Download to read offline






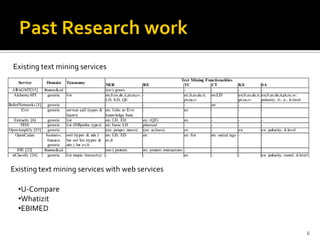

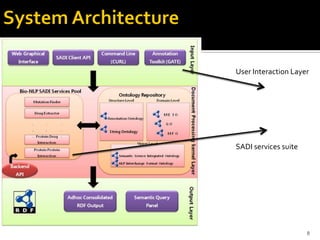
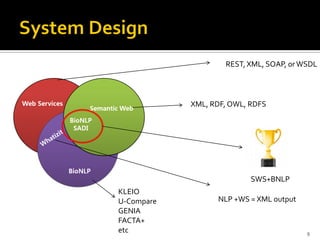
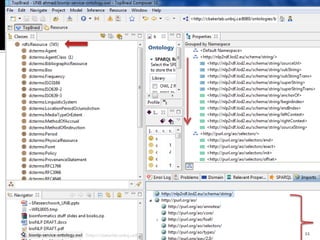
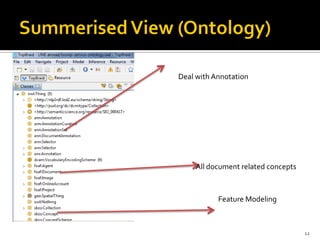
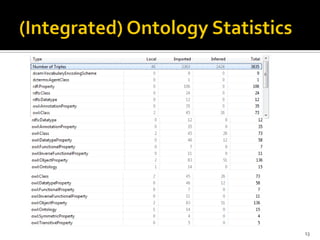












This document outlines a presentation on developing a suite of semantically interoperable biomedical natural language processing (BioNLP) services using the Semantic Automated Discovery and Integration (SADI) framework. The presentation covers the motivation for the work due to the large amount of biomedical literature being produced, an overview of the proposed system architecture and components, including ontology development and SADI services, and a demonstration of the system. Experimental results showing the system can accurately extract requested information from text are also discussed. The presentation concludes by discussing future work to improve system performance.












































































