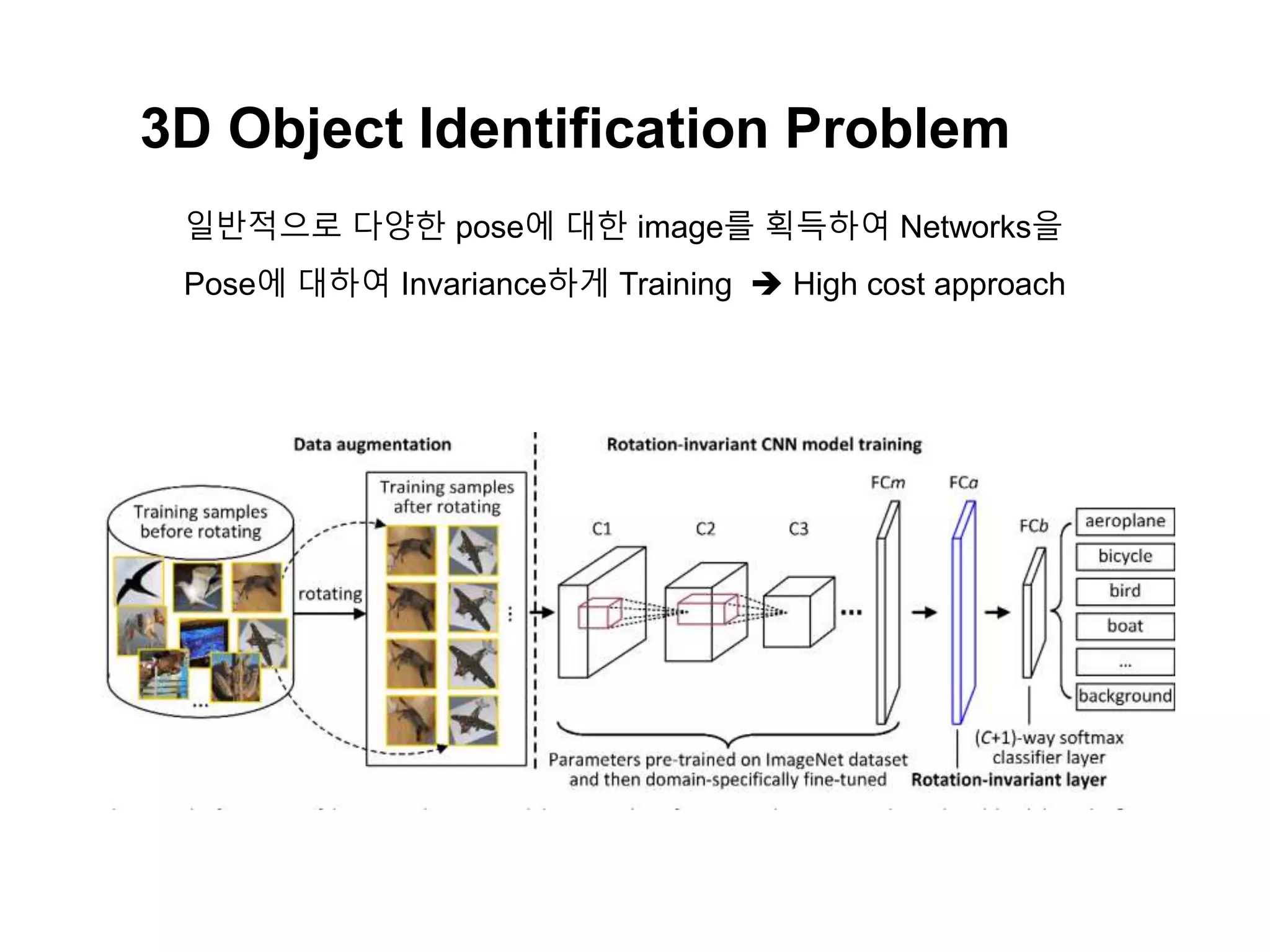
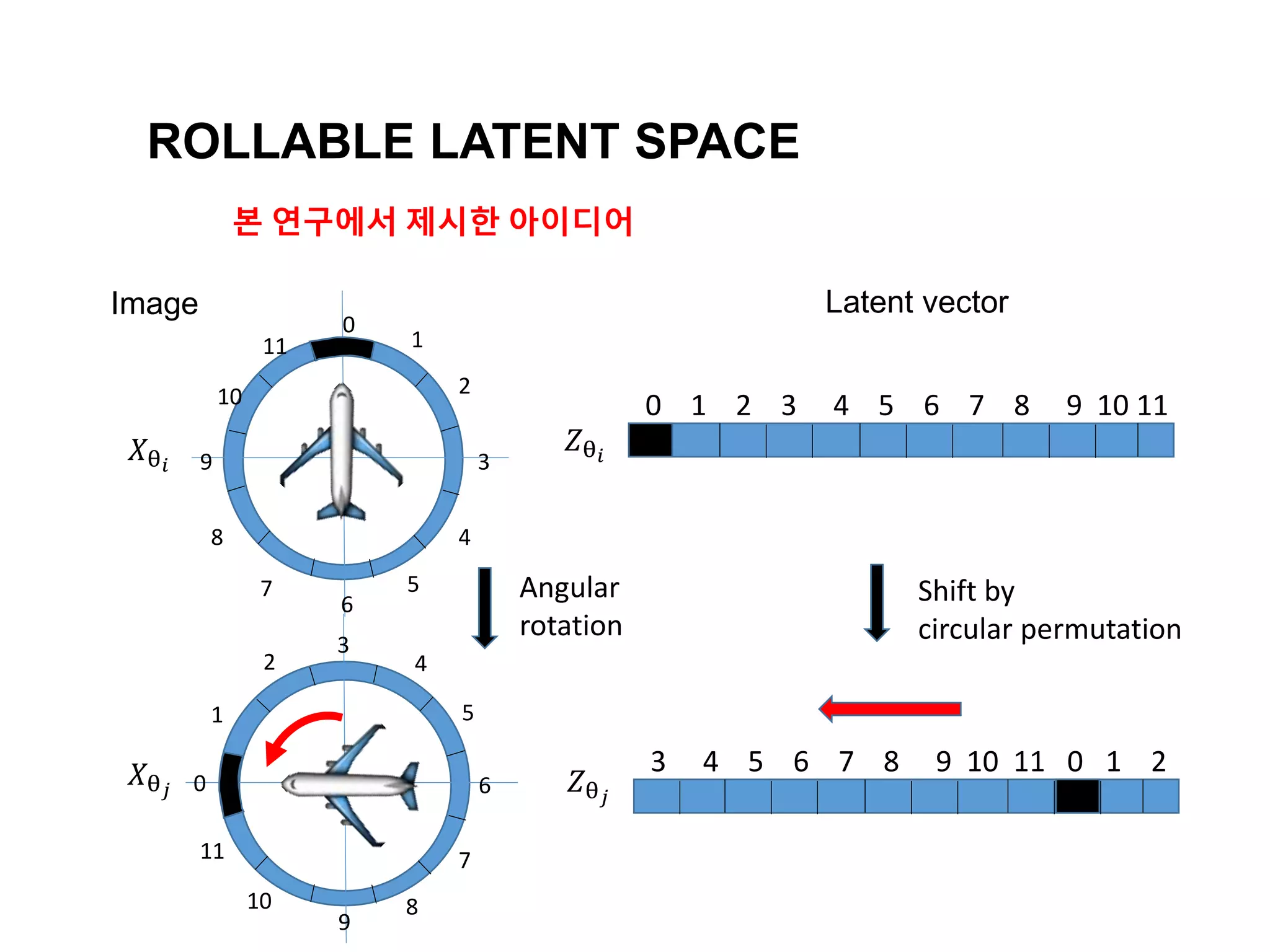
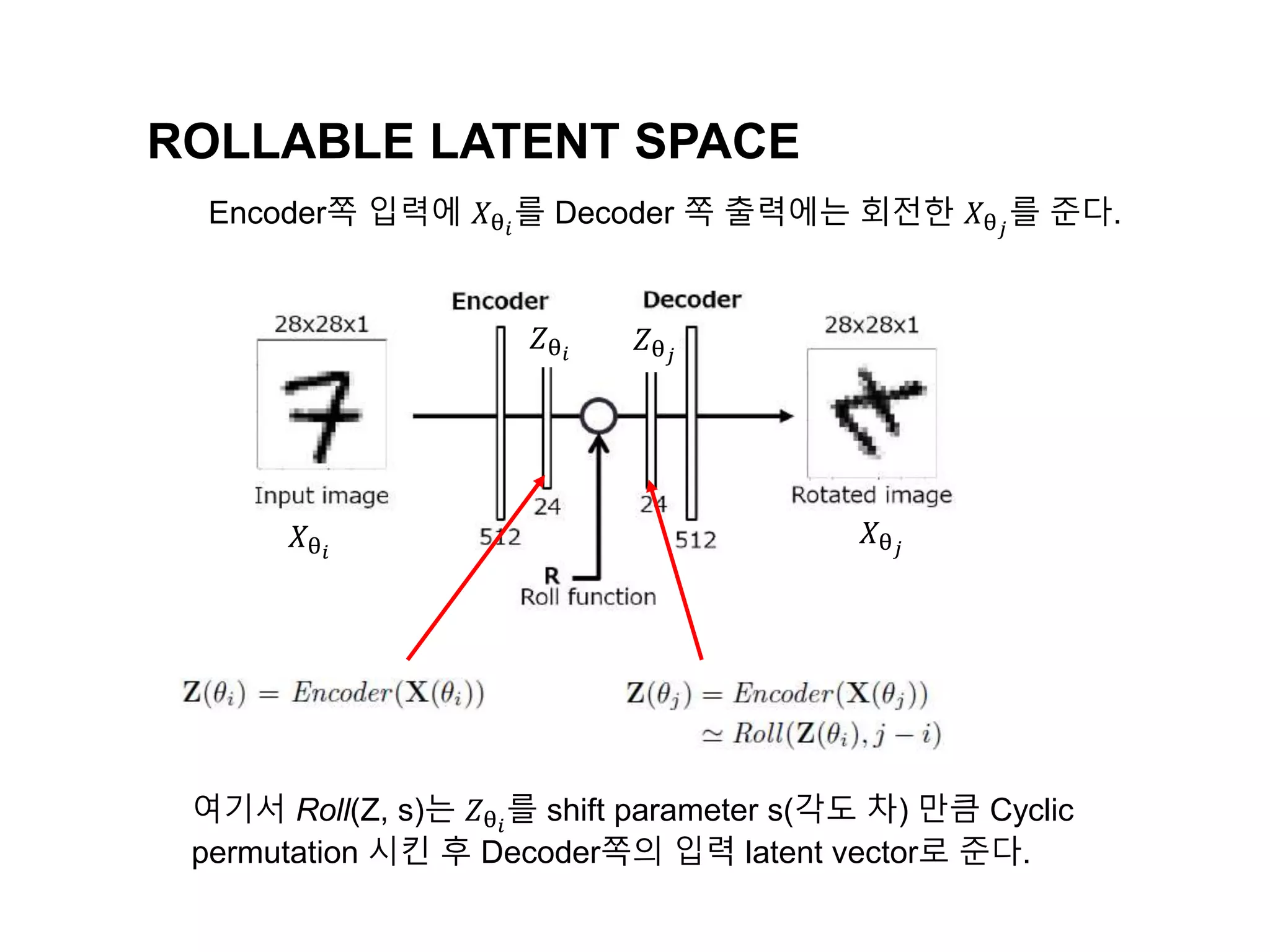
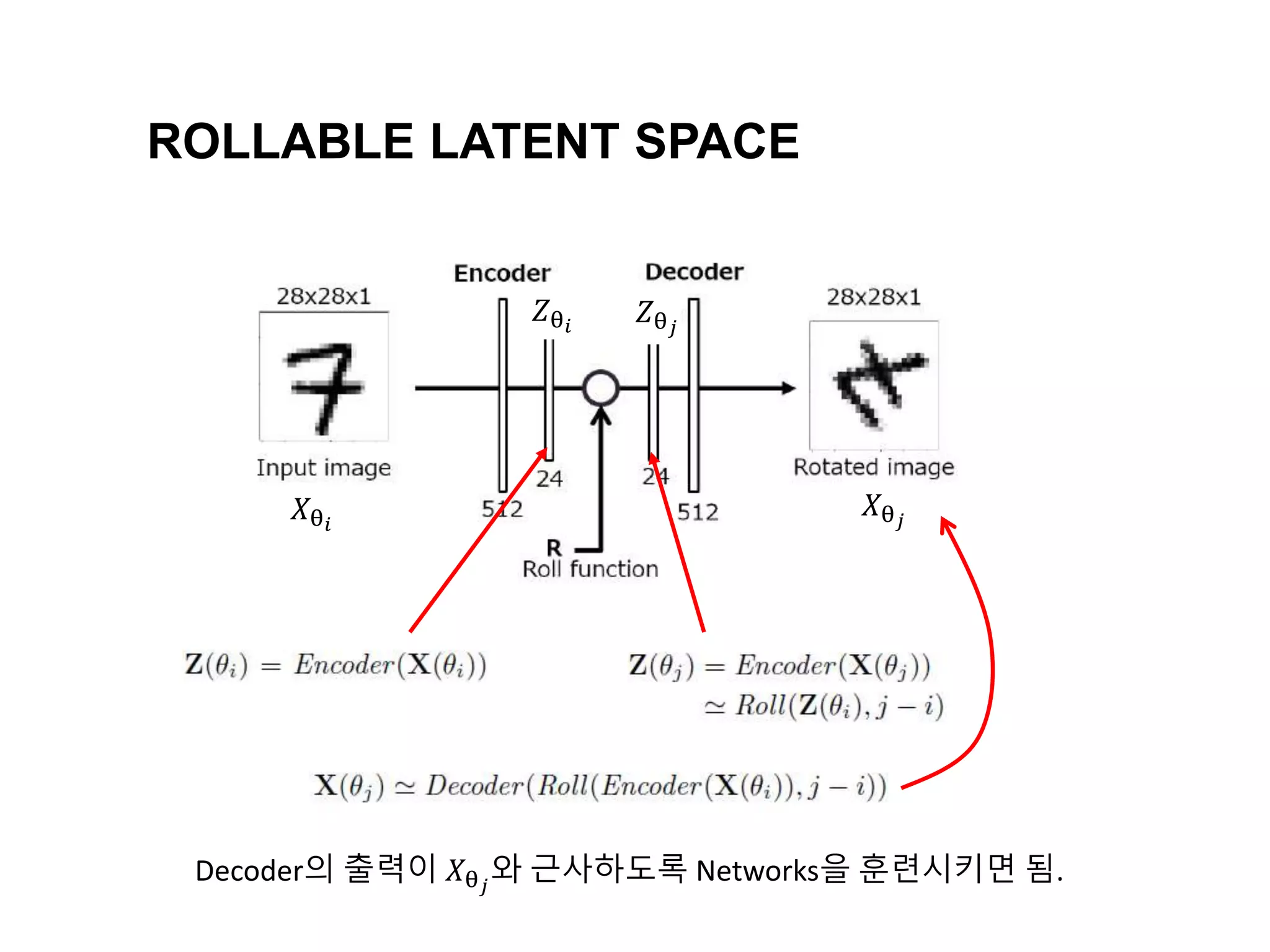
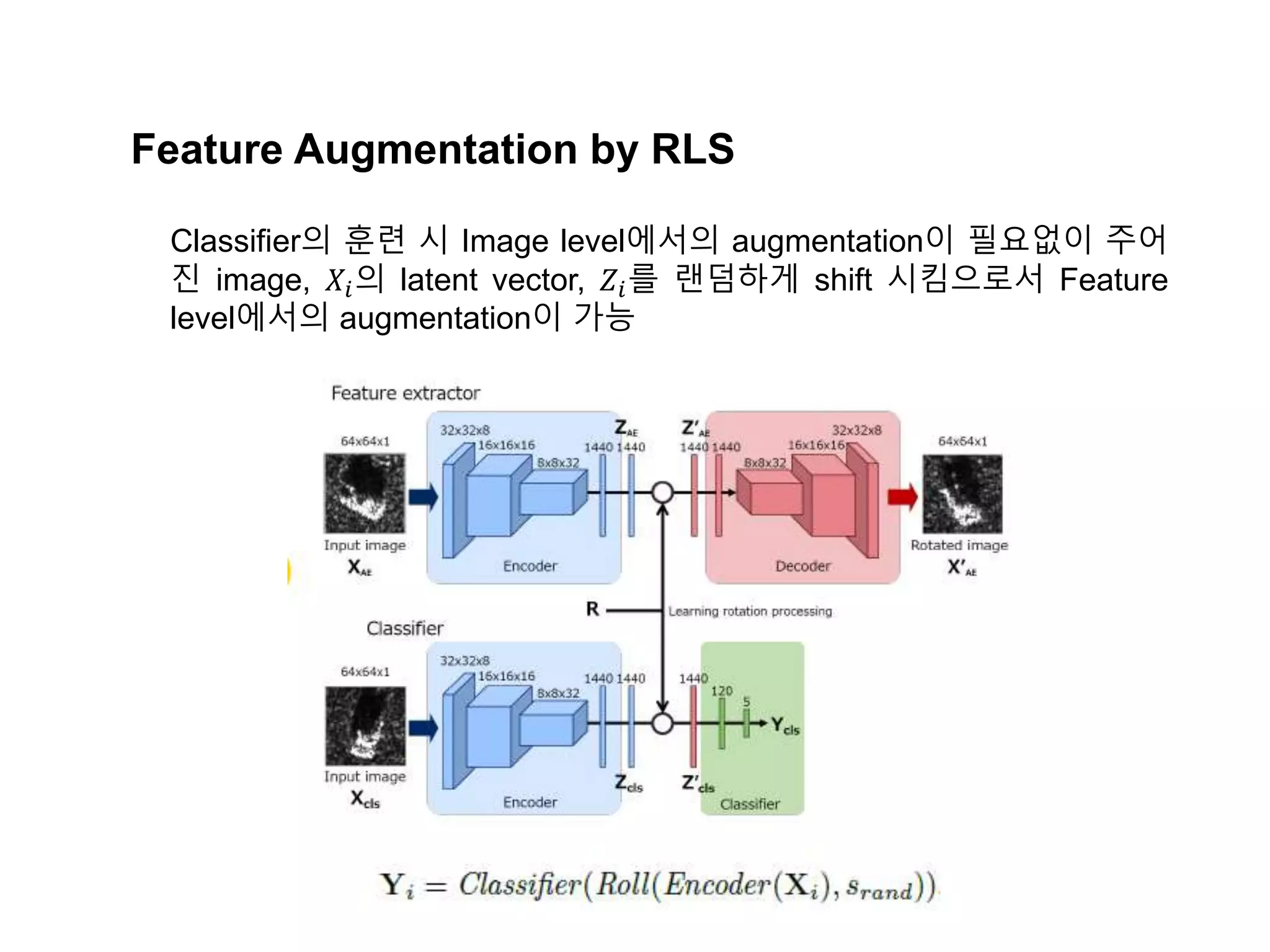
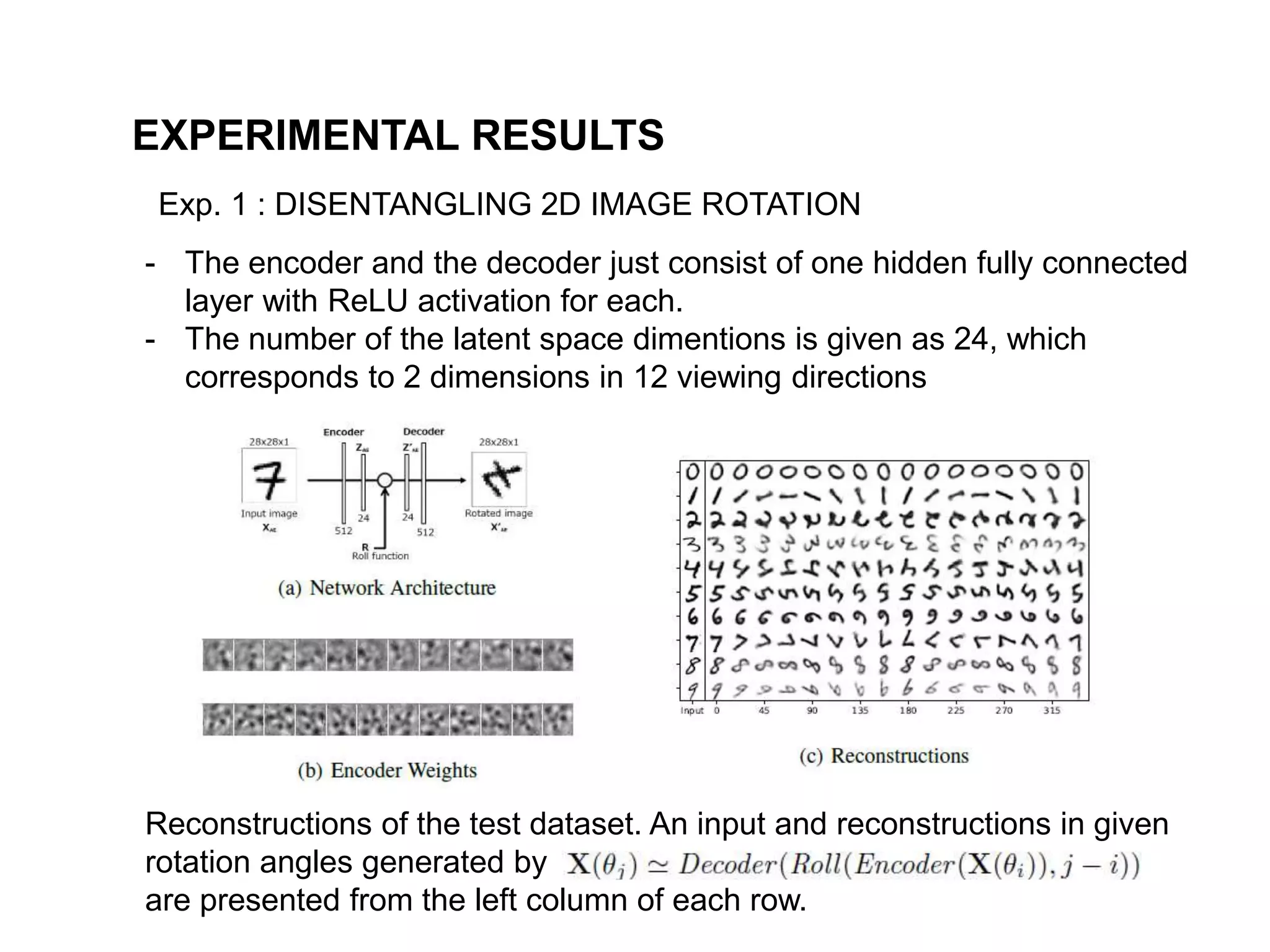
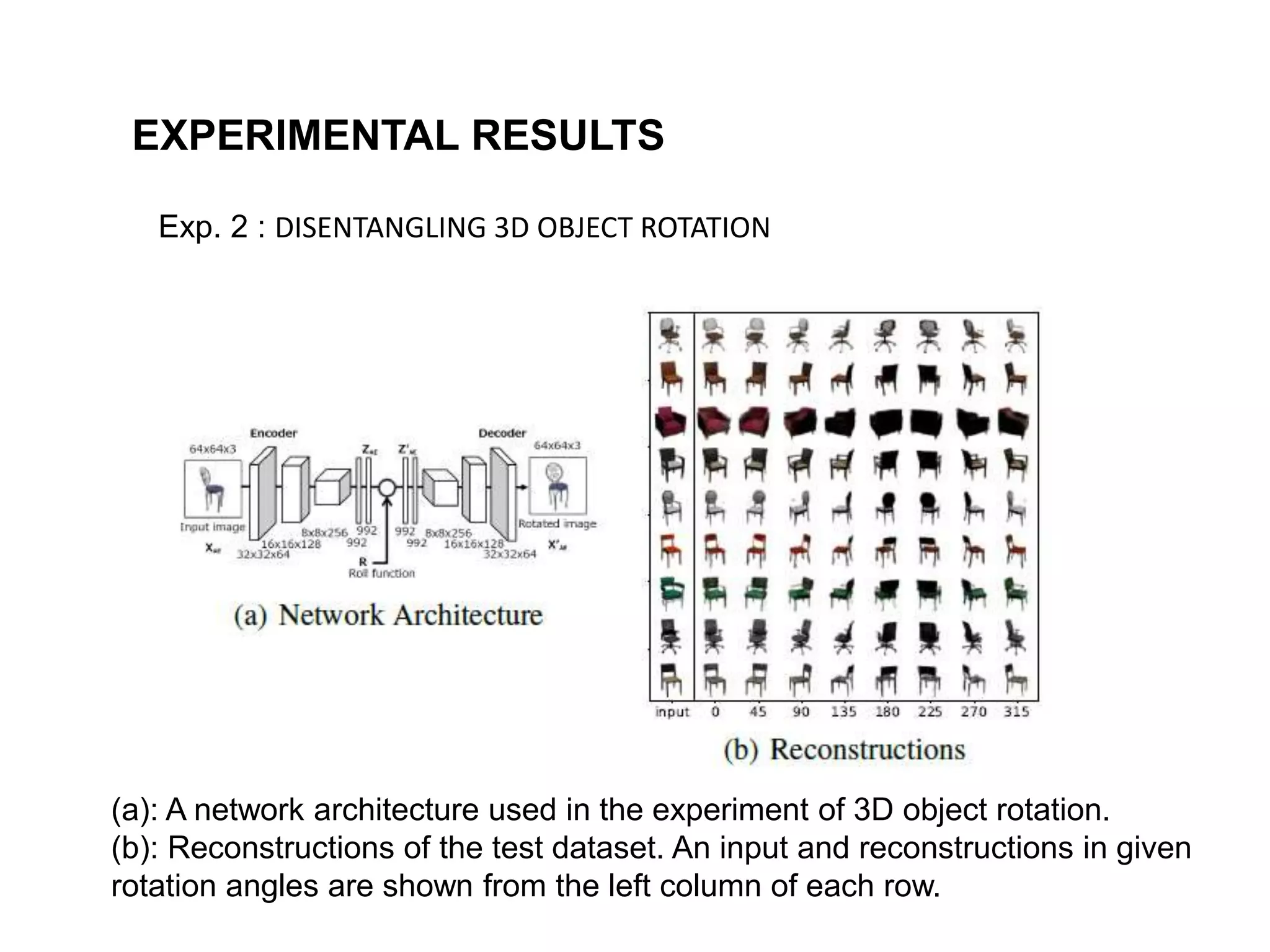
The document discusses a method for disentangling object identity from posture information using a rollable latent space approach, which enables the training of networks without high costs typically associated with acquiring various pose images. It presents a modified auto-encoder that maps angular rotations in the image space to shifts in the latent vector space, allowing for effective feature augmentation and the inference of latent vectors for untrained poses. Experimental results demonstrate the effectiveness of this method through 2D and 3D object rotation reconstructions.






































![[Paper] DetectoRS for Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/paperdetectorsobjectdetection-210320013551-thumbnail.jpg?width=640&height=640&fit=bounds)





![제 13회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [GAN 안 쓰는 세얼GAN이들] : 코로나 언택트 시대, 나의 홈트레이닝을 도와줄 AI...](https://cdn.slidesharecdn.com/ss_thumbnails/health-210201083551-thumbnail.jpg?width=640&height=640&fit=bounds)






![[111]실내이동체정밀위치추정기술의세가지측면 도락주](https://cdn.slidesharecdn.com/ss_thumbnails/111-161023160508-thumbnail.jpg?width=640&height=640&fit=bounds)







































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)