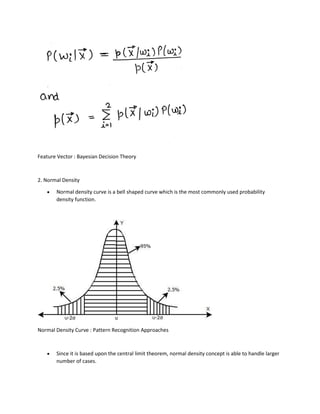
The document provides an in-depth overview of pattern recognition, focusing on its components, applications, and methods of learning such as supervised, unsupervised, and reinforcement learning. It elaborates on statistical and structural approaches to pattern recognition, discussing various techniques like Bayesian decision theory and Gaussian mixture models, along with parameter estimation methods such as maximum likelihood estimation and expectation maximization. Additionally, the document addresses non-parametric techniques like density estimation and outlines practical applications in fields such as image processing, speech recognition, and medical diagnosis.