Download as PDF, PPTX



















![Web Content Mining
Web content mining is related to data mining
and text mining. [Bing Liu. 2005]
It is related to data mining because many data
mining techniques can be applied in Web content
mining.
It is related to text mining because much of the
web contents are texts.
Web data are mainly semi-structured and/or
unstructured, while data mining is structured and
text is unstructured.](https://image.slidesharecdn.com/546326webmining-141217070629-conversion-gate02/85/5463-26-web-mining-25-320.jpg)









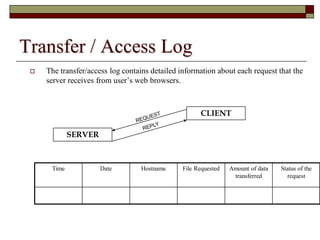
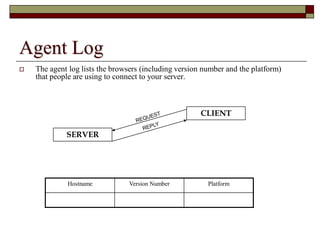
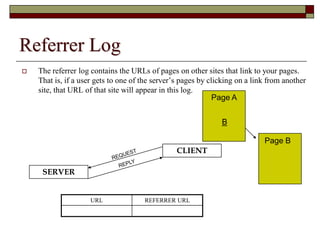

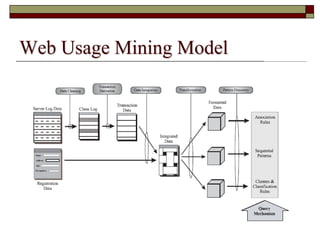

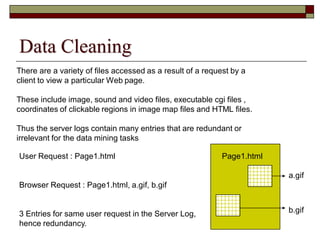
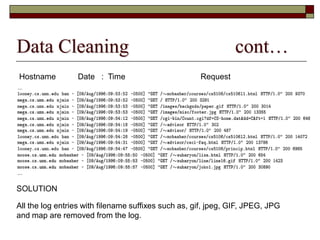



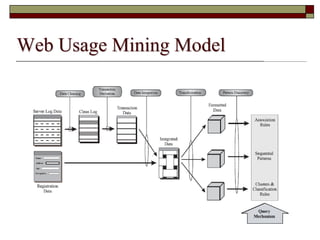



















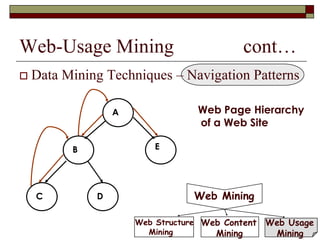
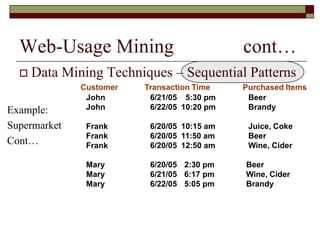
This document discusses different types of web mining techniques. It begins by defining web mining as the application of data mining techniques to discover and extract information from web data. The three main types of web mining are discussed as web content mining, web structure mining, and web usage mining. Web content mining involves mining the actual contents within web pages and documents. Web structure mining mines the hyperlink structure of websites to determine how web pages are linked together. Web usage mining mines web server logs to discover user browsing patterns and behaviors.

























































































![[DSC Europe 25] Ekaterina Bubenko - Behind the Curtain: How Data Roles Collab...](https://cdn.slidesharecdn.com/ss_thumbnails/anmv6x8dstqbbzchoklr-ekaterina-bubenko-behind-the-curtain-how-data-roles-collaborate-in-the-ai-era-a-260123083019-4b252ec7-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Predrag Maletic - Scaling AI in Banking – Our Strategic Journ...](https://cdn.slidesharecdn.com/ss_thumbnails/qu2onv0aruwlvqtygmxx-predrag-maletic-scaling-ai-in-banking-260123083019-6cf1da1d-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Milos Belcevic - Product Professional's Journey to Full-Stack...](https://cdn.slidesharecdn.com/ss_thumbnails/1zovd6fgsycdg4wvgvls-milos-belcevic-product-professionals-journey-to-full-stack-product-developer-260123083019-d993120d-thumbnail.jpg?width=640&height=640&fit=bounds)











