Downloaded 149 times








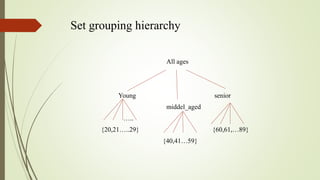






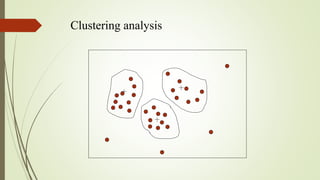




This document discusses task relevant data, discretization, and concept hierarchies in data mining. It defines task relevant data as the portions of a database or data set of interest to a user, including relevant attributes, dimensions, and selection criteria. Discretization reduces continuous attribute values to intervals, while concept hierarchies group low-level concepts into higher-level generalized concepts. Methods for generating concept hierarchies include binning, histogram analysis, clustering analysis, and analyzing attribute distinct values.























































































