Downloaded 41 times










![In the beginning… there was RDD
sc = SparkContext(appName="PythonPi")
partitions = int(sys.argv[1]) if len(sys.argv) > 1 else 2
n = 100000 * partitions
def f(_):
x = random() * 2 - 1
y = random() * 2 - 1
return 1 if x ** 2 + y ** 2 < 1 else 0
count = sc.parallelize(range(1, n + 1), partitions).
map(f).reduce(add)
print("Pi is roughly %f" % (4.0 * count / n))
sc.stop()](https://image.slidesharecdn.com/pysparktalk-150923205538-lva1-app6892/85/Enter-the-Snake-Pit-for-Fast-and-Easy-Spark-12-320.jpg)




![Filtering
• Select specific rows matching
various patterns
• Fields do not require indexes
• Filtering occurs in memory
• You can use DSE Solr Search
Queries
• Filtering returns a DataFrame
movies.filter(movies.movie_id == 1)
movies[movies.movie_id == 1]
movies.filter("movie_id=1")
movie_id title genres
44 Mortal Kombat (1995)
['Action',
'Adventure',
'Fantasy']
movies.filter("title like '%Kombat%'")](https://image.slidesharecdn.com/pysparktalk-150923205538-lva1-app6892/85/Enter-the-Snake-Pit-for-Fast-and-Easy-Spark-19-320.jpg)

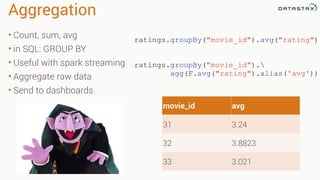
![Joins
• Inner join by default
• Can do various outer joins
as well
• Returns a new DF with all
the columns
ratings.join(movies, "movie_id")
DataFrame[movie_id: int,
user_id: int,
rating: decimal(10,0),
ts: int,
genres: array<string>,
title: string]](https://image.slidesharecdn.com/pysparktalk-150923205538-lva1-app6892/85/Enter-the-Snake-Pit-for-Fast-and-Easy-Spark-22-320.jpg)





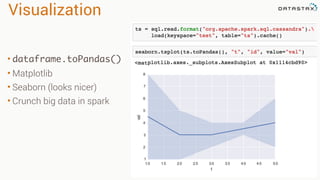


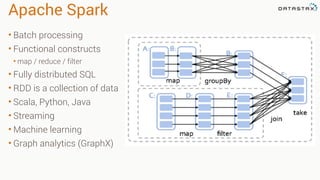
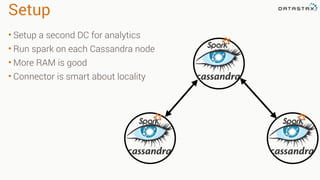
The document discusses the integration of Apache Cassandra with Apache Spark to enhance data processing capabilities, highlighting Cassandra's advantages such as fast data ingestion and linear scalability. It explains the challenges of using Cassandra in areas like ad hoc querying and analytics, and showcases Spark's features including batch processing and machine learning for better data management. The document also provides code examples and techniques for filtering, aggregating, and migrating data between databases.























































































