Downloaded 11 times




























![Nested Join - Algorithms
• SELECT * FROM TABLE1, TABLE 2 WHERE
TABLE1.COL1= TABLE2.COL1
36 [Rev. # or date] – HP Restricted
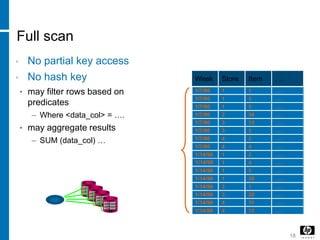
COL1 COL2
1 1
2 2
3 0
4 4
6 6
7 7
COL1 COL2
1 1
3 0
3 1
4 4
5 5
6 6
Join Results
1,1,1,1
3,0,3,0
3,0,3,1
4,4,4,4
6,6,6,6
Table2Table1](https://image.slidesharecdn.com/b32a169f-3c30-4da8-adf1-4fe906ae6521-160612041810/85/DB-36-320.jpg)
![Nested Join - Algorithms
1,1
2,2
3,0
4,4
6,6
7,7
37 [Rev. # or date] – HP Restricted
1,1 3,0 3,1 4,4 5,5 6,6
Table2 (INNER)
Table1(Outer)](https://image.slidesharecdn.com/b32a169f-3c30-4da8-adf1-4fe906ae6521-160612041810/85/DB-37-320.jpg)


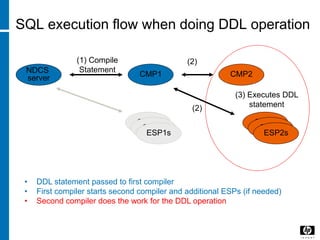
![Merge Join - Algorithms
1,1
2,2
3,0
4,4
6,6
7,7
40 [Rev. # or date] – HP Restricted
1,1 3,0 3,1 4,4 5,5 6,6
Table2 (INNER)
Table1(Outer)
Means
Search Space](https://image.slidesharecdn.com/b32a169f-3c30-4da8-adf1-4fe906ae6521-160612041810/85/DB-40-320.jpg)







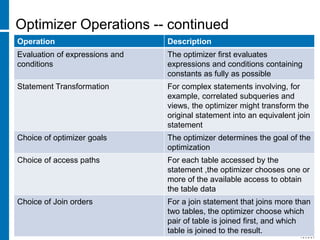
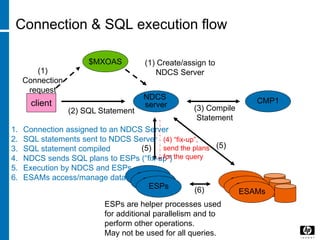
![Skew analysis :Command to check UECs
• SHOWSTATS FOR TABLE ACQ_SHIP_DTL_F ON
EVERY COLUMN
49 [Rev. # or date] – HP Restricted](https://image.slidesharecdn.com/b32a169f-3c30-4da8-adf1-4fe906ae6521-160612041810/85/DB-49-320.jpg)


![How to check Data Skew in HPDM?
52 [Rev. # or date] – HP Restricted](https://image.slidesharecdn.com/b32a169f-3c30-4da8-adf1-4fe906ae6521-160612041810/85/DB-52-320.jpg)

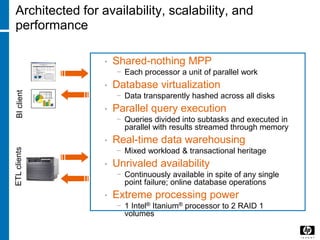
![Common Server Architectures
• SMP: Symmetric Multi-Processor
• NUMA: Non-Uniform Memory Access
• MPP: Massive Parallel Processing
54 [Rev. # or date] – HP Restricted](https://image.slidesharecdn.com/b32a169f-3c30-4da8-adf1-4fe906ae6521-160612041810/85/DB-54-320.jpg)
![SMP
• SHARE
55 [Rev. # or date] – HP Restricted
CPUs
Memory
controller
Memory
Bus
Front Side
Bus](https://image.slidesharecdn.com/b32a169f-3c30-4da8-adf1-4fe906ae6521-160612041810/85/DB-55-320.jpg)
![NUMA
56 [Rev. # or date] – HP Restricted
CPU
I/O
Memory Controller
Local Memory
Controller
Memory
CPU
I/O
Memory Controller
Local Memory
Controller
Memory
I/O
Local Memory
Controller
Memory
CPUMemory Controller
I/O
Local Memory
Controller
Memory
CPUMemory Controller
NUMA
Interconnectio
n Module](https://image.slidesharecdn.com/b32a169f-3c30-4da8-adf1-4fe906ae6521-160612041810/85/DB-56-320.jpg)
![MPP
57 [Rev. # or date] – HP Restricted
CPU
I/O
Memory Controller
Local Memory
Controller
Memory
CPU
I/O
Memory Controller
Local Memory
Controller
Memory
I/O
Local Memory
Controller
Memory
CPUMemory Controller
I/O
Local Memory
Controller
Memory
CPUMemory Controller
MPP
Node Network](https://image.slidesharecdn.com/b32a169f-3c30-4da8-adf1-4fe906ae6521-160612041810/85/DB-57-320.jpg)

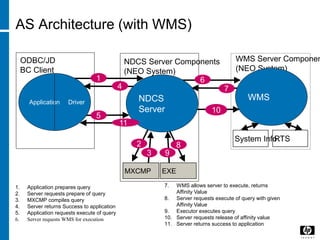
![© 2008 Hewlett-Packard Development Company, L.P.
The information contained herein is subject to change without notice
Neoview Architecture - Software
HP Restricted [edit or delete]](https://image.slidesharecdn.com/b32a169f-3c30-4da8-adf1-4fe906ae6521-160612041810/85/DB-59-320.jpg)











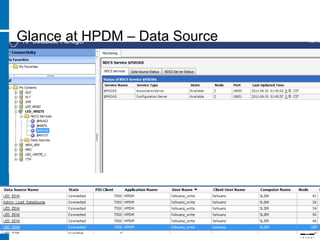
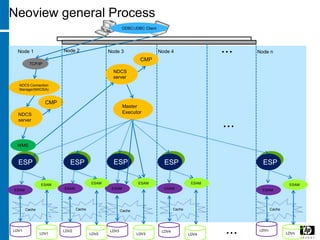
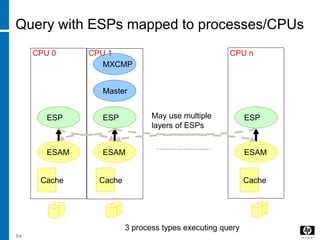
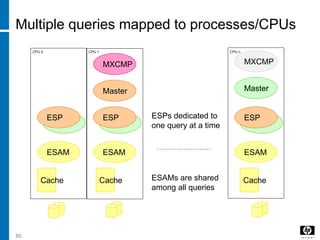
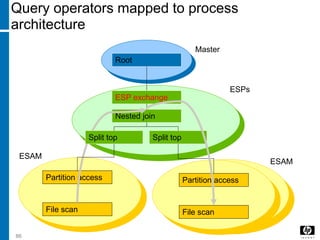
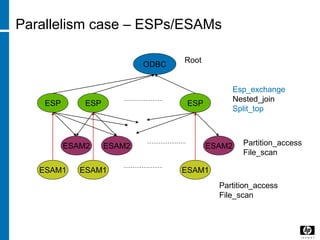

The document discusses various database indexing and joining techniques. It provides details on different types of indexes like B+ tree, bitmap indexes and hash indexes. It also explains different join algorithms like nested loops joins, merge joins and hash joins. It describes how these indexes and joins are used by the query optimizer to generate and select the most efficient execution plan for a given SQL query.














































