Downloaded 42 times



















![Example unit
[Unit]
Description=Hello world
After=docker.service
Requires=docker.service
[Service]
TimeoutStartSec=0
ExecStartPre=-/usr/bin/docker rm hello
ExecStartPre=/usr/bin/docker pull busybox
ExecStart=/usr/bin/docker run
--name hello
busybox /bin/sh -c "while true; do echo Hello World; sleep 1; done"
ExecStop=/usr/bin/docker stop hello](https://image.slidesharecdn.com/coreos-150414152046-conversion-gate01/85/CoreOS-or-How-I-Learned-to-Stop-Worrying-and-Love-Systemd-25-320.jpg)

![Example global unit
[Unit]
Description=Hello world
After=docker.service
Requires=docker.service
[Service]
TimeoutStartSec=0
ExecStartPre=-/usr/bin/docker rm hello
ExecStartPre=/usr/bin/docker pull busybox
ExecStart=/usr/bin/docker run --name hello busybox /bin/sh -c "while
true; do echo Hello World; sleep 1; done"
ExecStop=/usr/bin/docker stop hello
[X-Fleet]
MachineMetadata=region=us-east-1
Global=true
Run on all instances with this
fleet metadata](https://image.slidesharecdn.com/coreos-150414152046-conversion-gate01/85/CoreOS-or-How-I-Learned-to-Stop-Worrying-and-Love-Systemd-27-320.jpg)



![Example template unit
[Unit]
Description=Hello world
After=docker.service
Requires=docker.service
[Service]
TimeoutStartSec=0
ExecStartPre=-/usr/bin/docker rm hello
ExecStartPre=/usr/bin/docker pull busybox
ExecStart=/usr/bin/docker run --name hello busybox /bin/sh -c "while
true; do echo Hello World; sleep 1; done"
ExecStop=/usr/bin/docker stop hello
[X-Fleet]
Conflicts=hello@*
Ensure there is only one of these on each instance](https://image.slidesharecdn.com/coreos-150414152046-conversion-gate01/85/CoreOS-or-How-I-Learned-to-Stop-Worrying-and-Love-Systemd-31-320.jpg)





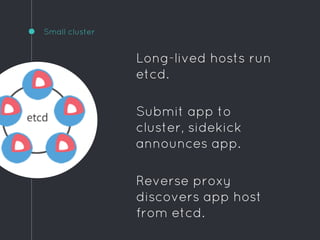


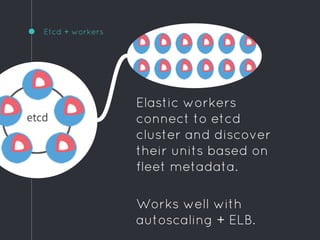







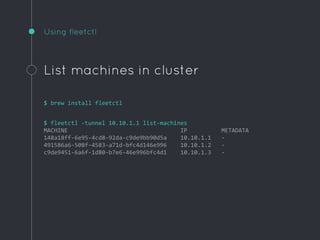
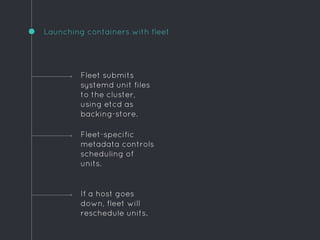
Ric Lister presents patterns for running Docker in production on CoreOS, including a simple homogeneous operations cluster where sidekick units announce services in etcd and a reverse proxy discovers them, an etcd and workers pattern for low-traffic sites behind a load balancer, and an immutable servers pattern without etcd for high-traffic microservices with strict change control. He also discusses logging to ship container output off hosts, various monitoring options, alternative operating systems like RancherOS and Atomic, and scheduler options like Kubernetes, Mesos, and Deis.


































































![[NYC Meetup] Docker at Nuxeo](https://cdn.slidesharecdn.com/ss_thumbnails/dockermeetupnyc-140605110024-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)




















