Download as ODP, PPTX





























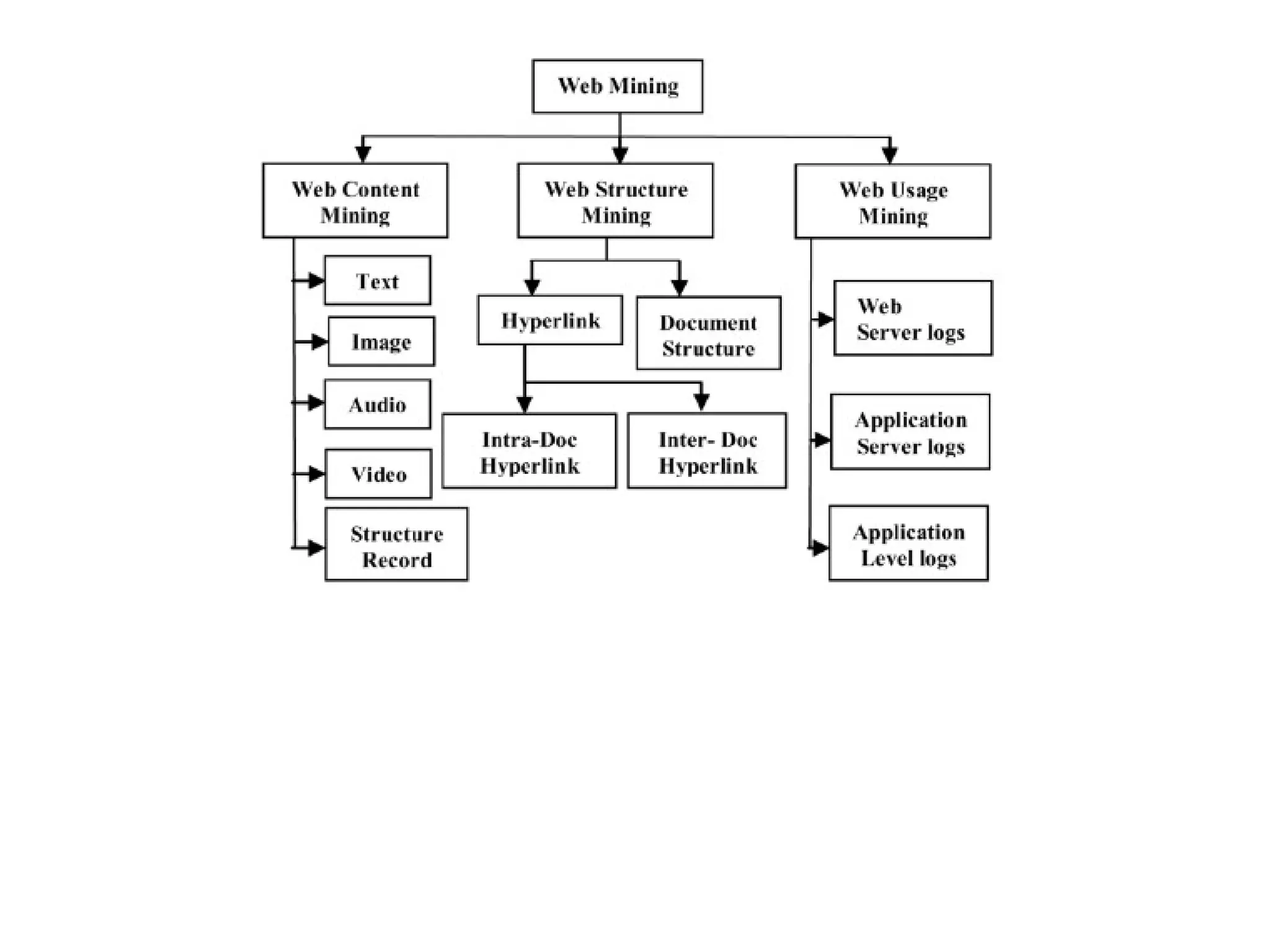
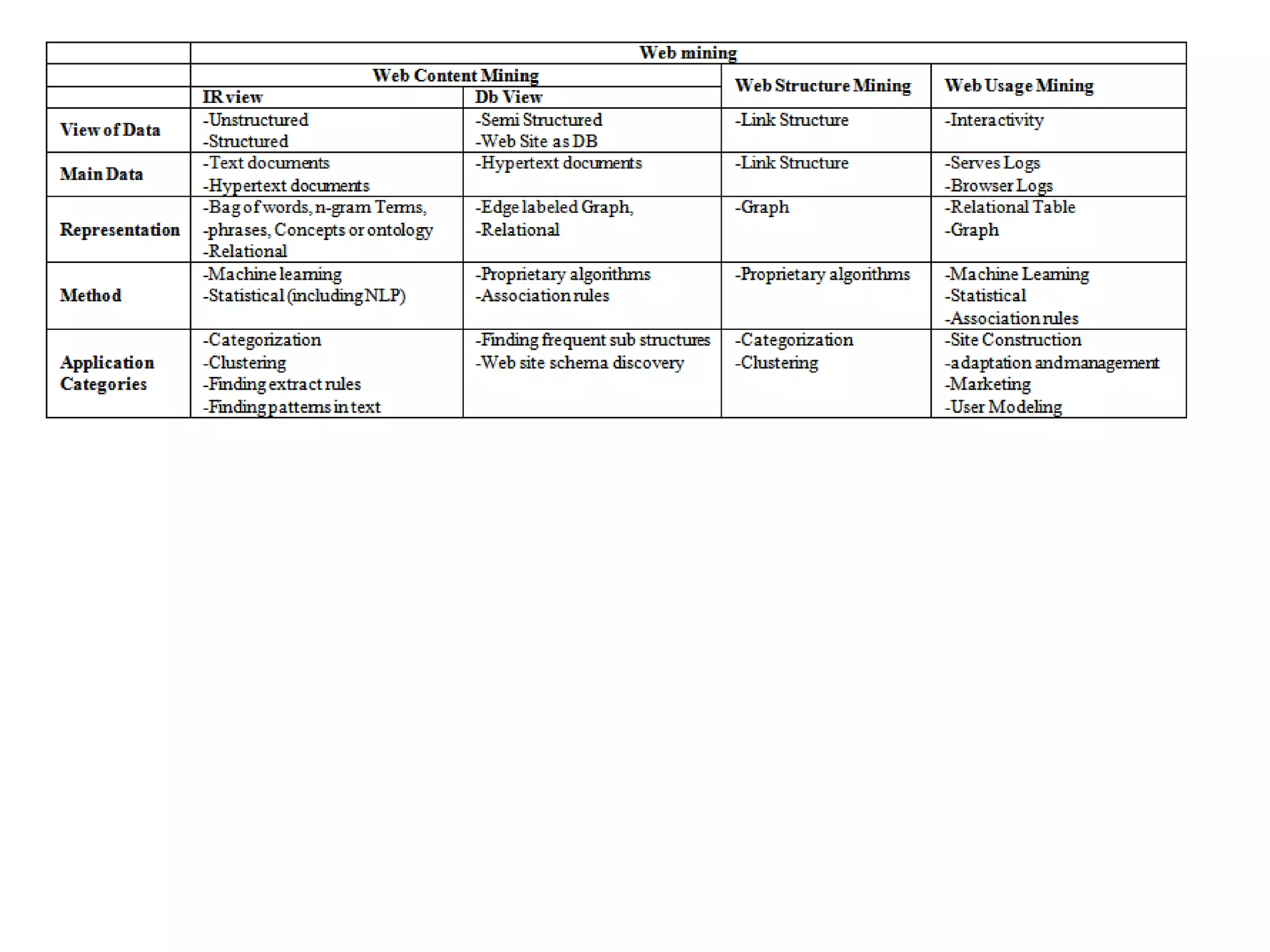












![Web Mining
WEB CONTENT MINING
Database View
DB view mainly uses the Object Exchange Model (OEM)
● Represents semi-structured data by a labeled graph
● The data in the OEM is viewed as a graph, with objects as the vertices and
labels on the edges
● Each object is identified by an object identifier [oid]
● Value is either atomic(integer, string, gif, html.....) or complex
Process typically starts with manual selection of Web sites for doing Web
content mining instead of searching the whole Internet for the specific
resources.
Main application:
The task of finding frequent substructures in semi-structured data.
The task of creating multi-layered database (MLDB) in which each layer is
obtained by generalization on lower layers and use a special purpose query
language for Web mining to extract some knowledge form MLDB of web
document.](https://image.slidesharecdn.com/webmining-170122080058/75/Web-mining-44-2048.jpg)






Web mining encompasses the use of data mining techniques to discover and extract valuable information from the vast and dynamic content of the World Wide Web. It addresses problems such as finding relevant information, creating new knowledge, personalizing content, and understanding user behavior, utilizing various methodologies including content, structure, and usage mining. Furthermore, web mining intersects with fields like information retrieval and machine learning to improve data extraction and user interaction on the web.































































































