Downloaded 51 times










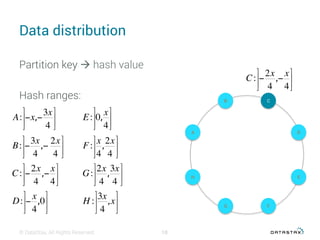
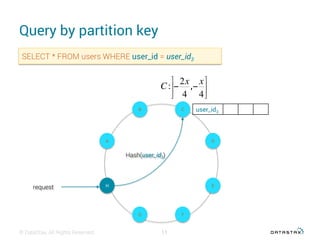

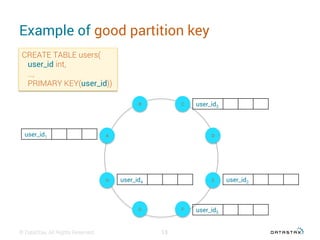
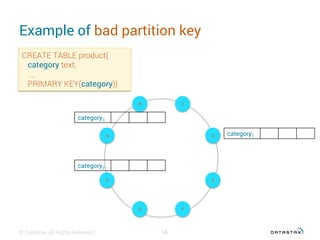




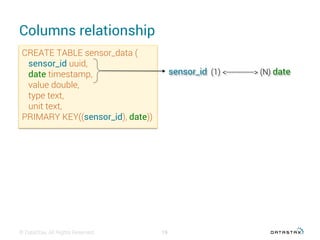
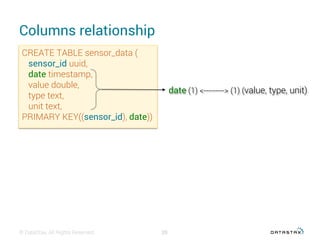
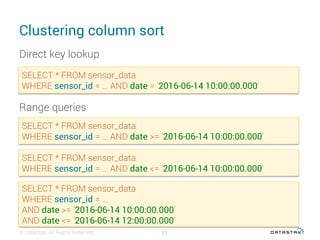








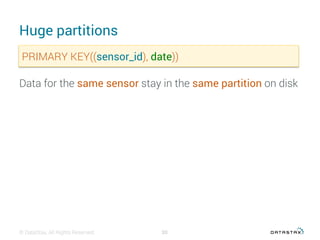








This document discusses data modeling with Apache Cassandra. It covers: 1. The objectives of data modeling like reducing query latency and avoiding disasters 2. Choosing the right partition key which is the main entry point for queries and helps distribute data 3. Using clustering columns to simulate one-to-many relationships and enable sorting and range queries 4. Other critical details like avoiding huge partitions, sub-partitioning techniques, and how deletes create tombstones




































































































