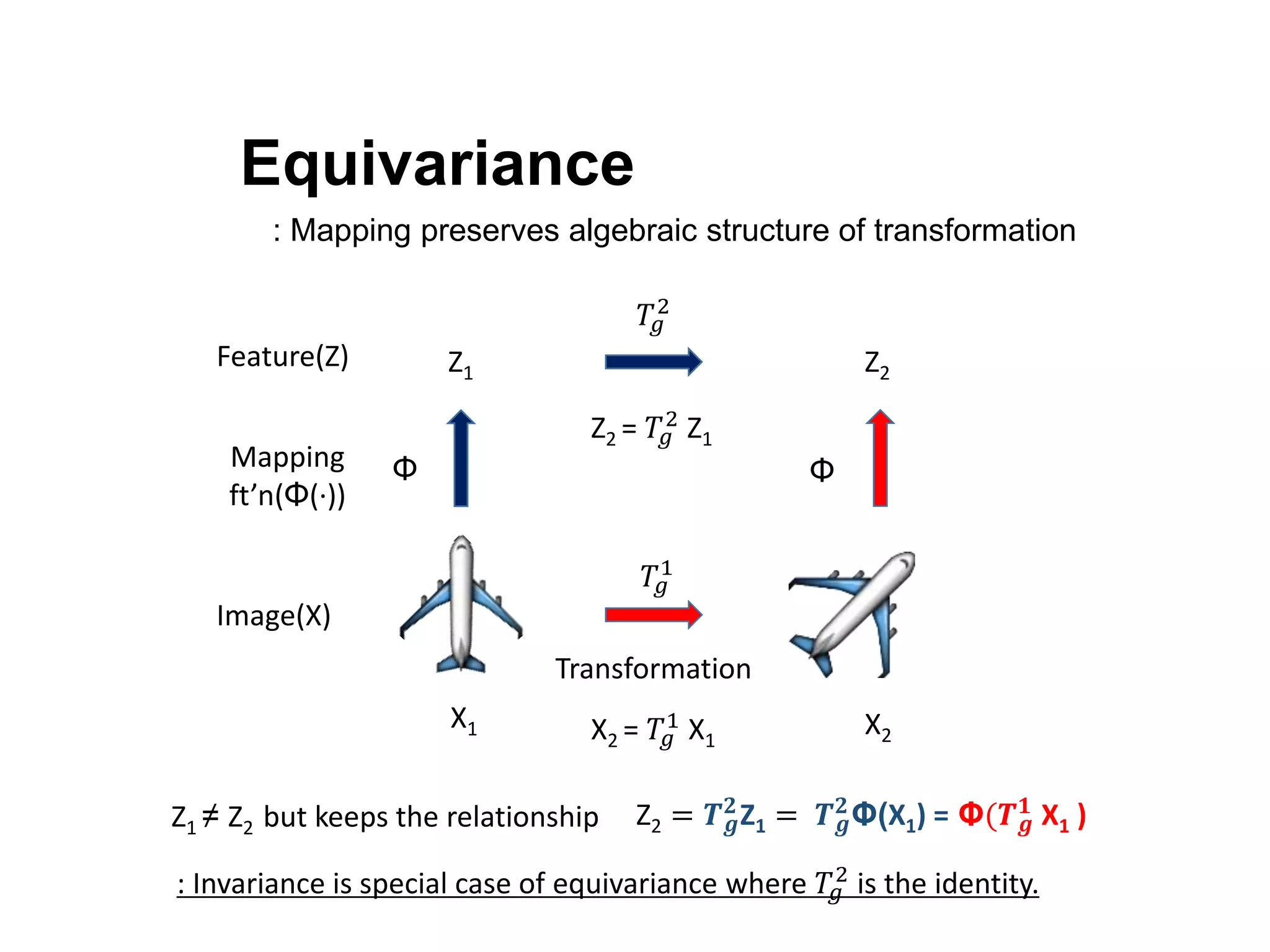
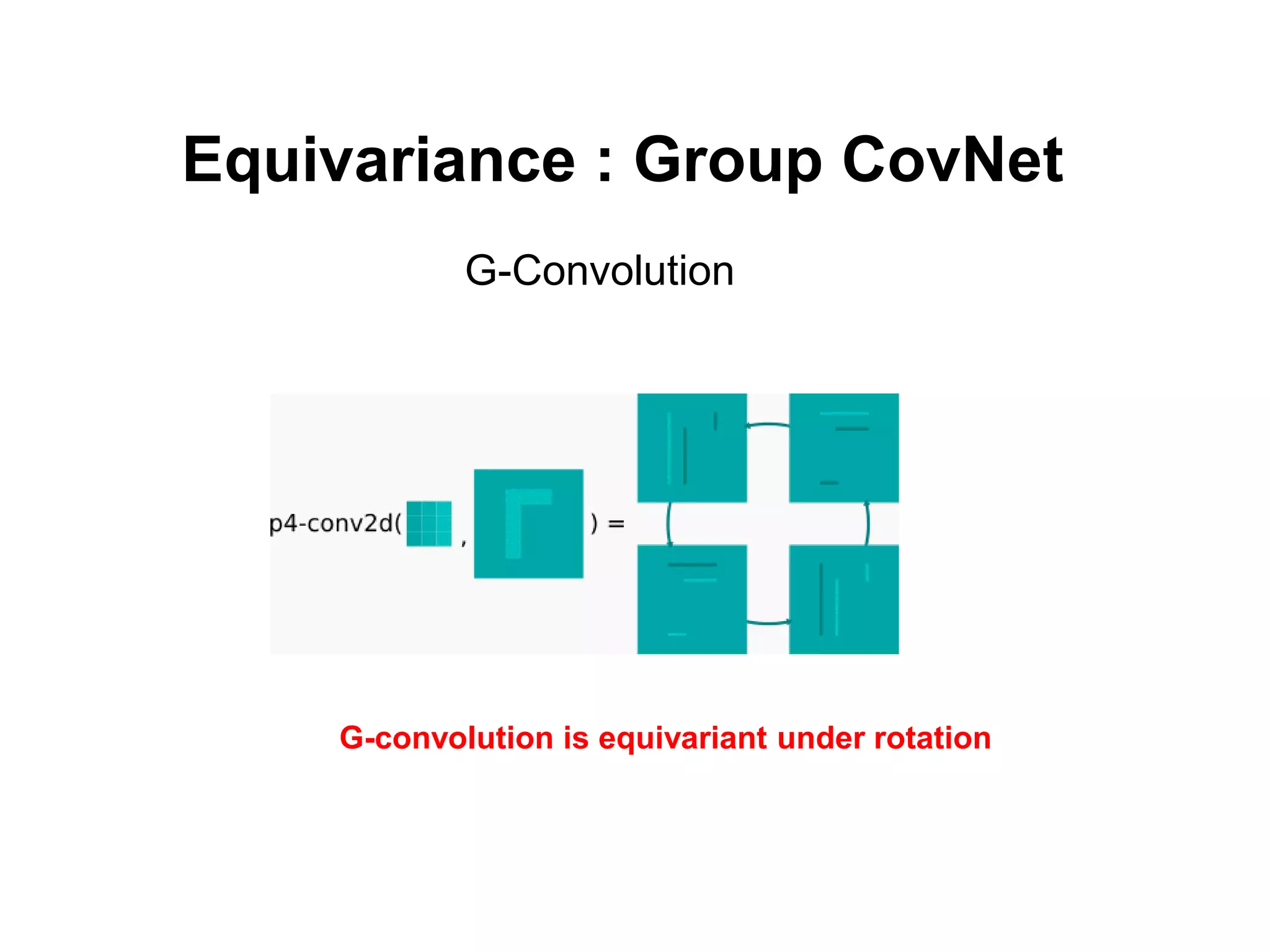
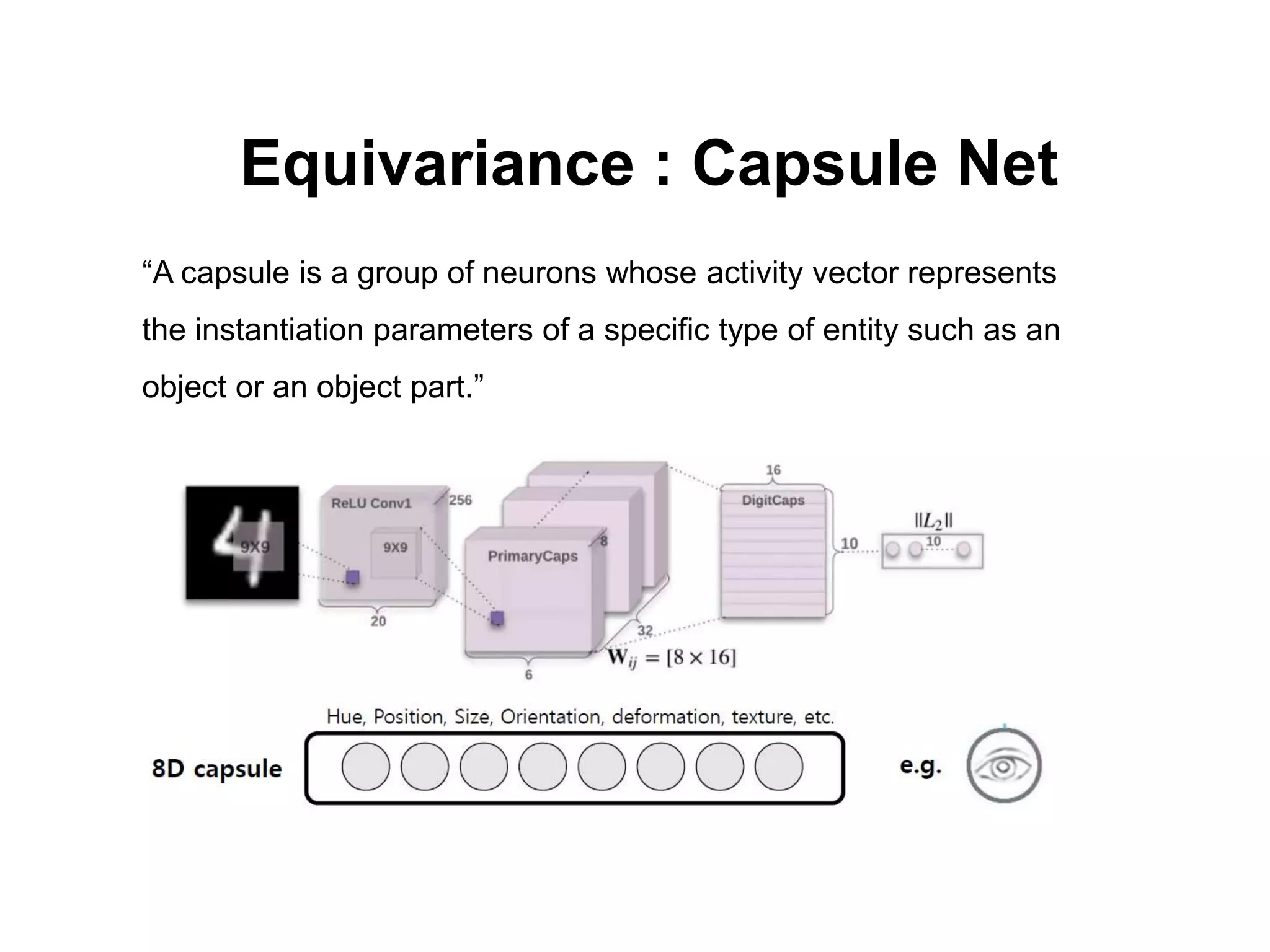
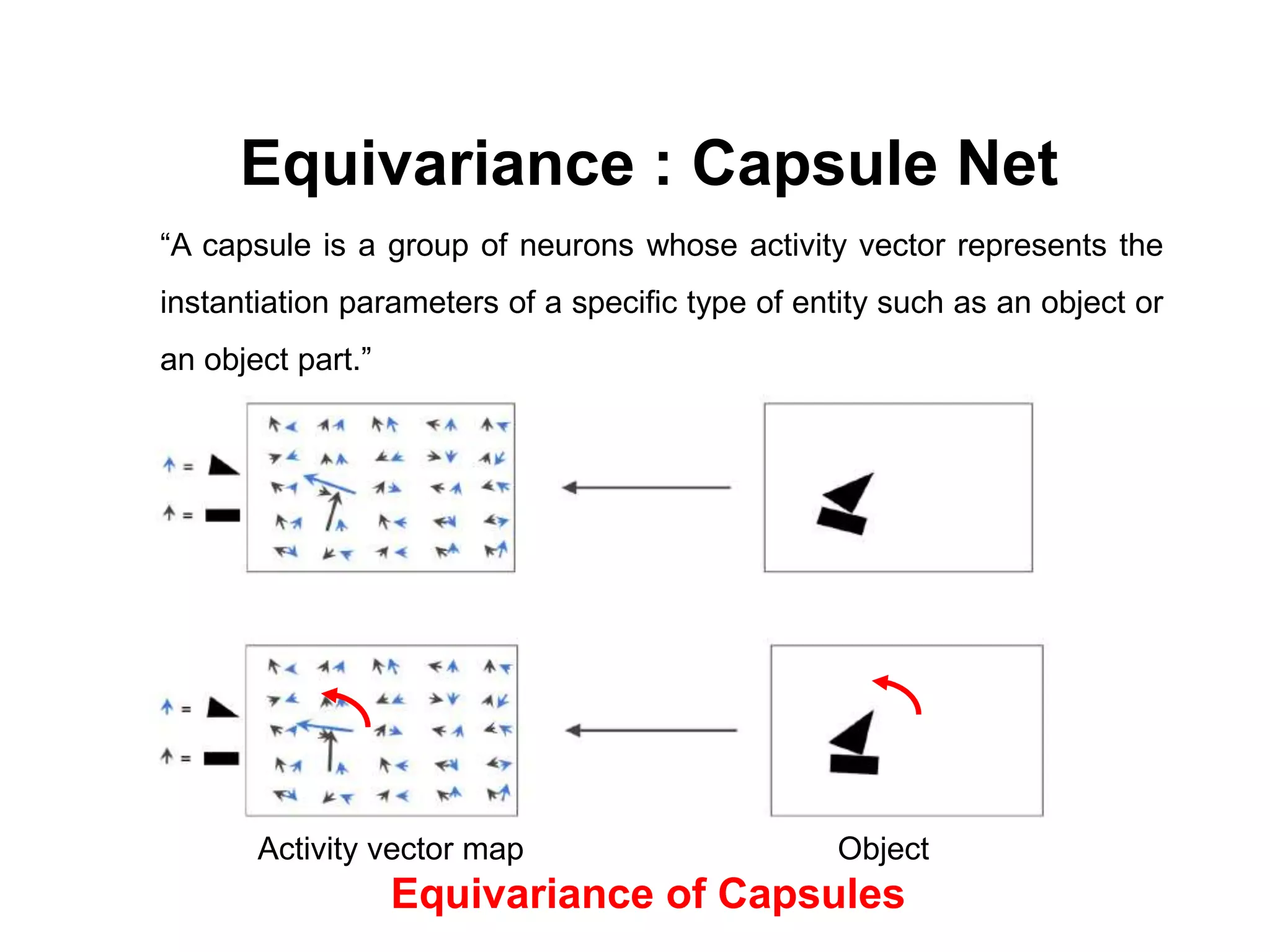
The document discusses the limitations of conventional convolutional neural networks (CNNs), particularly their equivariance under translation but not under rotation. It introduces group convolutional networks (g-CNNs) that utilize a group of filters to achieve equivariance, allowing for better recognition of features across different orientations. Additionally, it explores the concept of capsules in neural networks, which represent instantiation parameters for objects and contribute to understanding equivariance.


















![[DL輪読会]Model soups: averaging weights of multiple fine-tuned models improves ...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0401-220405031053-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Deep Learning 第15章 表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning15-180601023904-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]AdaShare: Learning What To Share For Efficient Deep Multi-Task Learning](https://cdn.slidesharecdn.com/ss_thumbnails/dl1211-191213002847-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]大規模分散強化学習の難しい問題設定への適用](https://cdn.slidesharecdn.com/ss_thumbnails/drlapplication-180921001838-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets](https://cdn.slidesharecdn.com/ss_thumbnails/20220325okimura-220405024717-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]The Neural Process Family−Neural Processes関連の実装を読んで動かしてみる−](https://cdn.slidesharecdn.com/ss_thumbnails/20190415dlhacks-190422075753-thumbnail.jpg?width=640&height=640&fit=bounds)
















































![[BDD 2025 - Mobile Development] Mobile Engineer and Software Engineer: Are we...](https://cdn.slidesharecdn.com/ss_thumbnails/md-mobileengineerandsoftwareengineerarewestillrelevantsidiqpermana-251127010650-55224ef1-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)








![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)



![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)


![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)