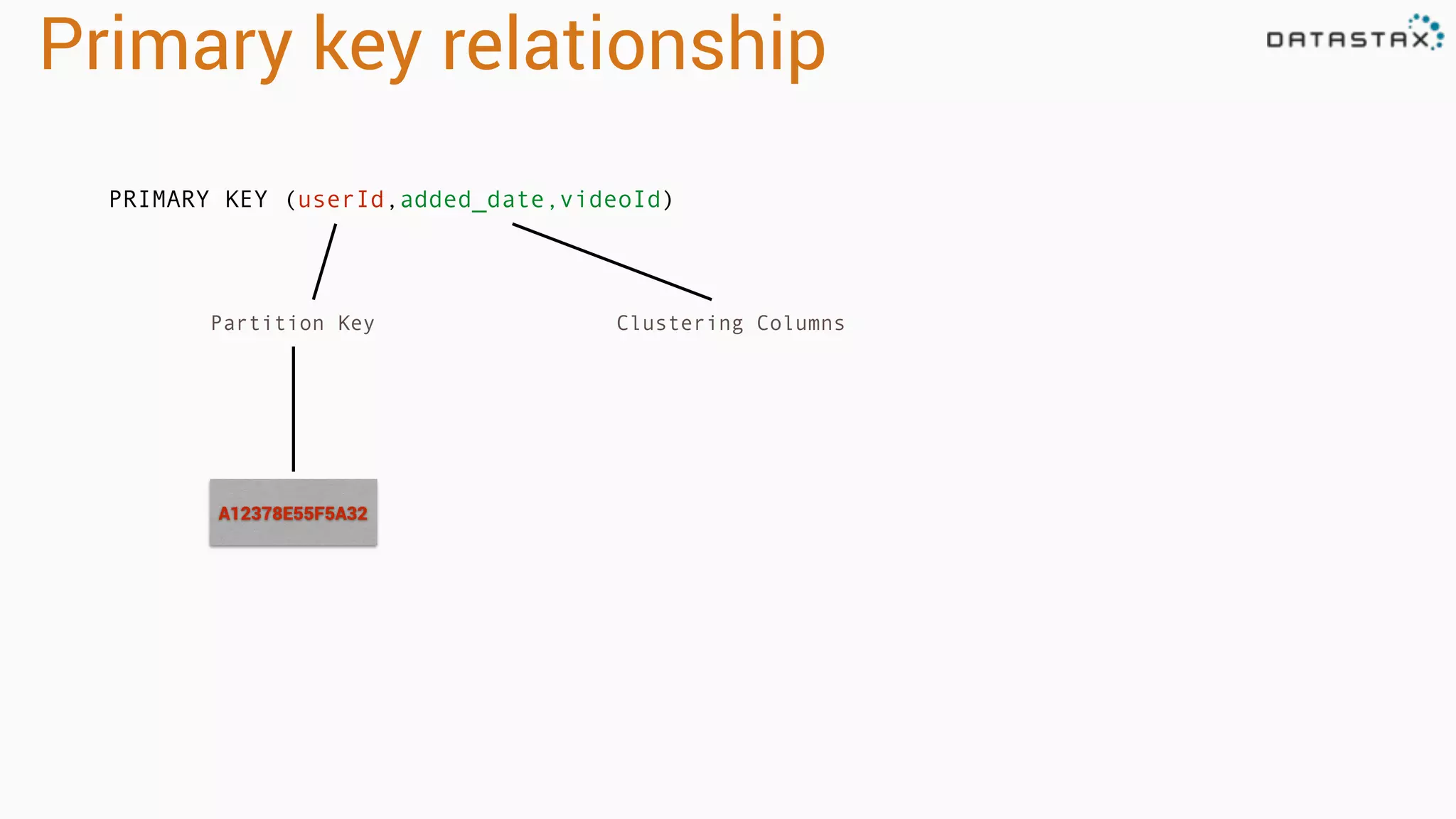
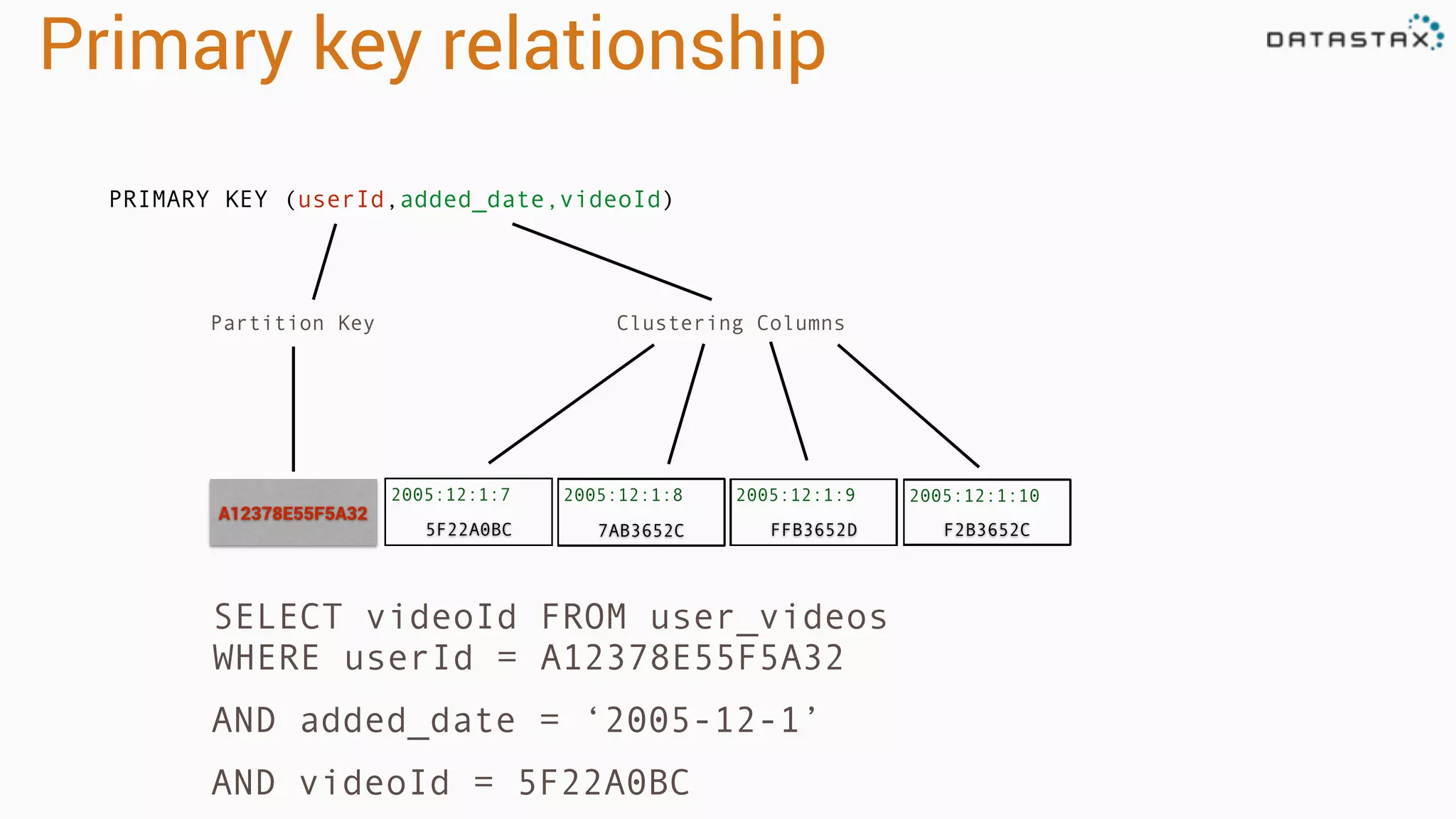










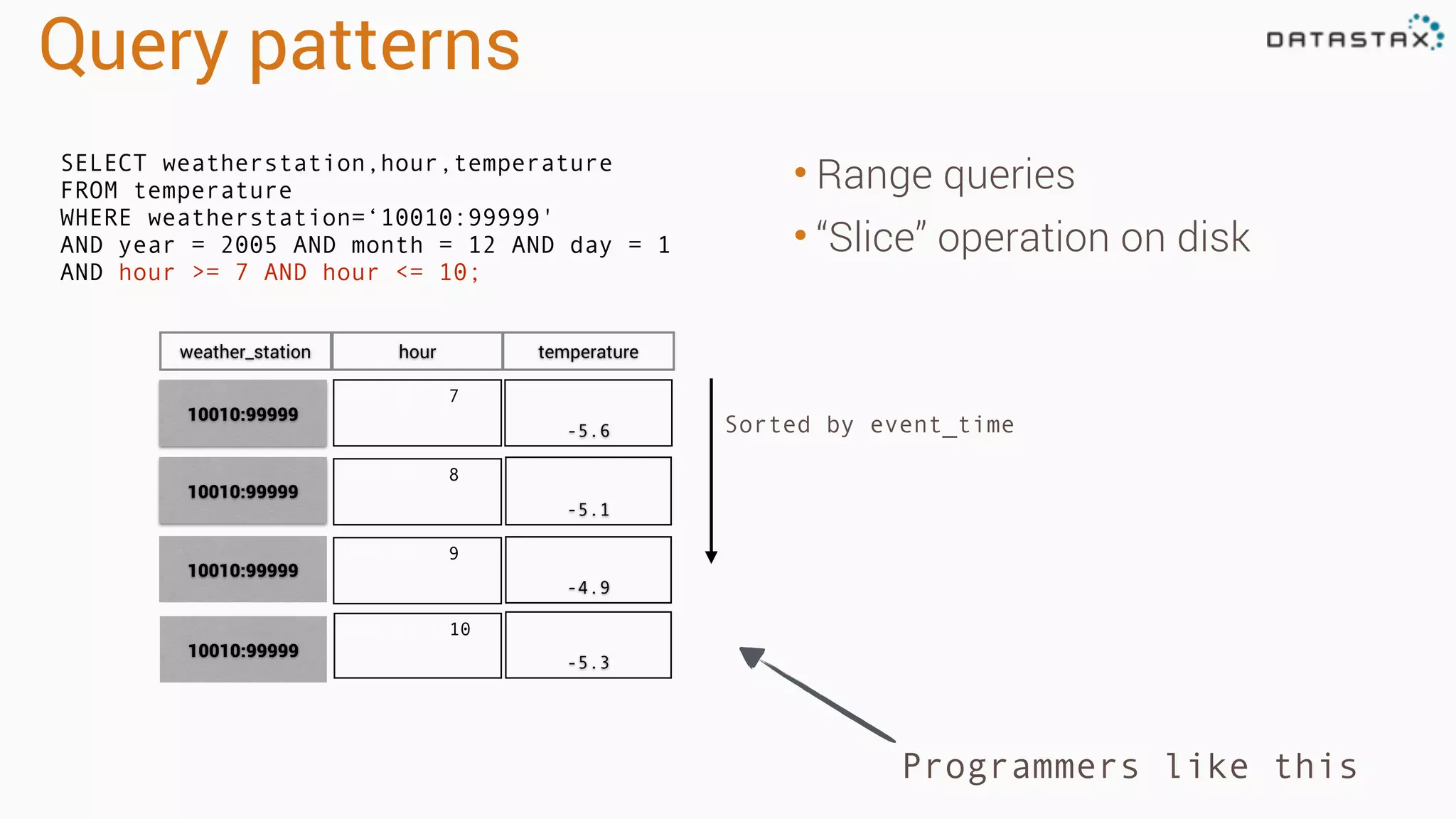

The document provides an introduction to data modeling with Apache Cassandra, highlighting key concepts such as ACID versus CAP principles, data modeling approaches, and the use of CQL. It discusses denormalization, entity tables, collections, and various query patterns to optimize data retrieval and storage. Examples are given, including the creation of tables for users, videos, and temperature data for a weather station, along with the corresponding queries and data structures.



































































![[BDD 2025 - Mobile Development] Exploring Apple’s On-Device FoundationModels](https://cdn.slidesharecdn.com/ss_thumbnails/md-exploringappleson-devicefoundationmodels-251124030840-d690542c-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)













![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)


