Download as PDF, PPTX











![What are we processing?
Run as many queries as possible in parallel on top a denormalized dataframe
Query 1
Query 2
Query 3
Query 1000
ProfileIds field1 field1000 eventsArray
a@a.com a x [e1,2,3]
b@g.com b x [e1]
d@d.com d y [e1,2,3]
z@z.com z y [e1,2,3,5,7]
Interactive Processing!](https://image.slidesharecdn.com/610yeshwanthvijayakumar-200709194046/85/How-Adobe-Does-2-Million-Records-Per-Second-Using-Apache-Spark-19-320.jpg)



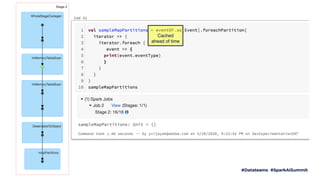
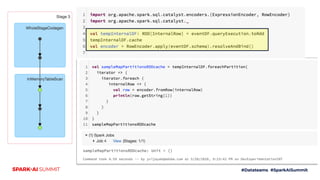





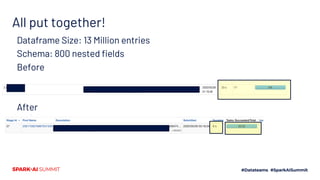







The document outlines Adobe's approach to processing 2 million records per second using Apache Spark, focusing on ingestion techniques, structured streaming optimizations, and query processing strategies. It highlights best practices, including effective caching of physical query plans, managing skew in data, and leveraging Redis for real-time interactions. The content is intended to share insights and strategies that can save time in similar use cases.









































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)













