Download as PDF, PPTX






![Research ethics
committees (RECs) review
the ethical acceptability of
research involving human
participants. Historically,
the principal emphases of
RECs have been to protect
participants from physical
harms and to provide
assurance as to
participants’ interests and
welfare.*
[The Framework] is
guided by, Article 27 of
the 1948 Universal
Declaration of Human
Rights. Article 27
guarantees the rights
of every individual in
the world "to share in
scientific advancement
and its benefits"
(including to freely
engage in responsible
scientific inquiry)…*
Protect patients
The right of
patients to benefit
from research.
*GA4GH Framework for Responsible Sharing of Genomic and Health-Related Data, see goo.gl/CTavQR
Data sharing with protections provides the evidence
so patients can benefit from advances in research.
Data commons balance protecting patient data with open
research that benefits patients:](https://image.slidesharecdn.com/amia-webinar-2018-180122225750/75/How-Data-Commons-are-Changing-the-Way-that-Large-Datasets-Are-Analyzed-and-Shared-7-2048.jpg)
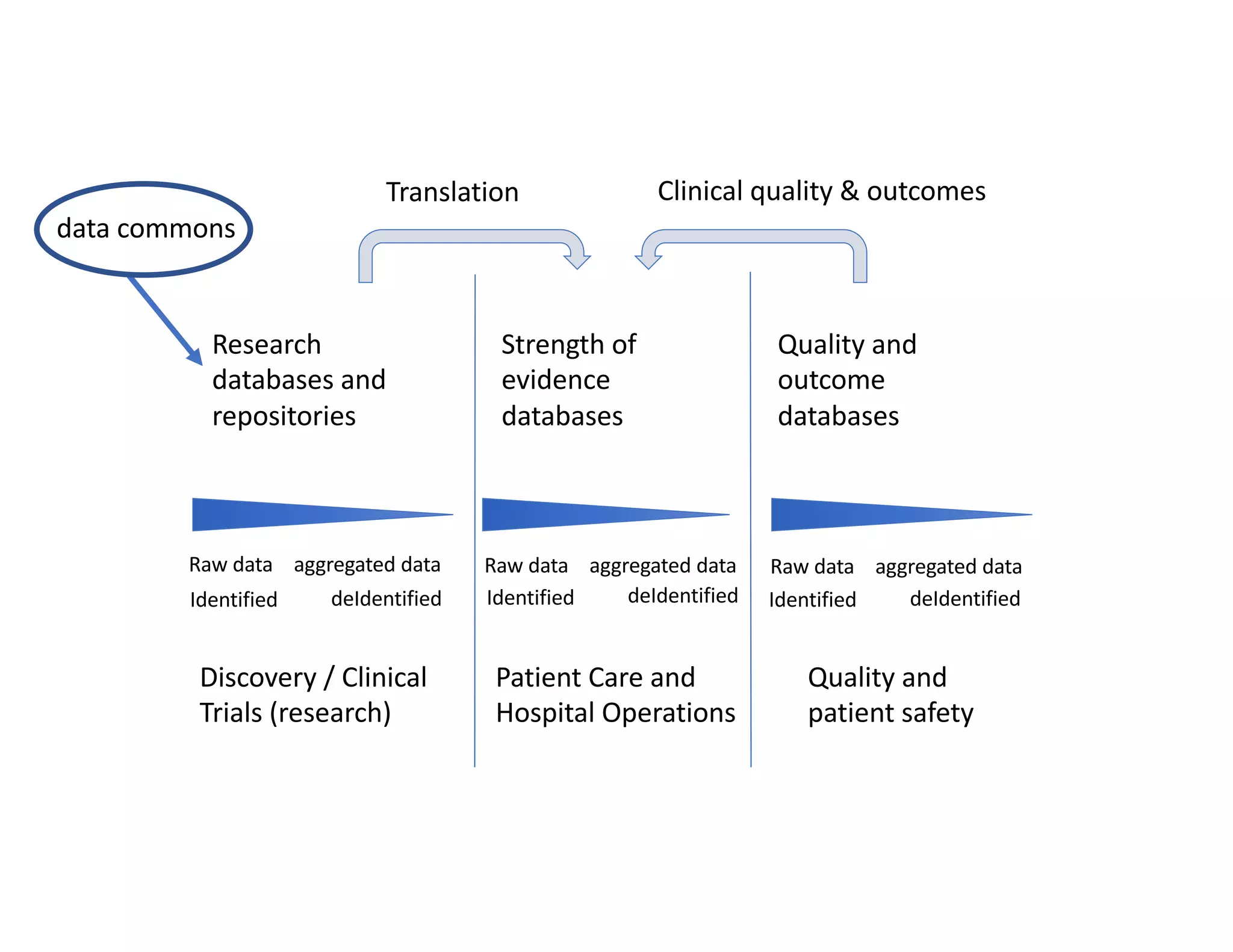

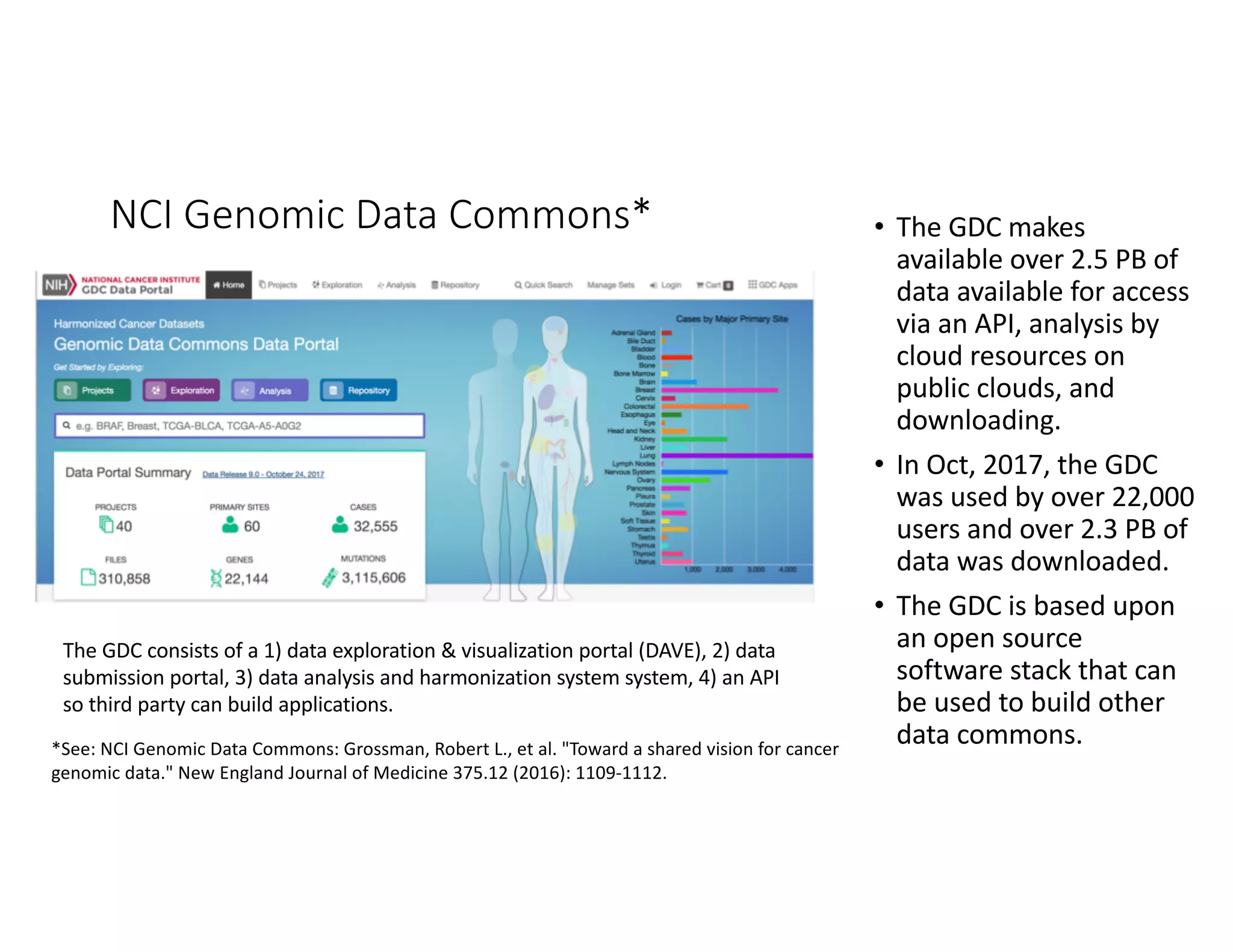
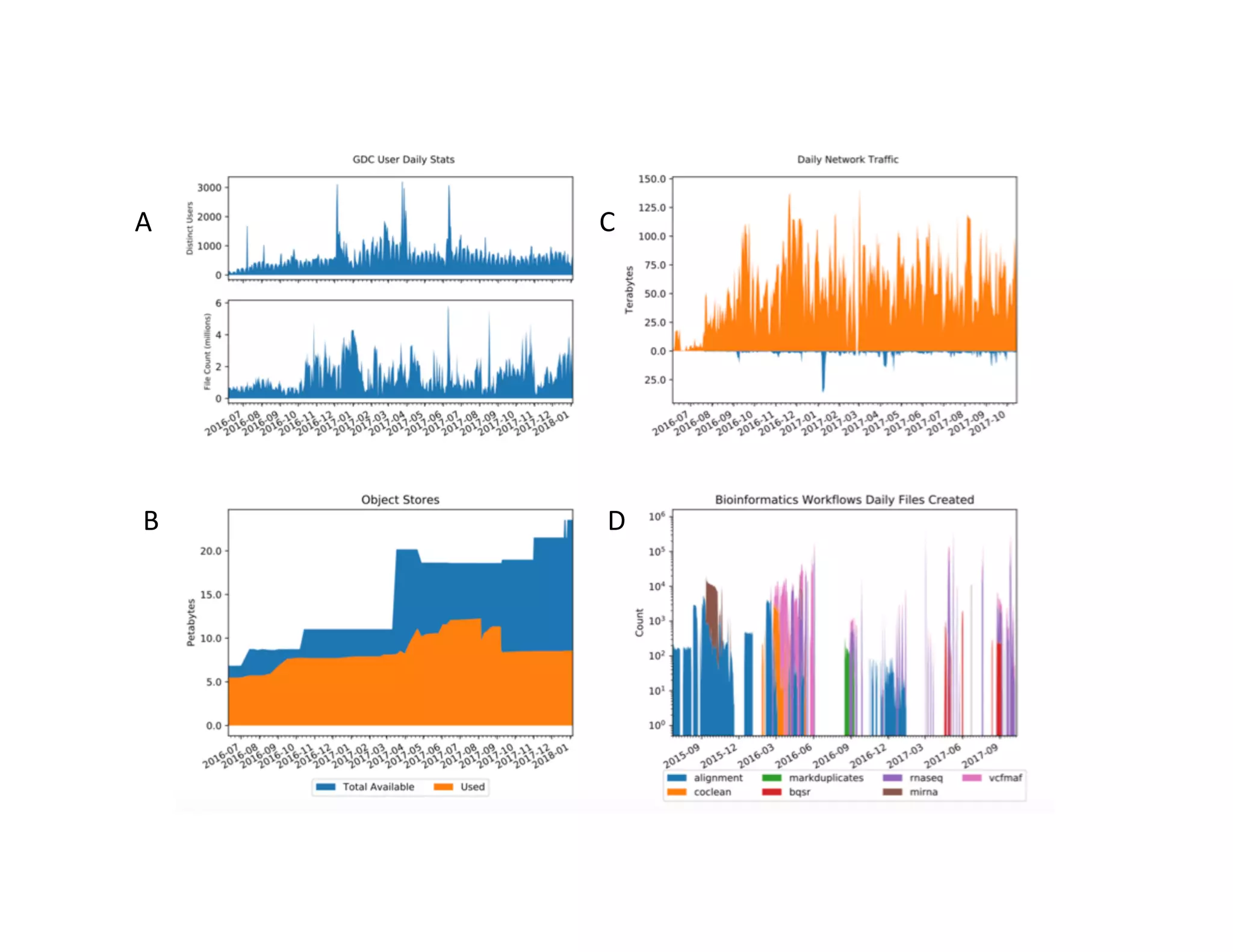
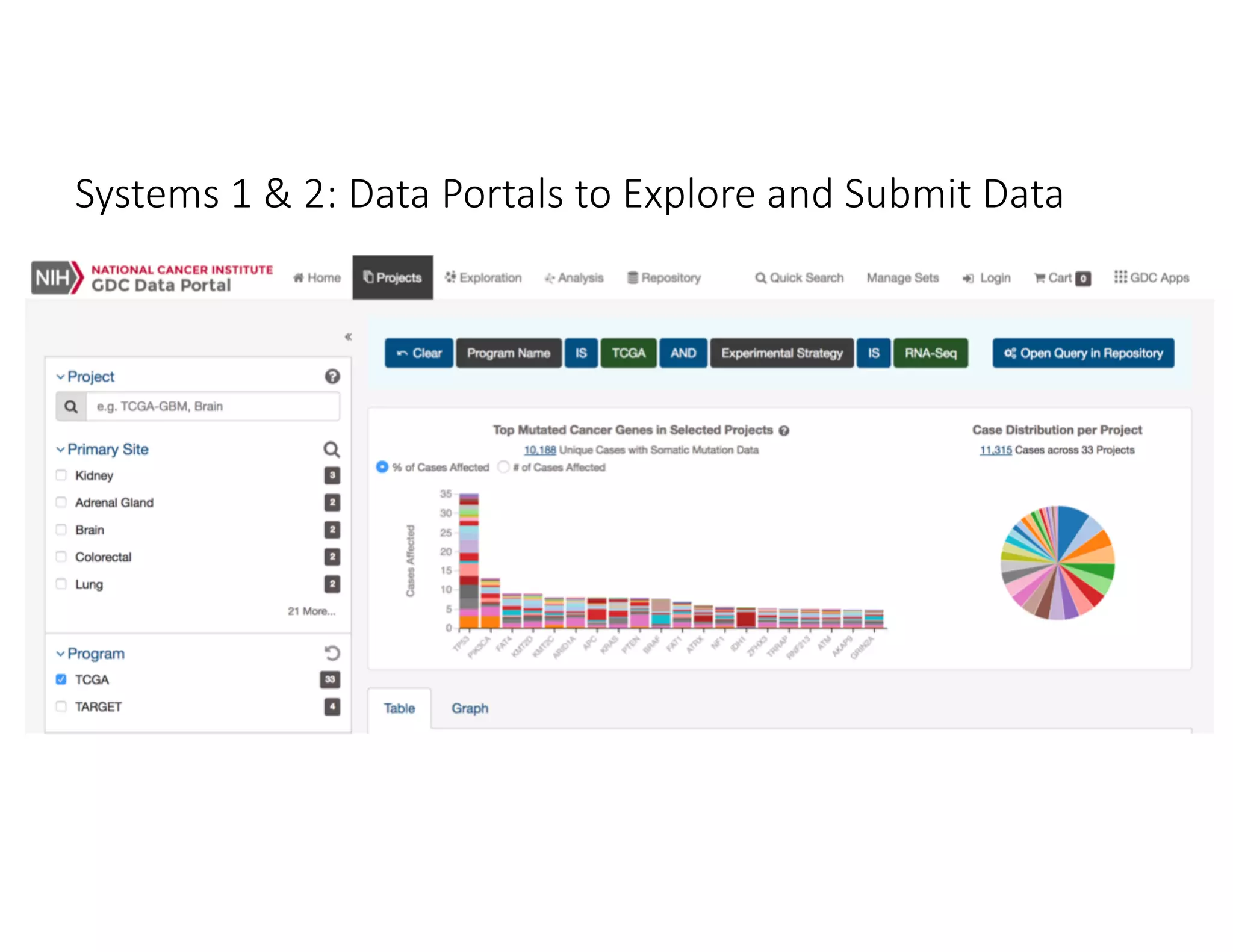
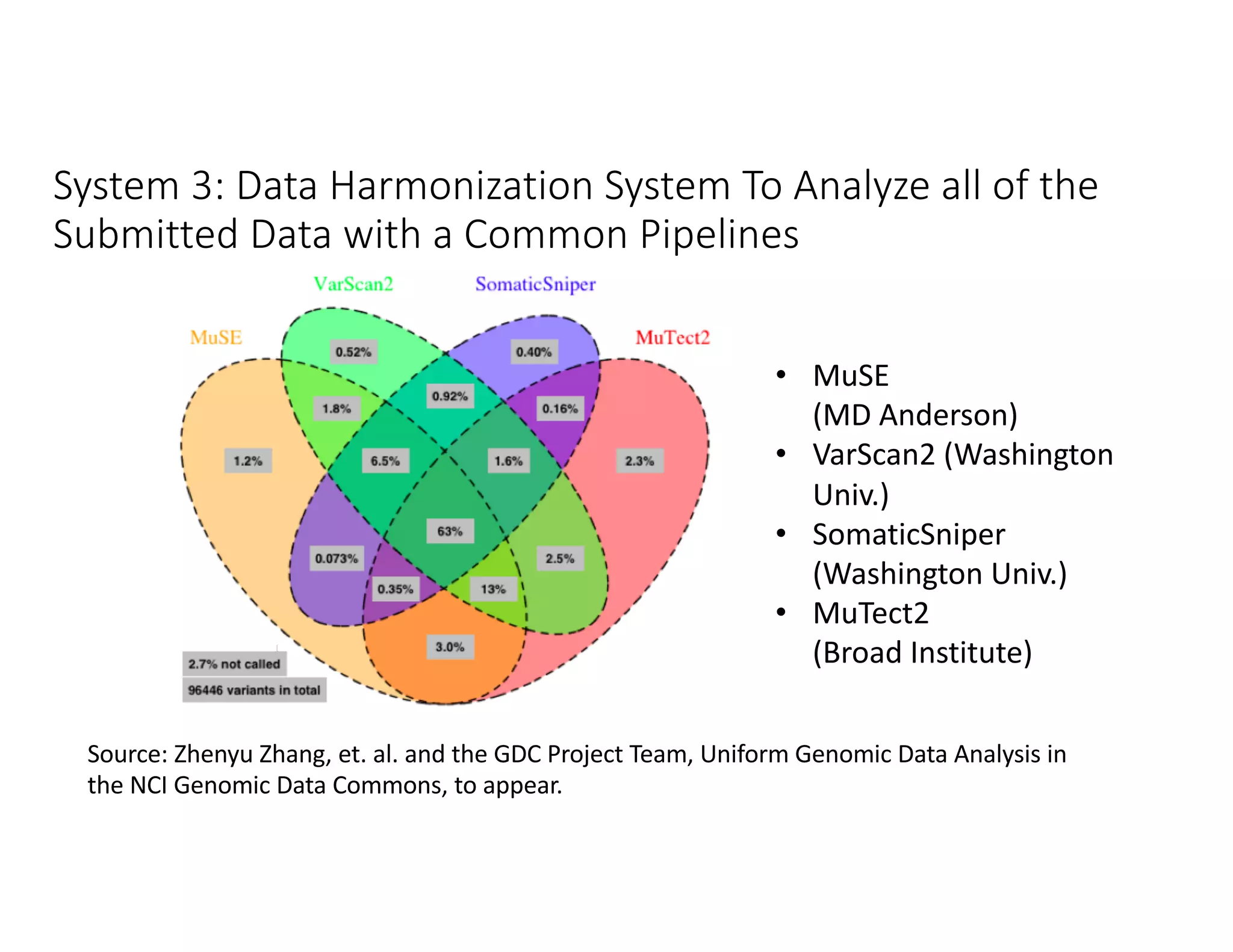


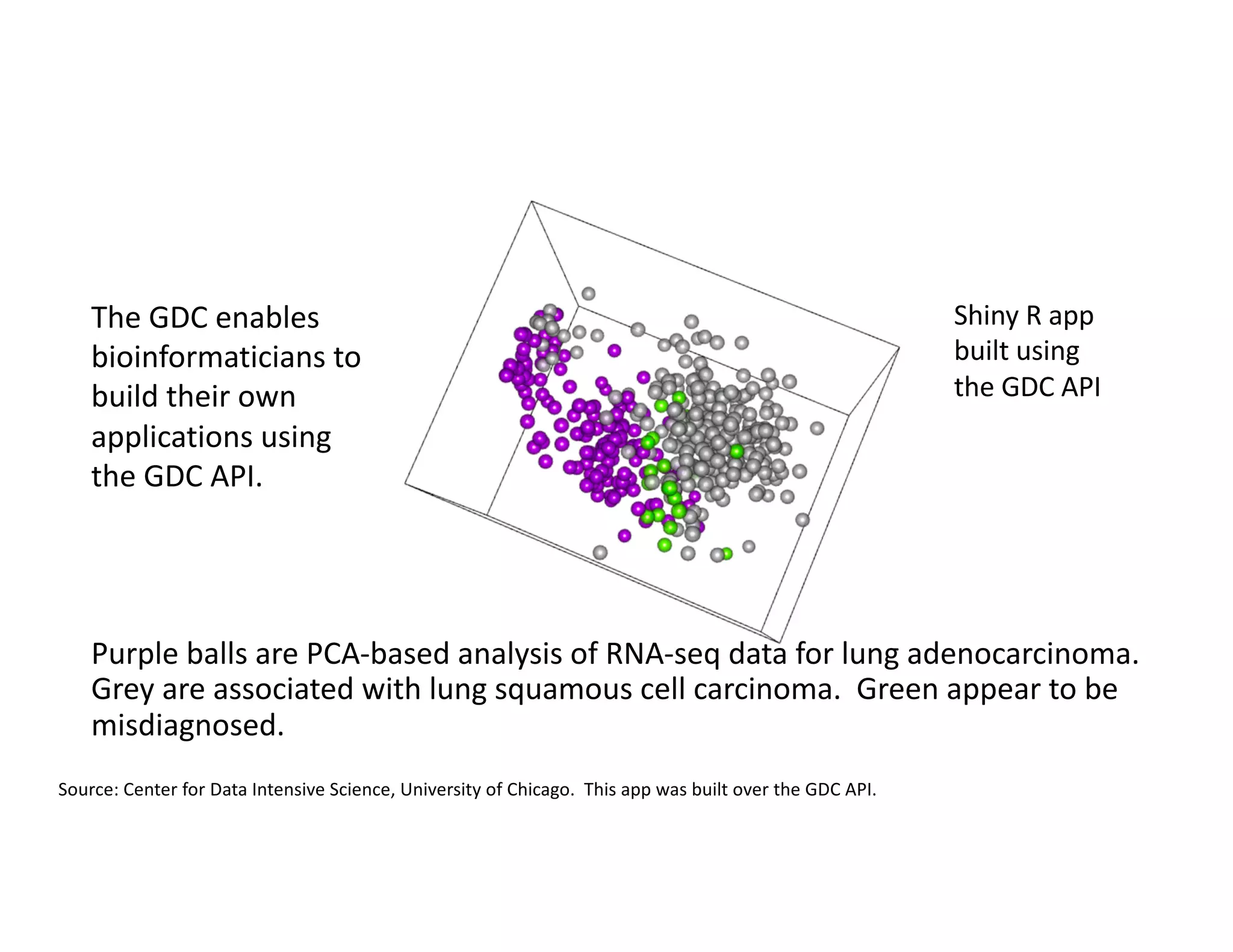

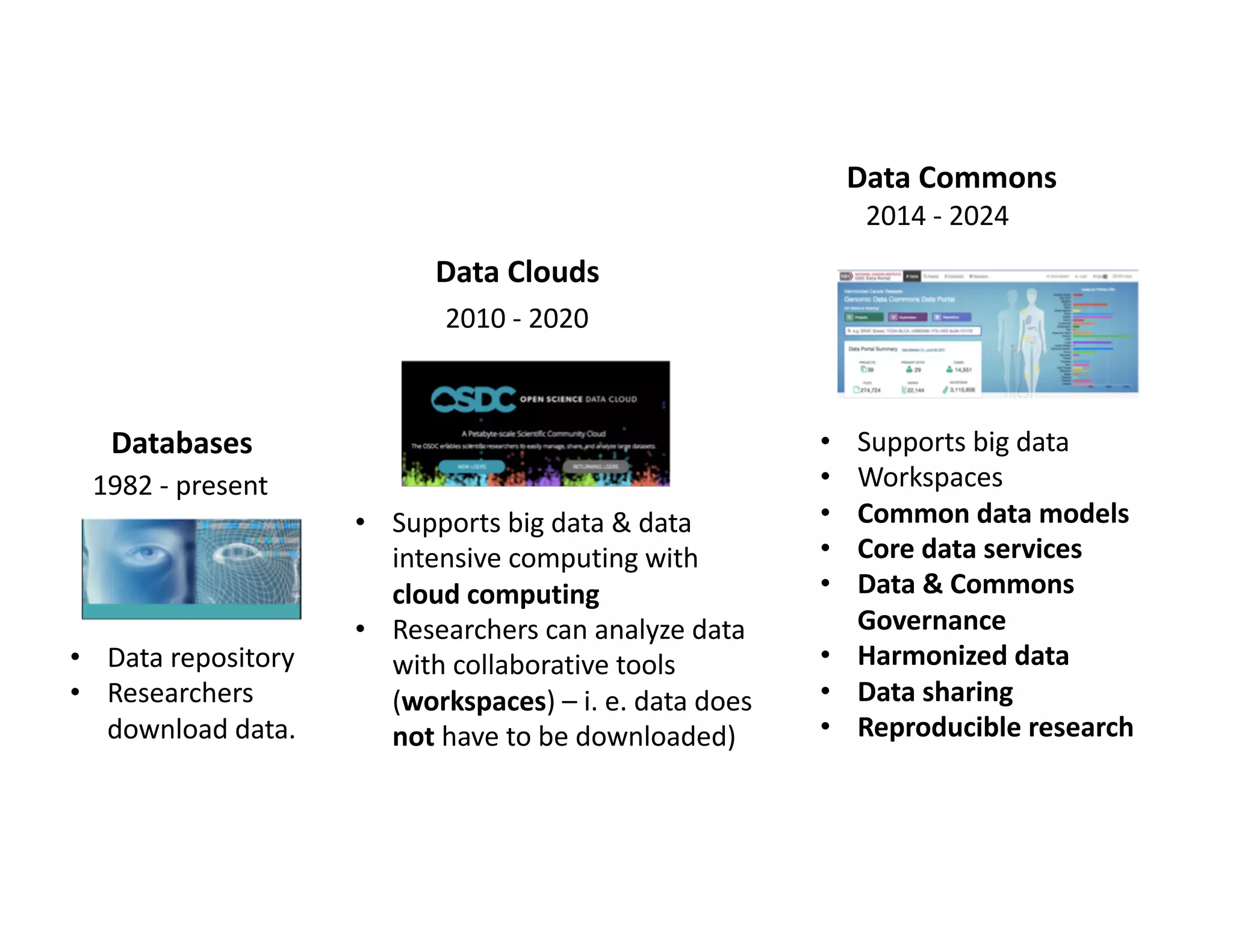
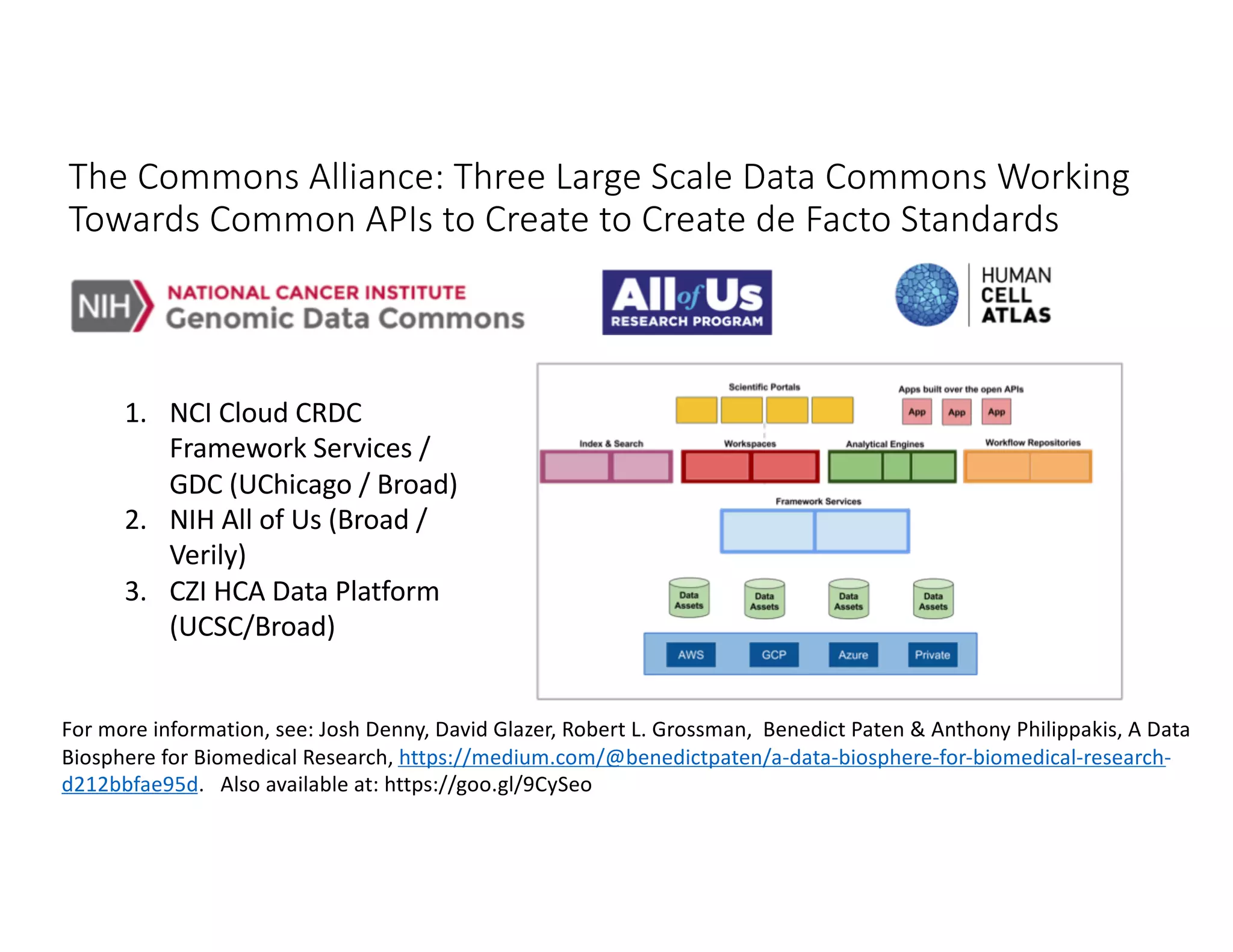
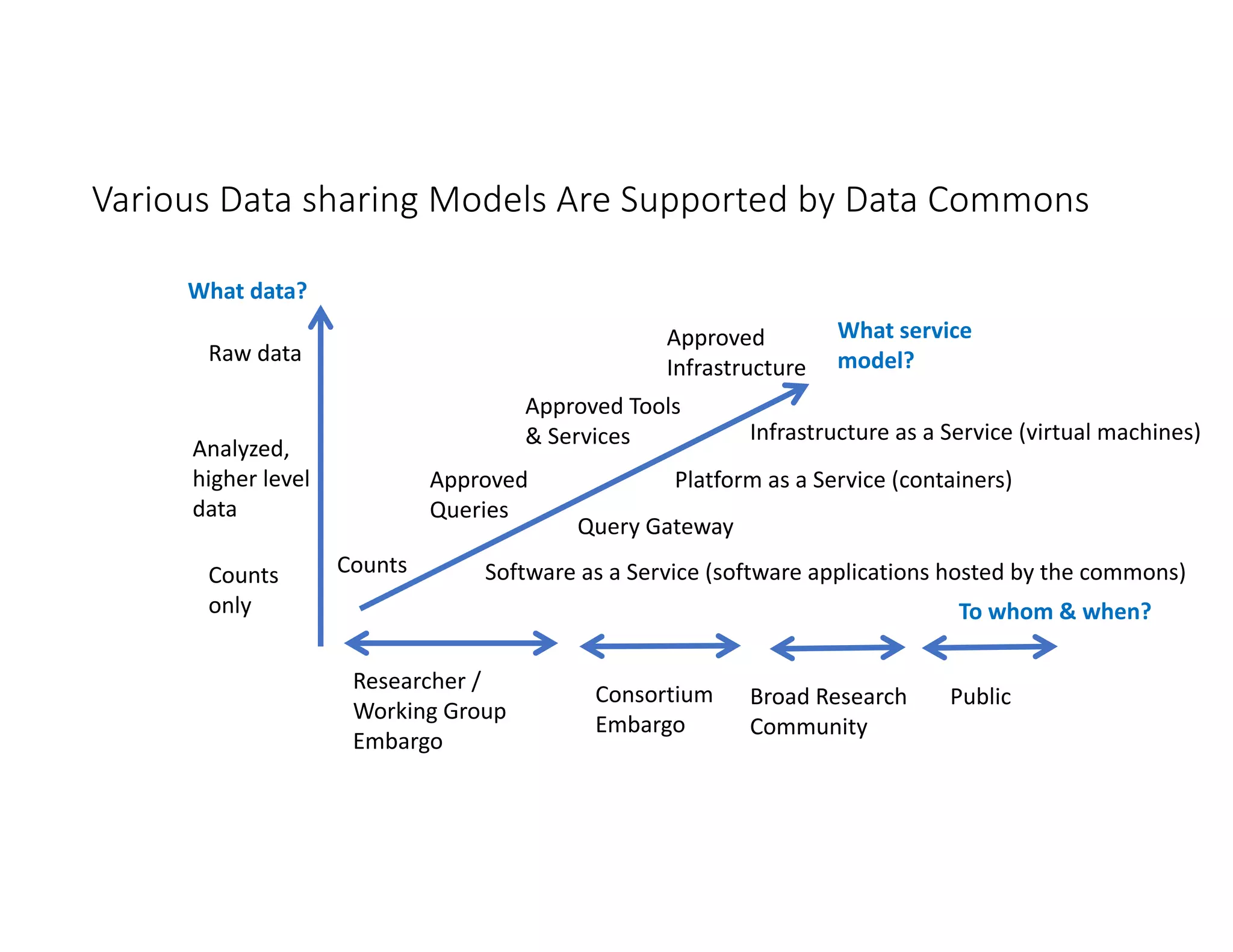



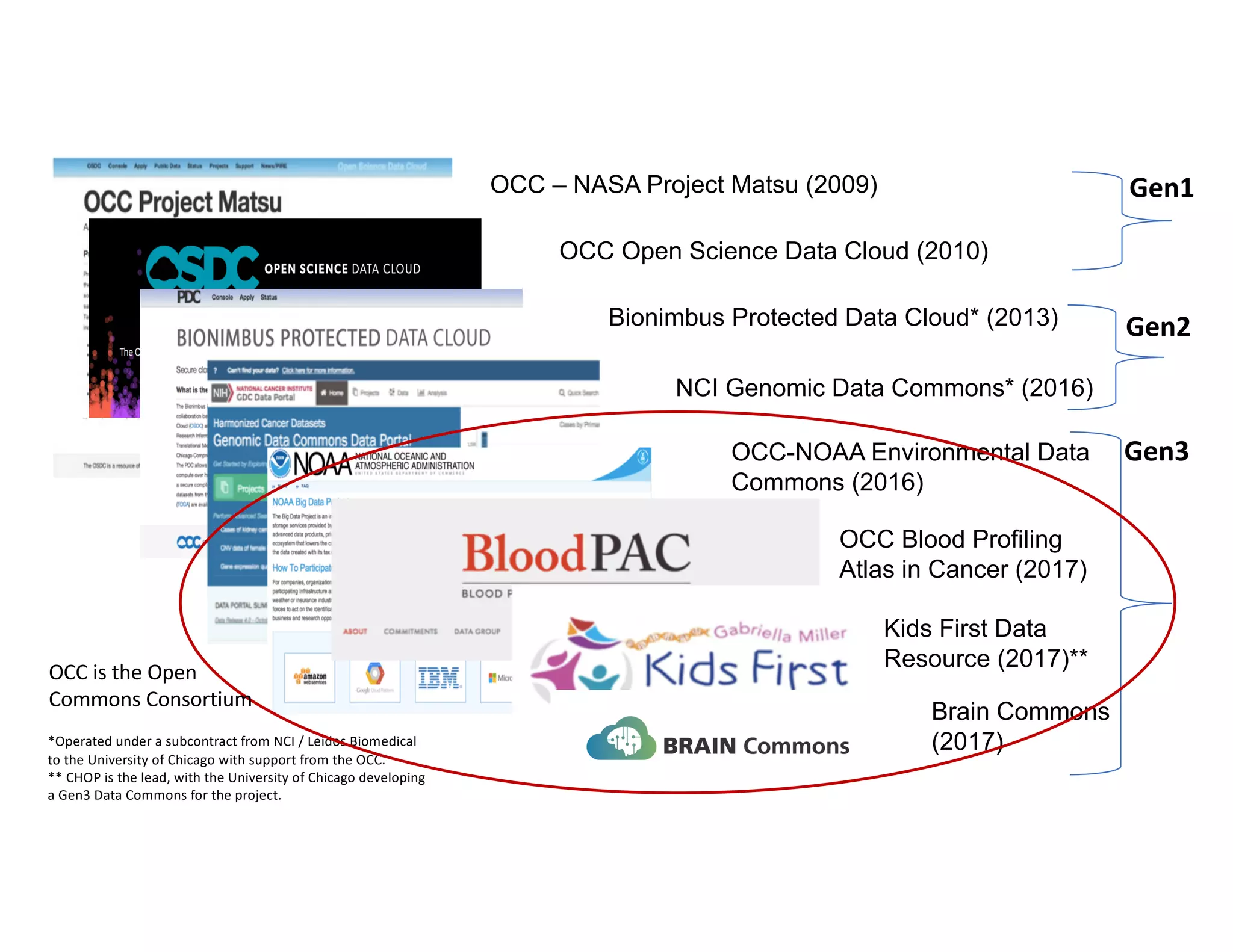

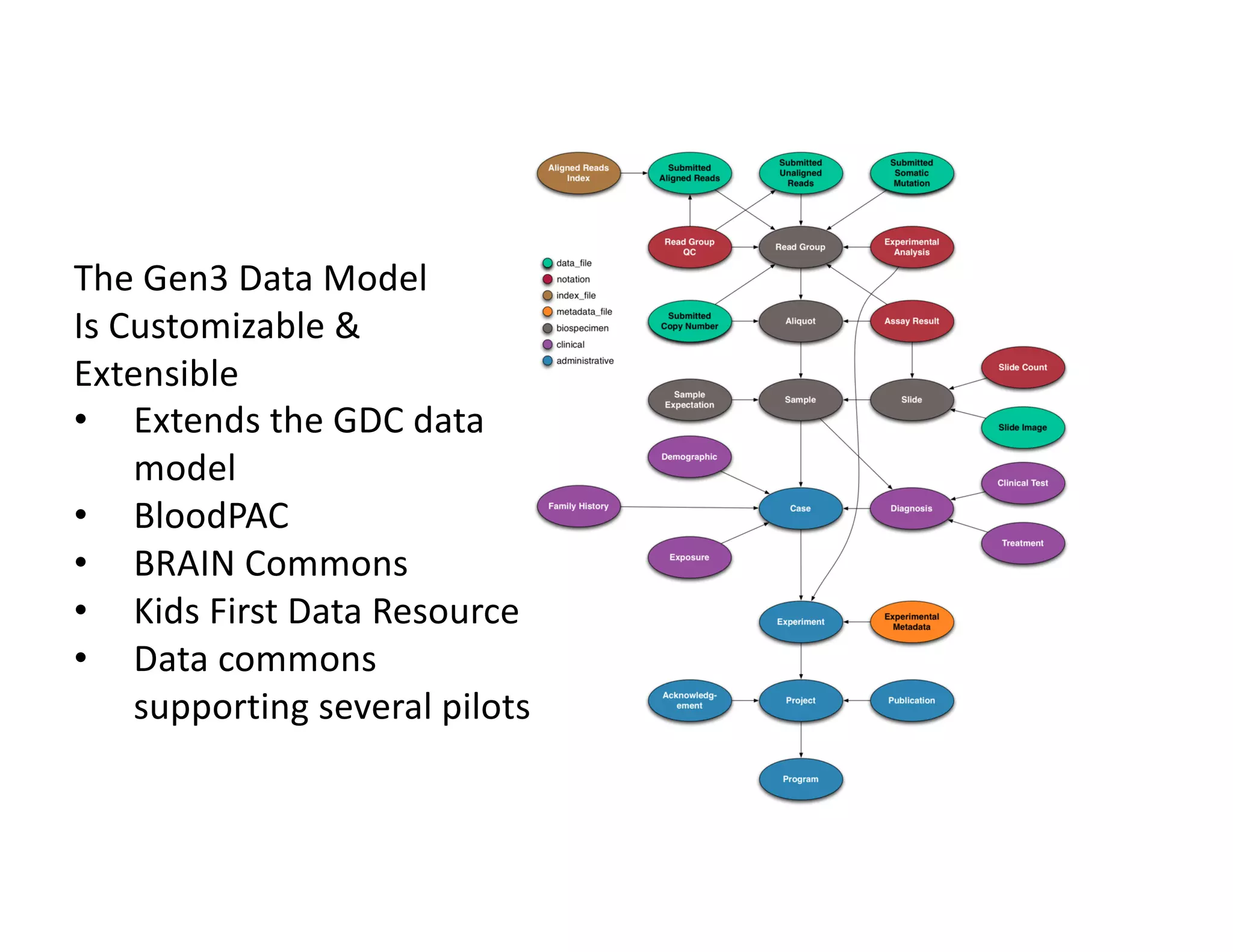
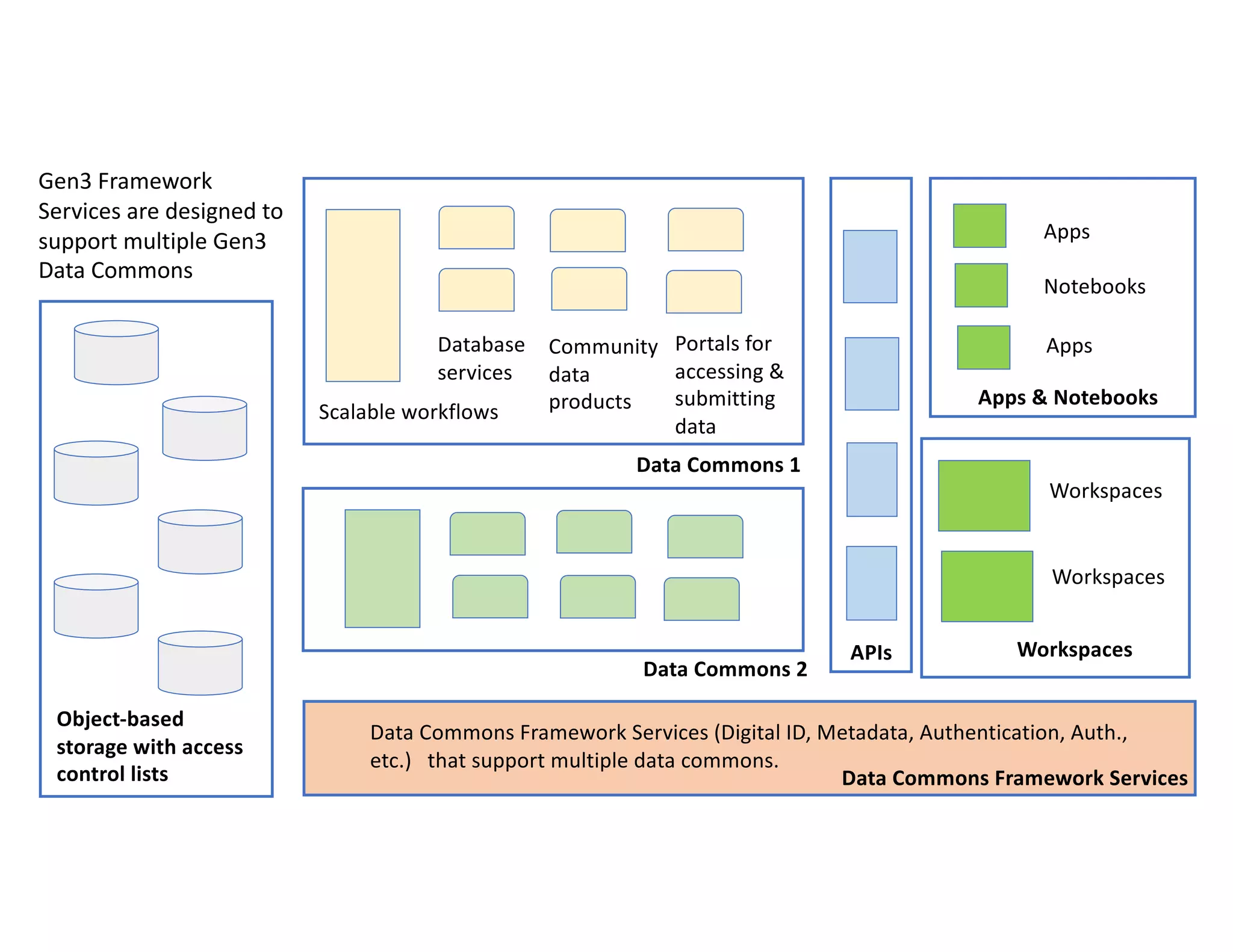

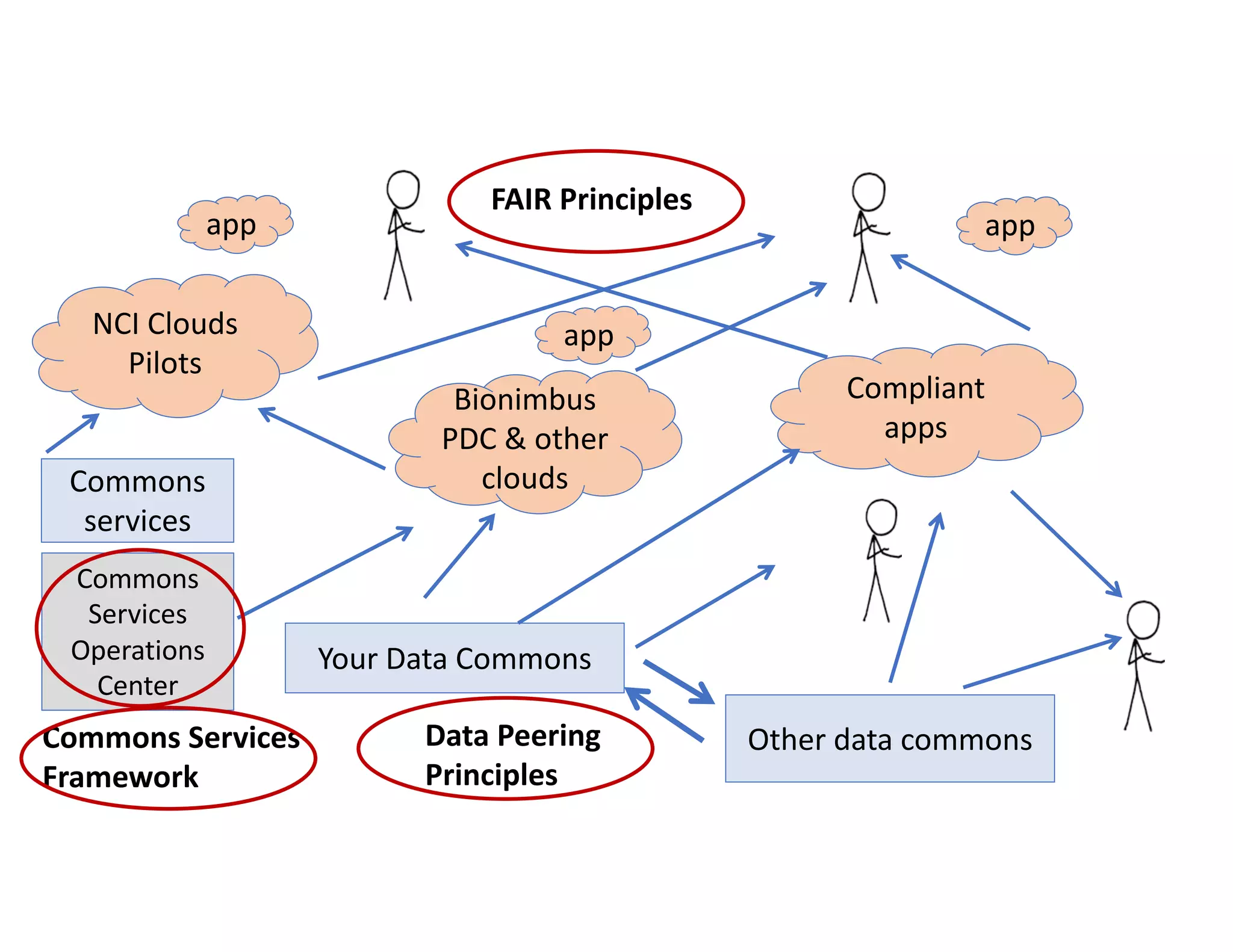
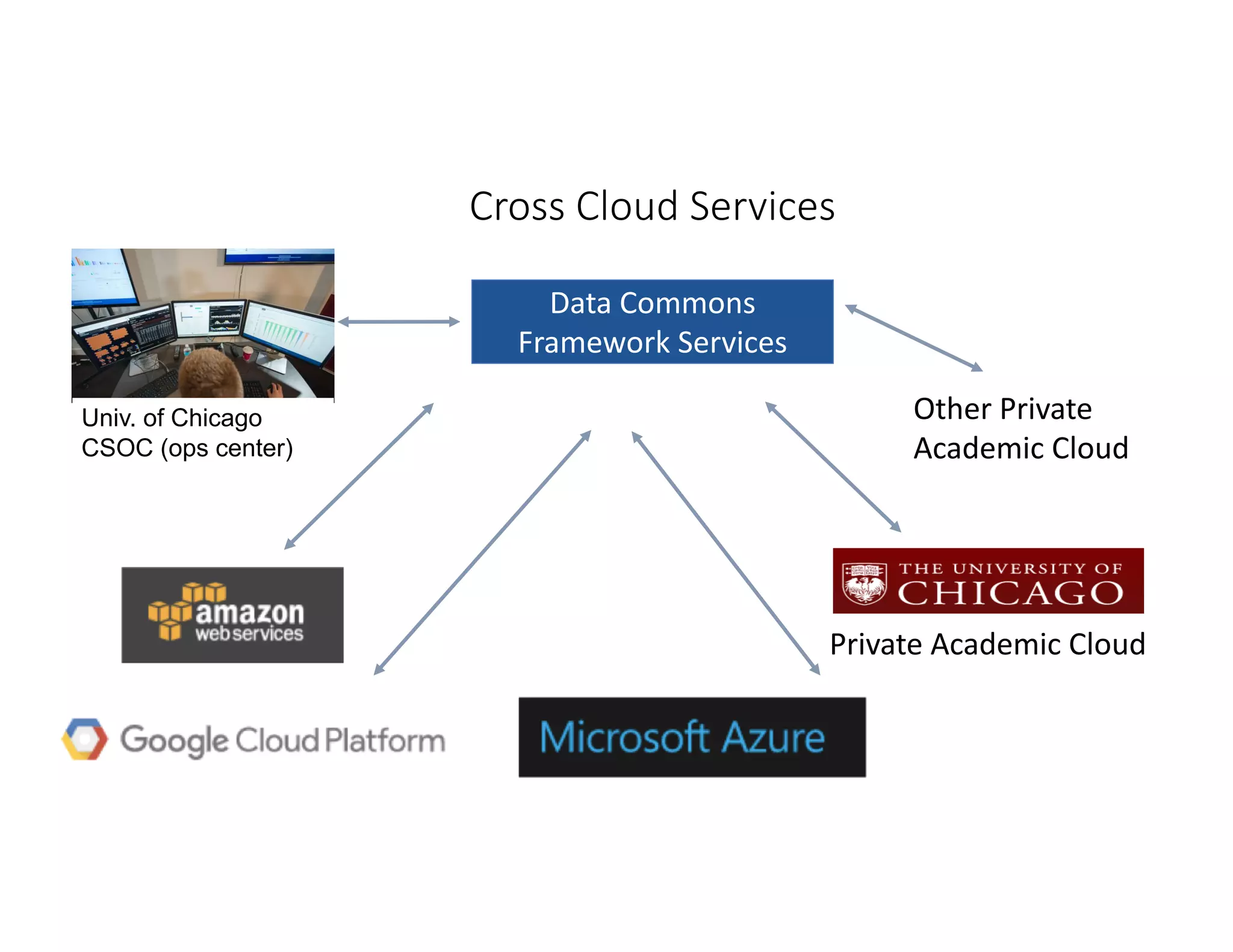


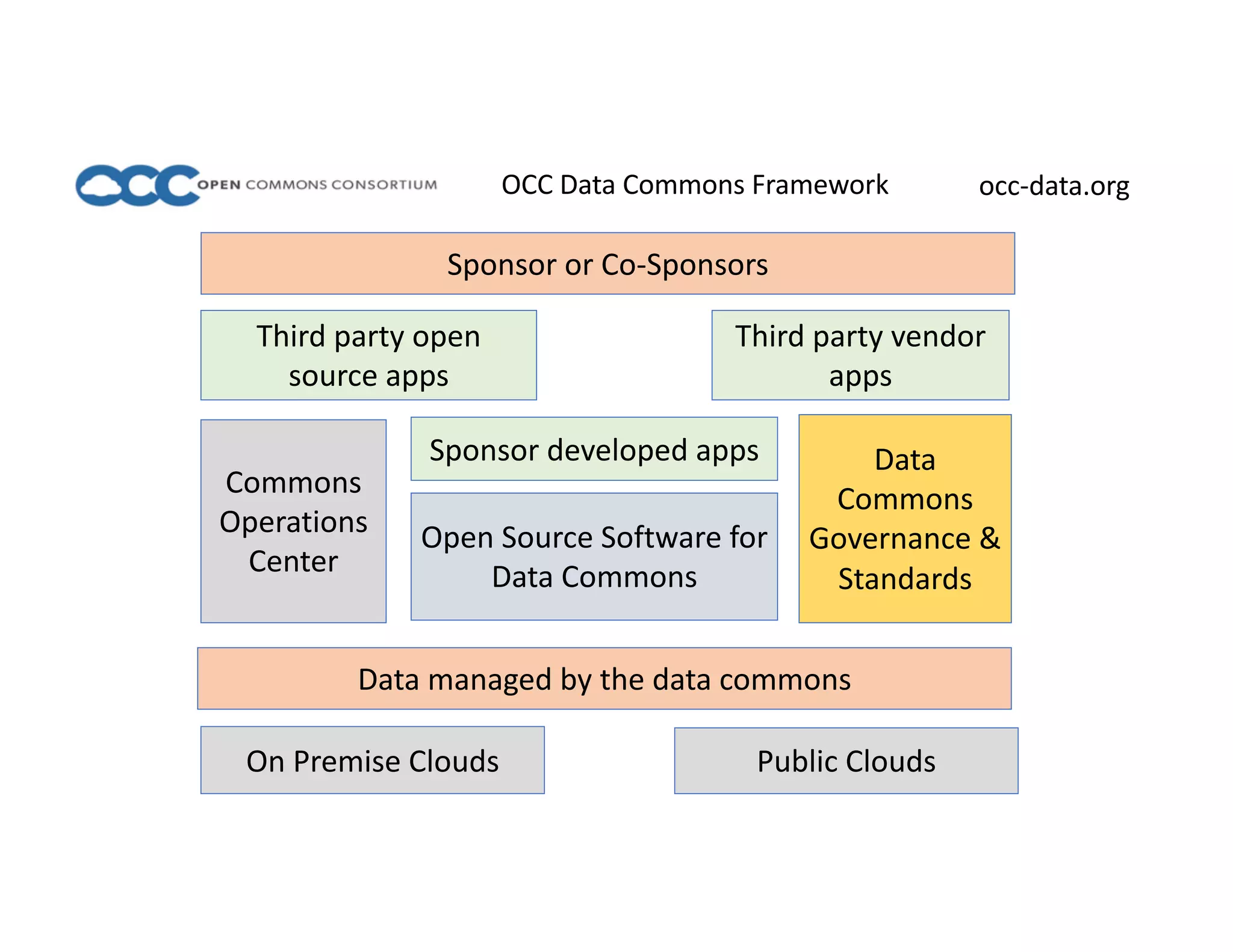
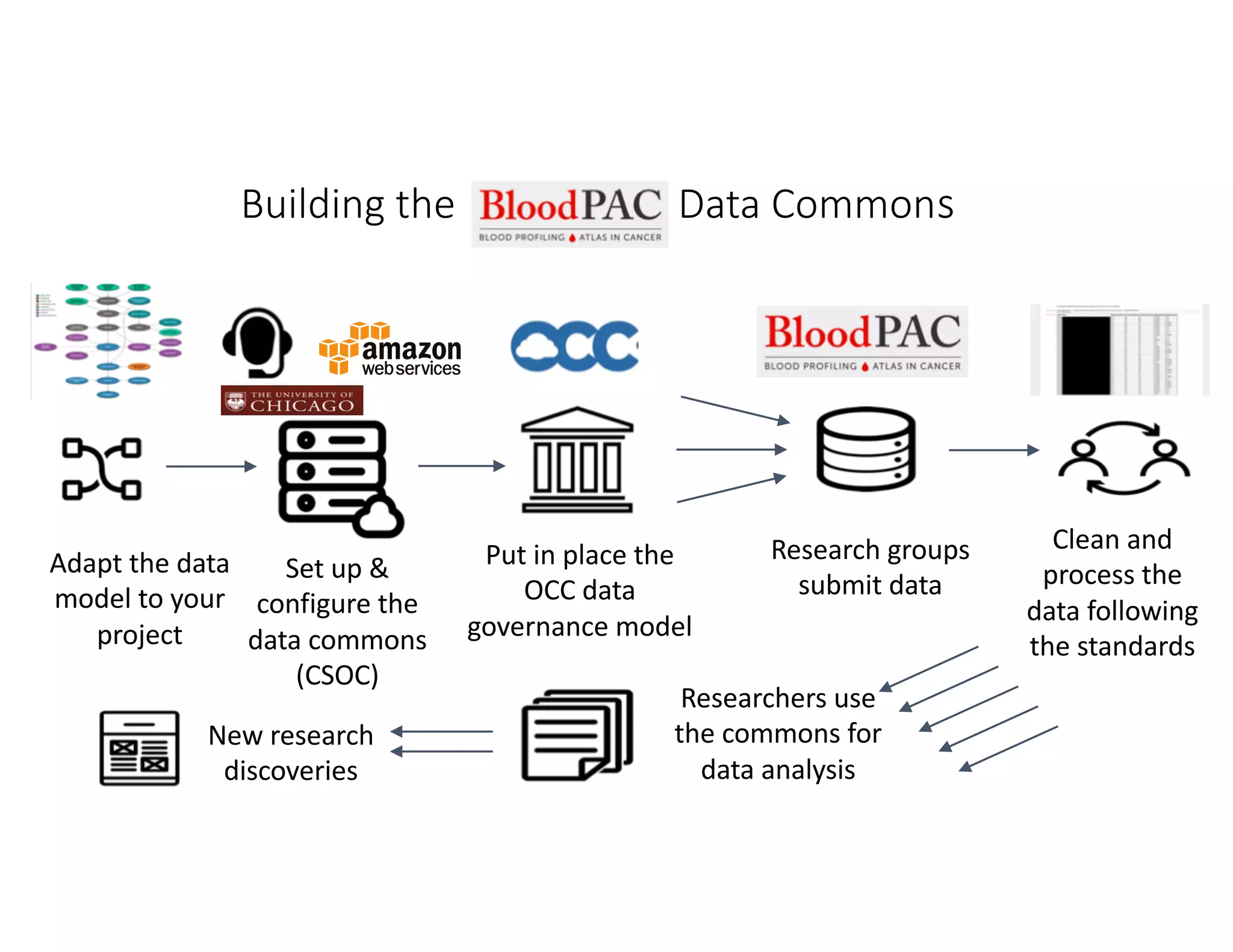



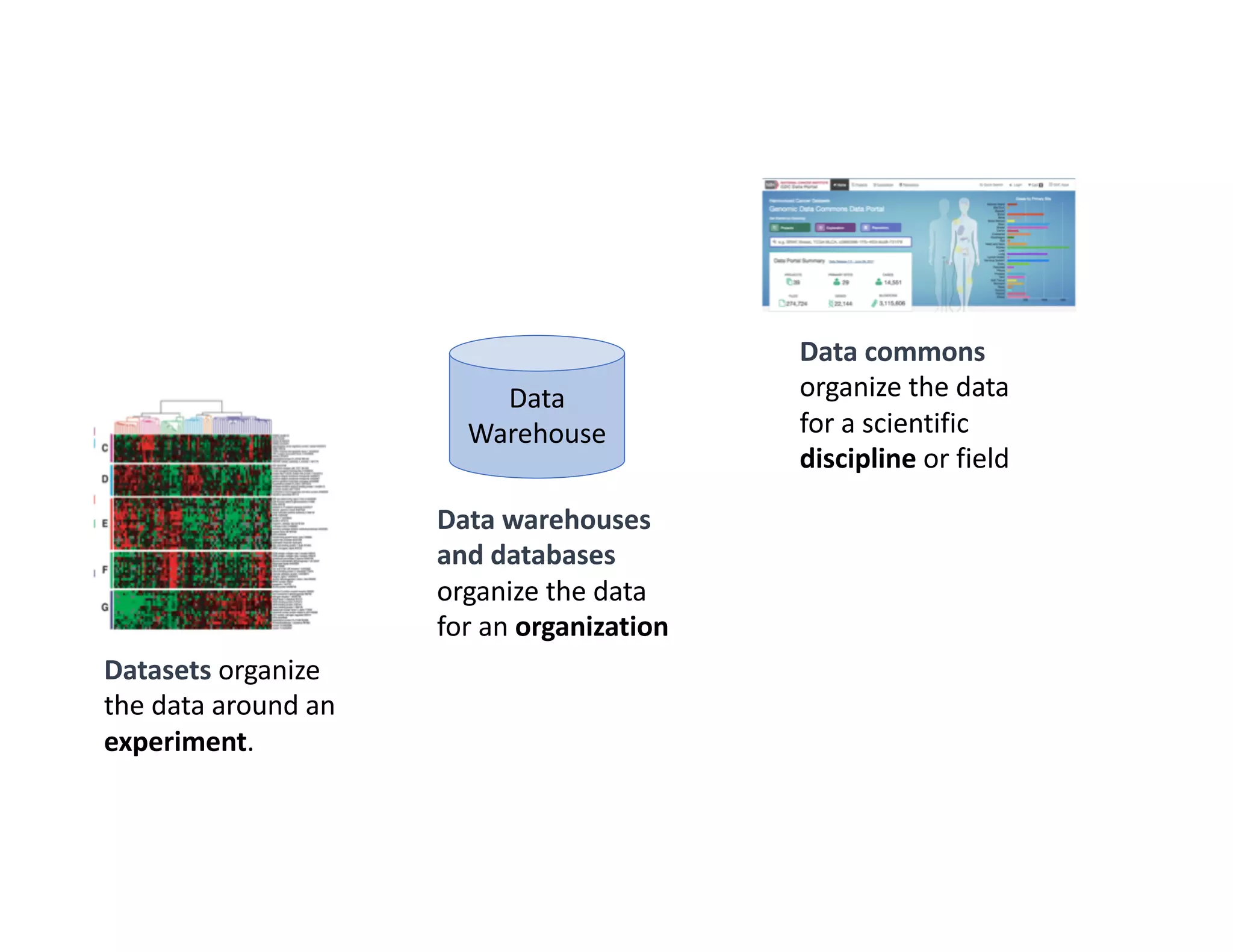





Data commons are emerging as a solution to challenges in analyzing and sharing large biomedical datasets. A data commons co-locates data with cloud computing infrastructure and software tools to create an interoperable resource for the research community. Examples include the NCI Genomic Data Commons and the Open Commons Consortium. The open source Gen3 platform supports building disease- or project-specific data commons to facilitate open data sharing while protecting patient privacy. Developing interoperable data commons can accelerate research through increased access to data.





































































![[DSC Europe 25] Bogdan Daniel Maruneac - AI - It starts with you.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/odov3snhrcqs9hx5ny2n-4-251205085715-f1daacfe-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Dusan Jovicic - AI Story: From on-prem to cloud and back agai...](https://cdn.slidesharecdn.com/ss_thumbnails/8kp49m6uq22ifnbwhfnk-2-251205085715-964d11a6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dragana Ilic - AI for Big Data in Astronomy.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/8palya86qaatvjhva1ms-2-dragana-ilic-ai-ilic-251208151906-652b819c-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Andy Cotgreave - Nothing is new in analytics.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/mba4vzcurvoh5lfrd5zw-6-251205194645-341bbbbe-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DSC Europe 25] Nikola Rajovic - Hardware Technologies Under the Hood: RISC-V...](https://cdn.slidesharecdn.com/ss_thumbnails/o2gptrmtoyqndgoshwgq-dsc2025-tenstorrent-rajovic-251205090438-814685f5-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Boris Perkovic - Lost in performance.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/uq5hrp7vsuahqkxzifux-1-251204082258-fd2ee09d-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Petar Zivanov - AI meets documents From chatbots to AI-powere...](https://cdn.slidesharecdn.com/ss_thumbnails/xer2bb6nrdc8pdpev0pc-8-251204082258-7c2fa4a1-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dragan Vucic - Building the Learning Organization - How AI Tr...](https://cdn.slidesharecdn.com/ss_thumbnails/8brigo2sbu6qur6gxrra-7-251205085715-6ae07d24-thumbnail.jpg?width=640&height=640&fit=bounds)