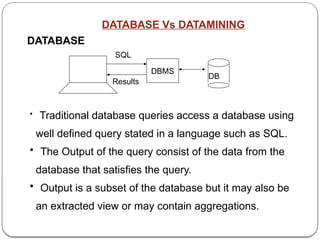
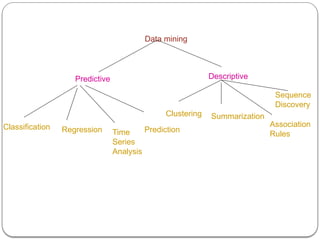
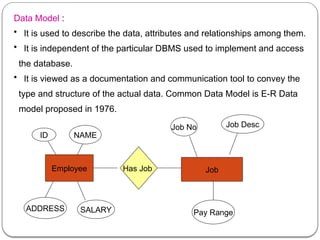
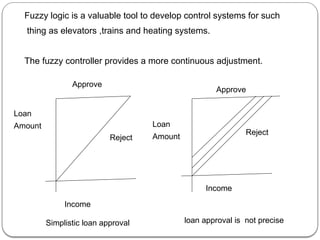
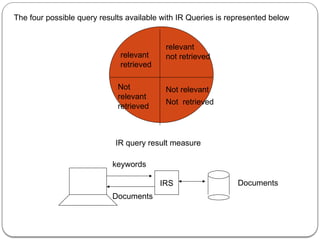
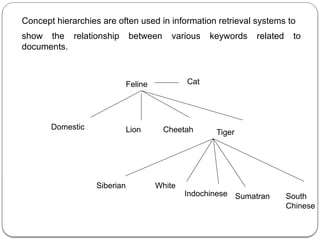
The document provides an in-depth overview of data mining, defining it as the process of discovering useful patterns from large datasets, and detailing various techniques such as classification, clustering, and association rules. It distinguishes between traditional database queries and data mining, highlighting the importance of the Knowledge Discovery in Databases (KDD) process, which includes steps from data selection to interpretation and evaluation. Issues in data mining implementation, such as human interaction and handling large datasets, are also discussed along with application areas across business and scientific fields.














































![FUZZY SETS AND FUZZY LOGIC : Lofty A Zadeh
Set : A Set is thought of as a collection of objects.
F={1,2,3,4,5}
Indicating set membership requirement F={x | x Є Z+
and x ≤ 5}
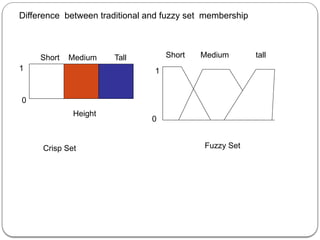
Fuzzy Set : Fuzzy Set is a set F in which set membership function F is
a real valued function with output in the range[0,1].
Membership value for kasturi being tall is 0.7 and value for her being
thin is 0.4.Membership value for her being both is 0.4 minimum of
both values .If these were really probabilities, product of these two
values has to be taken.](https://image.slidesharecdn.com/dwdmunit4-241202005301-f1dd0ca9/85/DWDM_UNIT4-pptx-ddddddddddddddddddddddddddddd-49-320.jpg)










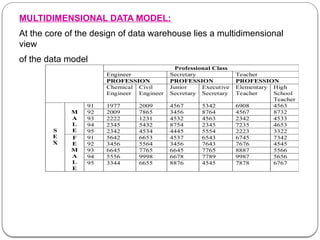


![Data Cube
An n-dimensional data cube C[A1,A2…..An ] is a database with n
dimensions as A1,A2 ……..An ,each of which represent a theme
and contains |Ai| number of distinct elements in the dimension Ai.
Each distinct element of Ai corresponds to a data row of C.A data
cell in the cube C[a1,a2,……an] stores the numeric measures of the
data for Ai=ai Vi Thus a data cell corresponds to an instantiation of
all dimensions.
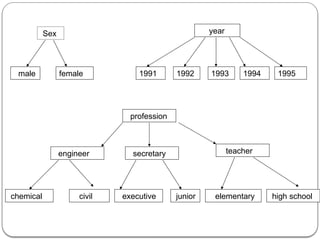
C [sex, profession, year] is the data cube and data cell [male, civil
engineer, year] stores 2780 as its associated measure.
As |sex|=2,|profession|=6 and |year|=5 we have Three dimensions
with 2 ,6 and 5 rows respectively.](https://image.slidesharecdn.com/dwdmunit4-241202005301-f1dd0ca9/85/DWDM_UNIT4-pptx-ddddddddddddddddddddddddddddd-67-320.jpg)


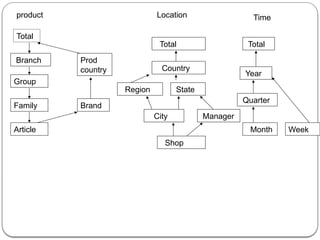
![Lattice of Cuboids :
Multidimensional data can be viewed as lattice of cuboids. The
C[A1,A2,…….An] at the finest level of granularity is called base
cuboid and it consist of all the data cells. The (n-1)-D cubes are
obtained by grouping the cells and computing the combined
numeric measure of a given dimension, Finally the coarsest
level
consists of one cell with numeric measures of all n dimensions
This is called an apex cuboid. In lattice of cuboids, all other
cuboids lie between the base cuboid and apex cuboid.
In above example the dimension hierarchy considered for the
data cube are time: (month<quarter<year);
location : (city<province<country) and product.](https://image.slidesharecdn.com/dwdmunit4-241202005301-f1dd0ca9/85/DWDM_UNIT4-pptx-ddddddddddddddddddddddddddddd-72-320.jpg)
![Base cuboid of lattice corresponds to C[ month ,city ,product] .
Apex cuboid of lattice corresponds to C[ year, country ,product]
Other intermediate cuboids in the lattice are
C[ quarter ,province ,product]
C[ quarter, country, product]
C[ month ,province ,product]
C[ month, country ,product]
C[ year ,city ,product]
C[ year ,province ,product]](https://image.slidesharecdn.com/dwdmunit4-241202005301-f1dd0ca9/85/DWDM_UNIT4-pptx-ddddddddddddddddddddddddddddd-73-320.jpg)













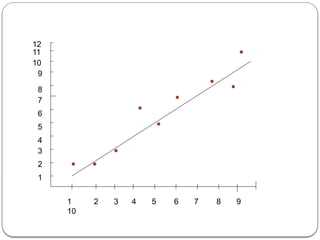
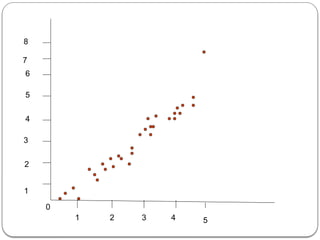
![The fig above illustrate the more general use of Linear regression with
one input value. Here we have a sample of data we wish to model
using a linear model. The line generated by the linear regression
technique is shown in fig .The actual point do not fit the linear model
exactly. Thus ,this model is an estimate of what the actual input-output
relationship is. We can use the generated linear model to predict an
output value given an input value.
Two different data variables X and Y. may behave similarly. Correlation
is the problem of determining how much alike the two variables
actually are.
One standard formula to measure linear correlation is correlation
coefficient r.
Given two variables X and Y the correlation coefficient is a real value r
Є[-1,1]
Positive number indicates positive correlation
Negative number indicates negative correlation means that one
variable increases while other decreases In value.
Closer the value of r to 0 the smaller the correlation.](https://image.slidesharecdn.com/dwdmunit4-241202005301-f1dd0ca9/85/DWDM_UNIT4-pptx-ddddddddddddddddddddddddddddd-88-320.jpg)


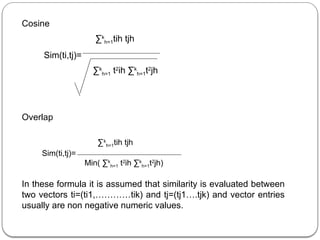
![Definition : Similarity between two tuples ti and tj Sim(ti,tj) in a database is
a mapping from D*D to range[0,1] thus Sim(ti,tj) Є [0,1].
Desirable characteristics of Good Similarity Measure
1. ν ti Є D Sim(ti,tj)=1
2. ν ti tj Є D Sim(ti,tj)=0 if ti and tj are not alike at all.
3. ν ti tj,tk Є D Sim(ti,tj) < Sim(tj,tk) if ti is more like tk then it is more like tj.
Defining Similarity measure is difficult part often concept of alikeness is
itself not well defined .When idea of Similarity measures is used in
classification where classes are predefined this problem is somewhat
easier than when it is used for clustering where classes are not known
in advance.](https://image.slidesharecdn.com/dwdmunit4-241202005301-f1dd0ca9/85/DWDM_UNIT4-pptx-ddddddddddddddddddddddddddddd-91-320.jpg)




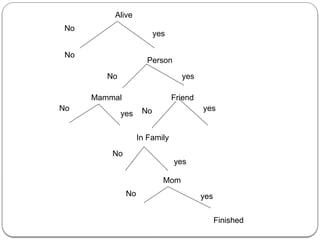




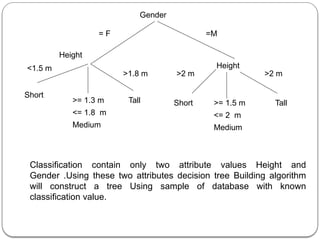


























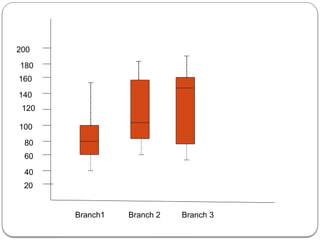





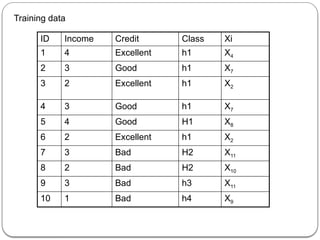
![P(h1)=60% P(h2)=20% P(h3)=10% P(h4)=10%
To make predictions a domain expert has determined that the attributes we
should be looking at our income and credit category
Assume that income categorized by ranges
[0,$10,000],[$10,000,$50,000],[$50,000,$100000],[$100000,∞] these
ranges are encoded in table as 1,2,3,4 resply.
Suppose credit is categorized as excellent, good or bad. By combining
these we have 12 values in data space D={x1,x2…x12} relationship
between xi values and attributes shown as](https://image.slidesharecdn.com/dwdmunit4-241202005301-f1dd0ca9/85/DWDM_UNIT4-pptx-ddddddddddddddddddddddddddddd-137-320.jpg)


















































