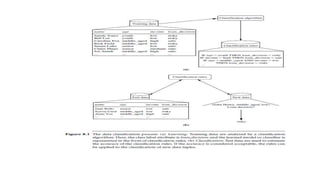
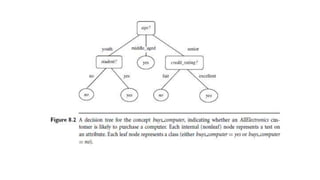
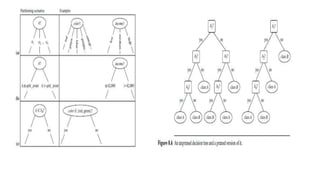
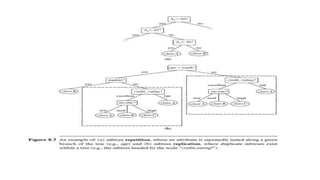
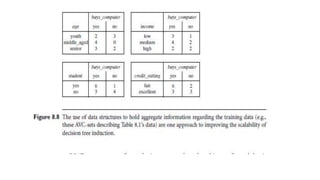
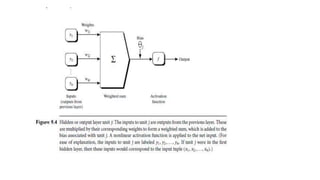
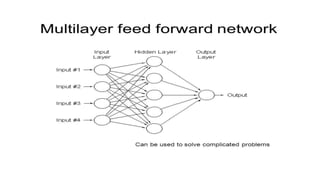
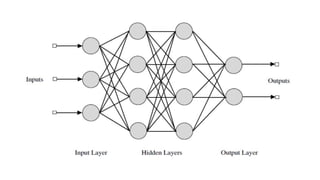
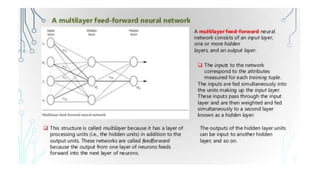
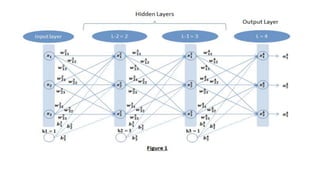
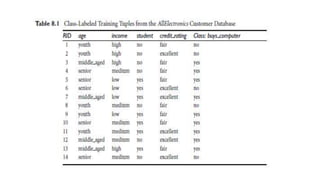
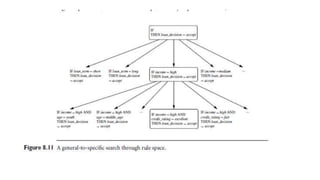
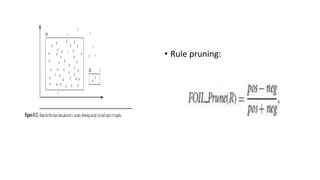
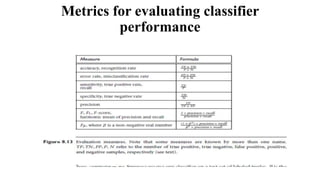
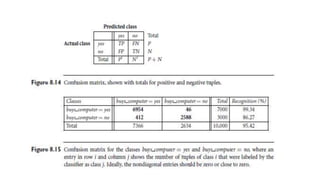
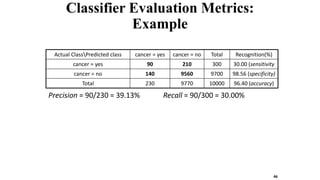
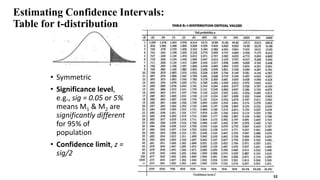
This document discusses various techniques for data classification including decision tree induction, Bayesian classification methods, rule-based classification, and classification by backpropagation. It covers key concepts such as supervised vs. unsupervised learning, training data vs. test data, and issues around preprocessing data for classification. The document also discusses evaluating classification models using metrics like accuracy, precision, recall, and F-measures as well as techniques like holdout validation, cross-validation, and bootstrap.