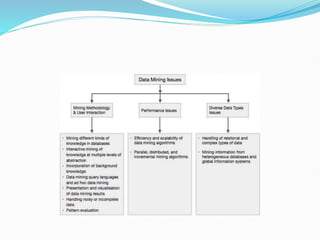
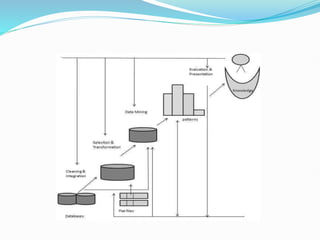
Data mining involves extracting useful patterns from large data sets to help businesses make informed decisions. It allows organizations to obtain knowledge from data, make improvements, and aid decision making in a cost-effective manner. However, data mining tools can be difficult to use and may not always provide precise results. Knowledge discovery is the overall process of discovering useful information from data, which includes steps like data cleaning, integration, selection, transformation, and mining followed by pattern evaluation and presentation of knowledge.









































































































![Polymer [ बहुलक ] Chemistry Notes PDF - Irfanullah Mehar - JJ Sir Chemistry.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/polymerchemistrynotespdf-irfanullahmehar-jjsirchemistry-260210172118-3f9b37f7-thumbnail.jpg?width=640&height=640&fit=bounds)










