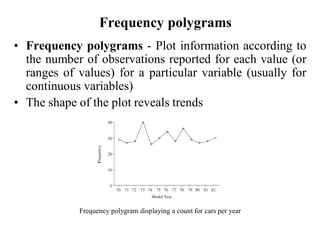
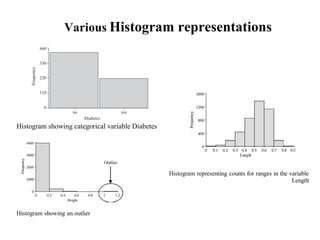
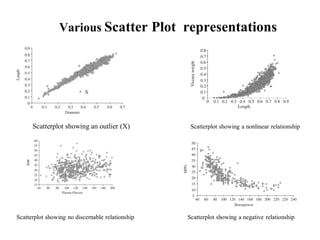
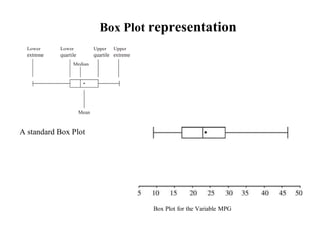
This document defines key concepts in data mining tasks and knowledge representation. It discusses (1) task relevant data, background knowledge, interestingness measures, input/output representation, and visualization techniques used in data mining; (2) examples of concept hierarchies like schema, set-grouping, and rule-based hierarchies; and (3) common visualization techniques like histograms, scatterplots, and box plots used to analyze and present data mining results.