This document discusses the derivation of backpropagation for neural networks. It begins with an overview of logistic regression and the sigmoid activation function. It then shows how to apply the chain rule to calculate the gradients needed for backpropagation. Specifically, it derives that the error term δ for each layer can be calculated as the error from the next layer multiplied by the weights and activation. This allows efficient computation of the gradient for each weight and bias term. Sample Python code is also provided to implement a basic neural network with backpropagation.
![This draft was prepared using the LaTeX style file belonging to the Journal of Fluid Mechanics 1
Simple Backpropagation: Writing your own
Neural Network
Mohamamd Shafkat Amin1†
(Received xx; revised xx; accepted xx)
In this document, I discuss the derivation of back-propagation. First, I discuss the basics
of logistic regression and build on top of that and generalize for neural networks. I do
not talk about optimization algorithms [Sebastian (2016)] and only concentrate on the
basic mathematics behind backpropagation in this document. This document is meant
to be a first introduction to neural networks.
Key words: backpropagation, NN, logistic regression
1. Logistic Regression Primer
Before we discuss NNs, let’s start the discussion with logistic regression. In figure 2,
we have depicted the functions in logistic regression. Here Sigmoid function assumes the
following form:
Sigmoid(z) = σ(z) =
1
1 + e−z
and looks as shown in figure 1.
The loss function is:
L = −{
1
m m
(ylog (ˆy) + (1 − y) log (1 − ˆy))}
Here,
ˆy =
1
1 + e−z
z =
i
wixi + b
We will refer to ˆy as a (for activation for neural network) interchangeably.
We need to calculate derivatives:
∂L
∂wi
and
∂L
∂b
The reason why we compute gradient is because, negative gradient directs toward the
steepest descent along a function. As shown in figure 3, if we follow along the negative
gradient , we proceed toward the global minimum of a convex function. Discussion on
† Email address for correspondence: shafkat@gmail.com](https://image.slidesharecdn.com/dnn-180313023243/85/Writing-your-own-Neural-Network-1-320.jpg)
![This draft was prepared using the LaTeX style file belonging to the Journal of Fluid Mechanics 1
Simple Backpropagation: Writing your own
Neural Network
Mohamamd Shafkat Amin1†
(Received xx; revised xx; accepted xx)
In this document, I discuss the derivation of back-propagation. First, I discuss the basics
of logistic regression and build on top of that and generalize for neural networks. I do
not talk about optimization algorithms [Sebastian (2016)] and only concentrate on the
basic mathematics behind backpropagation in this document. This document is meant
to be a first introduction to neural networks.
Key words: backpropagation, NN, logistic regression
1. Logistic Regression Primer
Before we discuss NNs, let’s start the discussion with logistic regression. In figure 2,
we have depicted the functions in logistic regression. Here Sigmoid function assumes the
following form:
Sigmoid(z) = σ(z) =
1
1 + e−z
and looks as shown in figure 1.
The loss function is:
L = −{
1
m m
(ylog (ˆy) + (1 − y) log (1 − ˆy))}
Here,
ˆy =
1
1 + e−z
z =
i
wixi + b
We will refer to ˆy as a (for activation for neural network) interchangeably.
We need to calculate derivatives:
∂L
∂wi
and
∂L
∂b
The reason why we compute gradient is because, negative gradient directs toward the
steepest descent along a function. As shown in figure 3, if we follow along the negative
gradient , we proceed toward the global minimum of a convex function. Discussion on
† Email address for correspondence: shafkat@gmail.com](https://image.slidesharecdn.com/dnn-180313023243/75/Writing-your-own-Neural-Network-1-2048.jpg)
![2 Mohammad Shafkat Amin
[hc]
Figure 1. Sigmoid function [Source: Wikipedia]
Figure 2. Logistic Regression
Figure 3. Gradient descent[Library (2017)]
convexity of functions and local/global minima is beyond the scope of this document.
Let’s begin:
∂L
∂wi
=
∂L
∂z
∗
∂z
∂wi](https://image.slidesharecdn.com/dnn-180313023243/85/Writing-your-own-Neural-Network-2-320.jpg)



![6 Mohammad Shafkat Amin
To learn more about different cost functions see [Christopher (2016)] Here aL
i is the
output of the activation function from the last layer. We need to calculate the partial
derivative with respect to the parameters. For the last layer lets assume the following
notations:
∂C
∂zL
j
= δL
j
And for any arbitrary layer l, we have:
∂C
∂zl
j
= δl
j
In essence, backpropagation facilitates efficient computation of a massive chain rule
problem. To efficiently apply chain rule, in backpropagation, we compute and store δl
j
values and reuse them instead of recomputing redundantly. Let’s expand on the last layer:
∂C
∂zL
j
=
∂C
∂aL
j
∗
∂aL
j
∂zL
j
= (aL
j − yL
j ) ∗
∂σ(zL
j )
∂zL
j
= (aL
j − yL
j ) ∗ σ (zL
j )
Hence, we have calculated:
δL
j = (aL
j − yL
j ) ∗ σ (zL
j )
The first part of the equation is derived from following:
∂C
∂aL
j
=
∂ 1
2 (yL
i − aL
i )2
∂aL
j
=
∂ 1
2 {(yL
1 − aL
1 )2
+ . . . + (yL
2 − aL
2 )2
+ (yL
j − aL
j )2
+ . . .}
∂aL
j
= (aL
j − yL
j )
Now let’s generalize the computation for any arbitrary layer l. We want to compute:
δl
i =
∂C
∂zl
i
If we change the value of zl
i (red node in figure 5),the change propagates to many nodes
in the following layer (red edges in the figure).
δl
i =
∂C
∂zl
i
=
k
∂C
∂zl+1
k
∗
∂zl+1
k
∂zl
i](https://image.slidesharecdn.com/dnn-180313023243/85/Writing-your-own-Neural-Network-6-320.jpg)
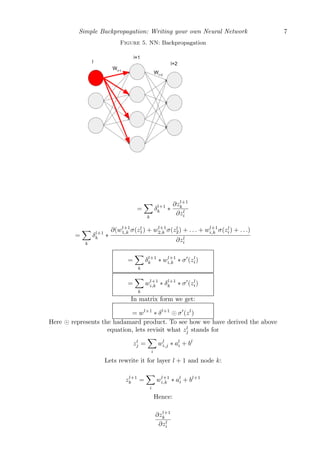
![8 Mohammad Shafkat Amin
=
∂(wl+1
i,k ∗ al
i)
∂zl
i
= wl+1
i,k ∗ σ (zl
i)
Now we will calculate the derivative with respect to the coefficients of interest:
∂C
∂wl
i,j
=
∂C
∂zl
j
∗
∂zl
j
∂wl
i,j
=
∂C
∂zl
j
∗
∂zl
j
∂wl
i,j
= δl
j ∗
∂zl
j
∂wl
i,j
= δl
j ∗ al−1
i
In matrix notation:
∂C
∂wl
= al−1
∗ (δl
)T
2.1. Summary
∂C
∂zL
= δL
= (aL
− yL
) σ (zL
)
∂C
∂zl
= δl
= wl+1
∗ δl+1
σ (zl
)
zl
= (wl
)T
∗ al−1
+ bl
∂C
∂wl
= al−1
∗ (δl
)T
Similarly for bias:
∂C
∂bl
= δl
For more information, please see [Goodfellow et al. (2016)] and [Nielsen (2016)].
3. Writing your own NN
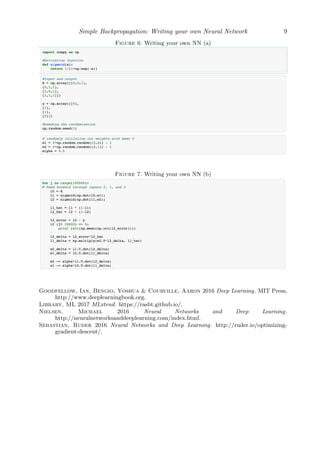
Sample python code to write your own NN is depicted in figure 6 and figure 7.
REFERENCES
Christopher, Bourez 2016 Neural Networks and Deep Learning.
http://christopher5106.github.io/deep/learning/2016/09/16/about-loss-functions-
multinomial-logistic-logarithm-cross-entropy-square-errors-euclidian-absolute-frobenius-
hinge.html.](https://image.slidesharecdn.com/dnn-180313023243/85/Writing-your-own-Neural-Network-8-320.jpg)