
Downloaded 15 times













![20
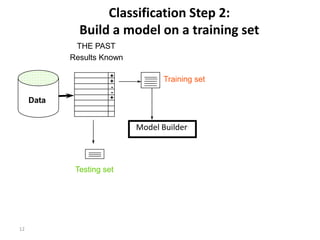
Confidence intervals
• p: A true (but unknown) success rate
• We can say: p lies within a certain specified interval with a certain
specified confidence
• Example: S=750 successes in N=1000 trials
– Estimated success rate: 75%(observed success rate is f = S/N)
– How close is this to true success rate p?
• Answer: with 80% confidence p[73.2,76.7]
• Another example: S=75 and N=100
– Estimated success rate: 75%
– With 80% confidence p[69.1,80.1]](https://image.slidesharecdn.com/1-evaluationandcredibility-160904080825/85/evaluation-and-credibility-Part-1-20-320.jpg)
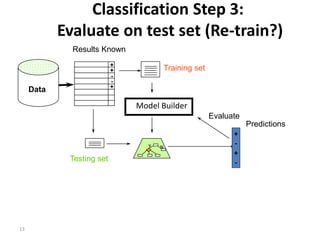
![21
Mean and Variance
• Mean and variance for a Bernoulli trial:
p, p (1–p)
• Expected success rate f=S/N
• Mean and variance for f : p, p (1–p)/N
• For large enough N, f follows a Normal distribution
• c% confidence interval [–z X z] for random variable
with 0 mean is given by:
• With a symmetric distribution:
czXz =££- ]Pr[
]Pr[21]Pr[ zXzXz ³´-=££-](https://image.slidesharecdn.com/1-evaluationandcredibility-160904080825/85/evaluation-and-credibility-Part-1-21-320.jpg)
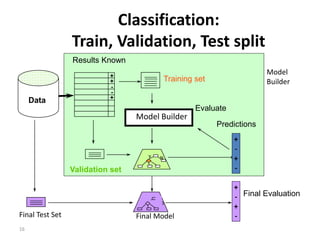
![22
Confidence limits
• Confidence limits for the normal distribution with 0 mean and a
variance of 1:
• Thus:
• To use this we have to reduce our random variable f to have 0
mean and unit variance
Pr[X z] z
0.1% 3.09
0.5% 2.58
1% 2.33
5% 1.65
10% 1.28
20% 0.84
40% 0.25
%90]65.165.1Pr[ =££- X
–1 0 1 1.65
Pr[X ≥ z] = 5% implies that there is a 5% chance that X lies
more than 1.65 standard deviations above the mean.](https://image.slidesharecdn.com/1-evaluationandcredibility-160904080825/85/evaluation-and-credibility-Part-1-22-320.jpg)

![24
Examples
• f = 75%, N = 1000, c = 80% (so that z = 1.28):
• f = 75%, N = 100, c = 80% (so that z = 1.28):
• Note that normal distribution assumption is only valid for large N (i.e. N >
100)
• f = 75%, N = 10, c = 80% (so that z = 1.28):
(should be taken with a grain of salt)
]767.0,732.0[Îp
]801.0,691.0[Îp
]881.0,549.0[Îp](https://image.slidesharecdn.com/1-evaluationandcredibility-160904080825/85/evaluation-and-credibility-Part-1-24-320.jpg)











This document discusses various methods for evaluating machine learning models. It describes splitting data into training, validation, and test sets to evaluate models on large datasets. For small or unbalanced datasets, it recommends cross-validation techniques like k-fold cross-validation and stratified sampling. The document also covers evaluating classifier performance using metrics like accuracy, confidence intervals, and lift charts, as well as addressing issues that can impact evaluation like overfitting and class imbalance.























































































